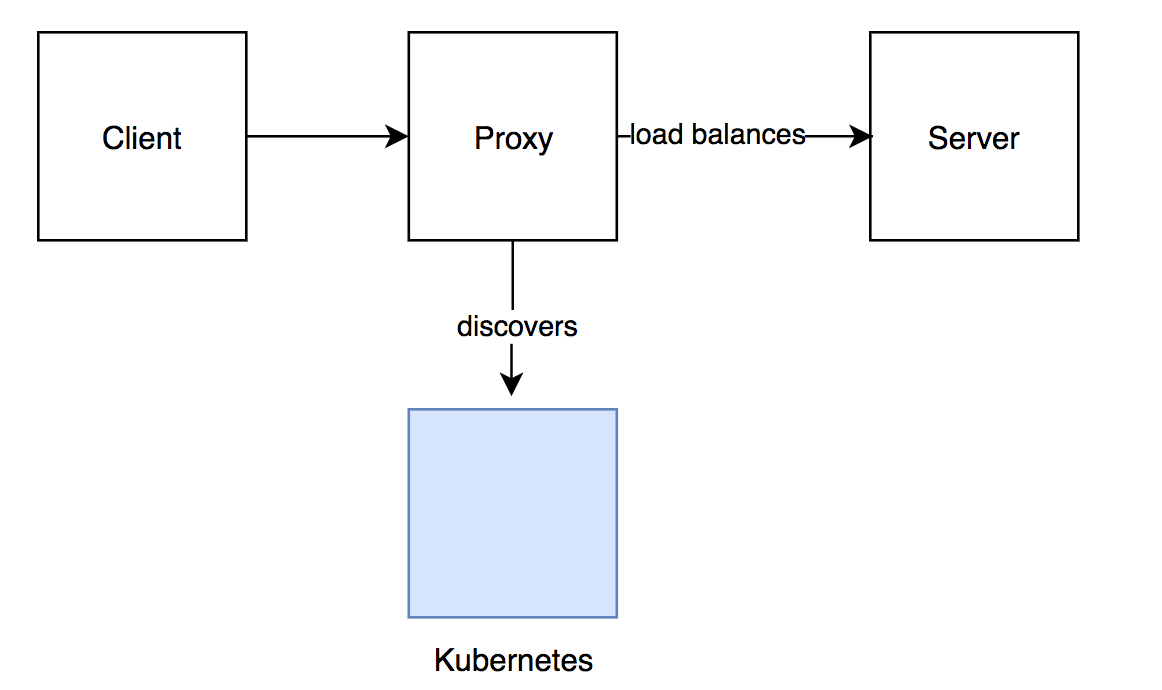
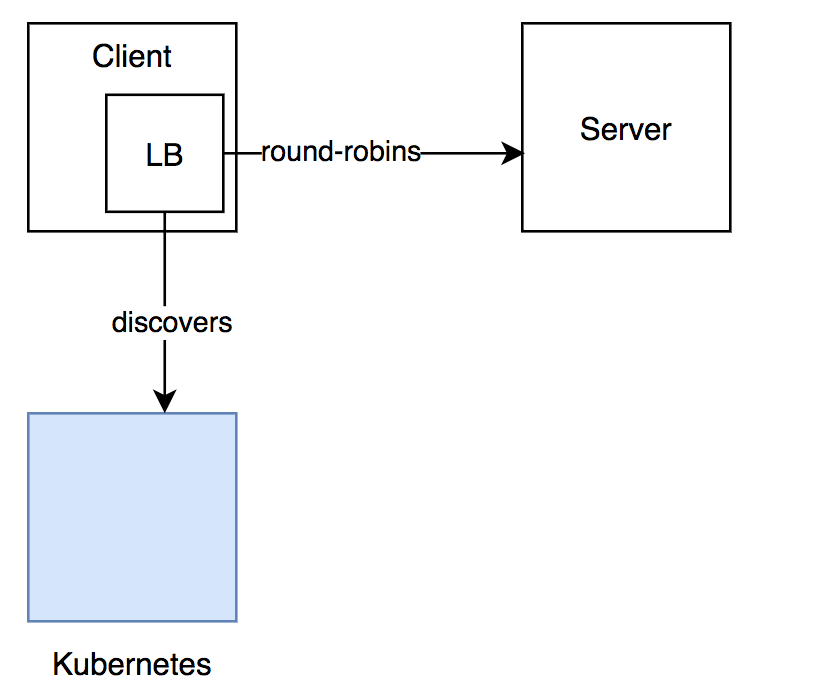
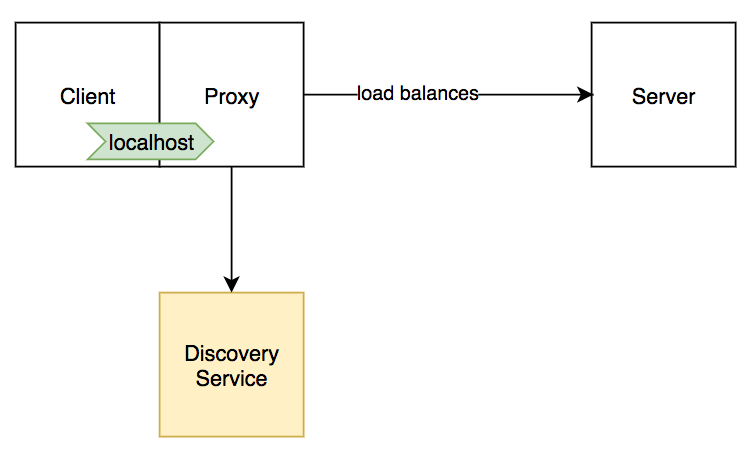
使用 DNS 作为服务发现机制有个潜在的复杂性,即传播需要一定的时间,因此,在一个正在终止的后端服务真正停止接受连接之前,我们需要为 gRPC 客户端留有更新主机列表的余地。因为有一个 TLL 时间与 DNS 记录相关联,也就是说 Envoy 会在这段时间内缓存主机列表,所以使用 DNS 时,优雅关闭流程需要一点技巧
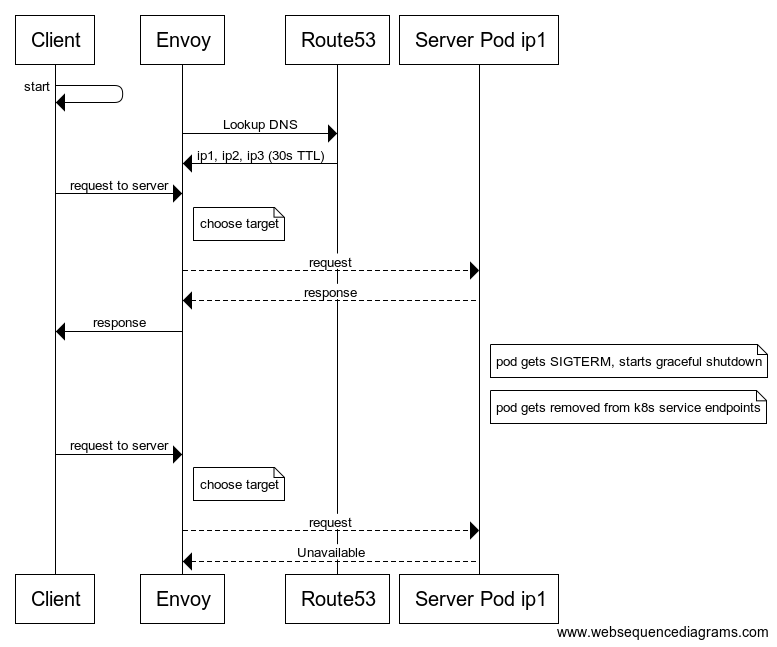
下图展示了一个基本流程,它以一个失败的请求结束:
Figure 4: Terminating host makes request fail due to DNS caching
在这个场景中,因为服务端 pod 不再可用,但 Envoy 缓存依然持有其 IP,所以第二次客户端请求以失败告终。
要解决这个问题,我们有必要看一下 Kubernetes 是如何销毁 pod 的,这篇文章对此有详细的论述。它包含两个同时进行的步骤:在 Kubernetes service endpoints 中移除 pod(在我们的案例中,同时也会移除 DNS 记录列表中该 pod 的 IP) 和 向容器发送 TERM 信号,启动优雅关闭。
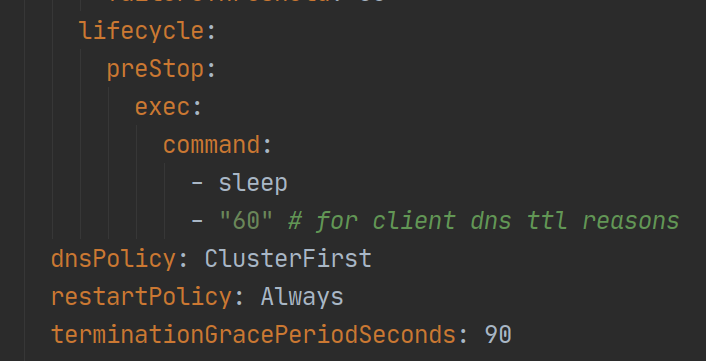
有鉴于此,我们使用 Kubernetes 的 pre-stop 钩子来阻止 TERM 信号的立即发送:
Figure 5: preStop hook
配置好 preStop 钩子之后,我们的流程就变成下面这样:
Figure 6: successful server pod shutdown flow
通过这种解决方式,我们为 Envoy 的 DNS 缓存留出足够的时间,使其过期并且重新刷新,从而剔除已经死亡的 pod IP。
未来改进
尽管 Envoy 为我们带来了性能提升和整体的简洁,但是基于 DNS 的服务发现依旧不是很理想。因为它是基于轮询的,在 TTL 过期之后,由客户端负责刷新主机池,所以不够健壮。
/* * context_switch - switch to the new MM and the new thread's register state. */ static __always_inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next, struct rq_flags *rf) { prepare_task_switch(rq, prev, next); arch_start_context_switch(prev);
if (!next->mm) { // to kernel enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm; if (prev->mm) // from user mmgrab(prev->active_mm); else prev->active_mm = NULL; } else { // to user membarrier_switch_mm(rq, prev->active_mm, next->mm); switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel /* will mmdrop() in finish_task_switch(). */ rq->prev_mm = prev->active_mm; prev->active_mm = NULL; } }
/* * %rdi: prev task * %rsi: next task */ .pushsection .text, "ax" SYM_FUNC_START(__switch_to_asm) /* * Save callee-saved registers * This must match the order in inactive_task_frame */ pushq %rbp pushq %rbx pushq %r12 pushq %r13 pushq %r14 pushq %r15
#ifdef CONFIG_RETPOLINE /* * When switching from a shallower to a deeper call stack * the RSB may either underflow or use entries populated * with userspace addresses. On CPUs where those concerns * exist, overwrite the RSB with entries which capture * speculative execution to prevent attack. */ FILL_RETURN_BUFFER %r12, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW #endif
#define switch_to(prev, next, last) \ do { \ ((last) = __switch_to_asm((prev), (next))); \ } while (0)
栈帧一层层解开,会返回到 context_switch 函数调用,继而回到schedule()。可见,任何一个进入内核态调用schedule()执行任务切换的进程,最终都会等到schedule()调用的返回。我们稍后会讲到 Go 运行时的协程调度,其schedule函数是不会返回的,所以它看起来并不像一个函数,这是区别于操作系统调度函数一个重要的点。
/* The userland implementation is: int clone (int (*fn)(void *arg), void *child_stack, int flags, void *arg), the kernel entry is: int clone (long flags, void *child_stack). The parameters are passed in register and on the stack from userland: rdi: fn rsi: child_stack rdx: flags rcx: arg r8d: TID field in parent r9d: thread pointer %esp+8: TID field in child The kernel expects: rax: system call number rdi: flags rsi: child_stack rdx: TID field in parent r10: TID field in child r8: thread pointer */
.text ENTRY (__clone) /* Sanity check arguments. */ movq $-EINVAL,%rax testq %rdi,%rdi /* no NULL function pointers */ jz SYSCALL_ERROR_LABEL testq %rsi,%rsi /* no NULL stack pointers */ jz SYSCALL_ERROR_LABEL
/* Insert the argument onto the new stack. */ subq $16,%rsi movq %rcx,8(%rsi)
/* Save the function pointer. It will be popped off in the child in the ebx frobbing below. 这里把线程要运行的函数fn压入新建线程的用户态堆栈中*/ movq %rdi,0(%rsi)
/* Do the system call. */ movq %rdx, %rdi movq %r8, %rdx movq %r9, %r8 mov 8(%rsp), %R10_LP movl $SYS_ify(clone),%eax
/* End FDE now, because in the child the unwind info will be wrong. */ cfi_endproc; syscall
L(thread_start): cfi_startproc; /* Clearing frame pointer is insufficient, use CFI. */ cfi_undefined (rip); /* Clear the frame pointer. The ABI suggests this be done, to mark the outermost frame obviously. */ xorl %ebp, %ebp
/* Set up arguments for the function call. */ popq %rax /* Function to call. 弹出函数地址 */ popq %rdi /* Argument. */ call *%rax /* 开始调用执行 */ /* Call exit with return value from function call. */ movq %rax, %rdi movl $SYS_ify(exit), %eax syscall cfi_endproc;
对高并发的执着追求,诞生了编程语言世界里五花八门的协程,或者说用户态线程,概念并不重要,重要的是,它们只能在用户态做文章。像Python、Java、C++、Go、Rust 等语言都提供了基于协程的并发模型,这里面由于 Go 是相对比较新生的语言,没有任何历史包袱,从而提供了完美的用户态线程,且将此并发模型内置于语言自身。这样做的好处是,开发并发程序变得异常简单,一个简简单单的go关键字就可以创建一个独立的任务,即一个独立的执行流,如果换做其它语言,想要创建一个独立的执行流只有线程或者进程这种由操作系统提供的原生方式(当然,很多语言也有对应的协程库,因本人未做过详细研究,故只考虑原生的并发模型);然而,为了并发体系的自洽,Go 为其用户屏蔽了操作系统提供的线程模型,虽然用起来简单了,但理解上却多了些许障碍。
不知道你是否被上面的用户线程、内核线程、映射等概念搅的一头雾水呢?按照其语义,用户线程和内核线程就像是对立的两方,会有某个东西将它们联系起来构成“映射”,或许是内核,又或许是C库,但书中没讲,我能够理解《操作系统概念》是讲操作系统的设计与实现原理,会兼顾大部分操作系统,讲解的也是较为抽象的部分,不过现代绝大部分人只接触过Linux,而Linux内核提供的并发模型就只有一对一这一种,所里书里的内容如今看上去多少有些不合时宜。在 Linux 内核当中甚至并不区分进程和线程,它们统一都由task_struct这一种数据结构表示,并且基于其进行调度,也就是说,在内核看来每个task_struct只有一个执行流,至于在用户态这个大的执行流干些什么,内核并不关心。
要正确理解书中所表达的意图,就需要先把概念捋清楚,我以 Linux 为例来进行说明。
首先,需要把这里的内核线程拿掉,换成操作系统线程,即 Linux 内核提供的线程。我之所以不用内核线程是因为内核线程这个概念在 Linux 中也有对应的存在(参见《深入linux内核架构》2.4.2 内核线程),内核线程是一种只运行在内核地址空间的线程。所有的内核线程共享内核地址空间(对于 32 位系统来说,就是 3-4GB 的虚拟地址空间),所以也共享同一份内核页表,并且没有用户地址空间,这也是为什么叫内核线程,而不叫内核进程的原因。
或许,我们可以换个角度,抛开这些定义,站在 CPU 的角度去理解问题。所谓线程就是内核维护的一个数据结构,内核依靠这个结构来控制 CPU 上运行的代码,指令无论在用户态还是内核态,都是这个线程,所有的资源消耗都计入此线程,即便是与此线程无关的中断所消耗的资源也被记在该线程名下。协程就是用户空间代码维护的一个数据结构,用户空间代码可以通过控制 ip、sp 等寄存器来控制用户空间执行流的走向,就可以实现在不同的协程间切换,并把执行流的状态记录在对应的数据结构上,重要的是协程代码本身就属于操作系统用户态执行流中的指令。
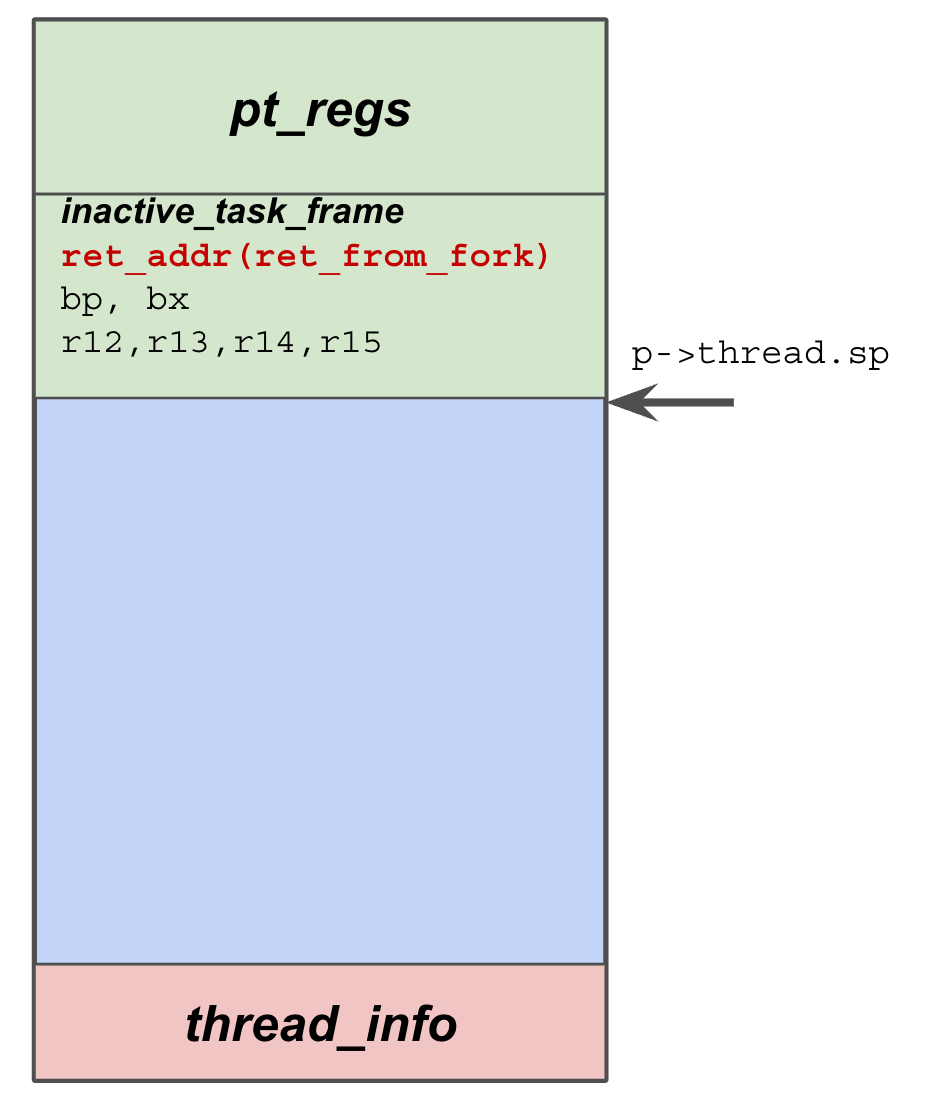
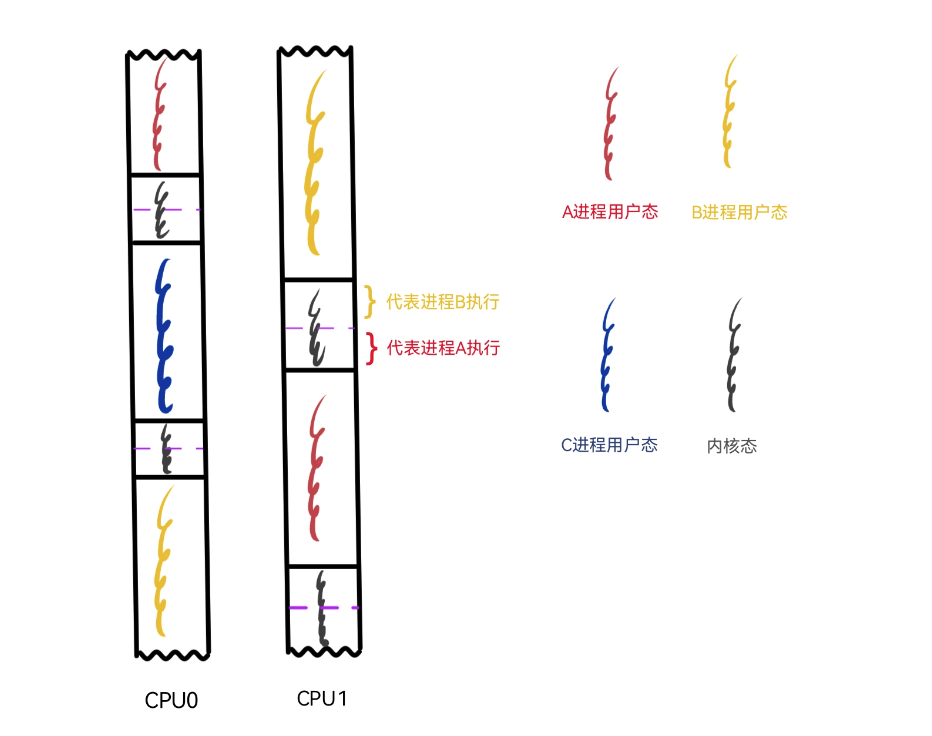
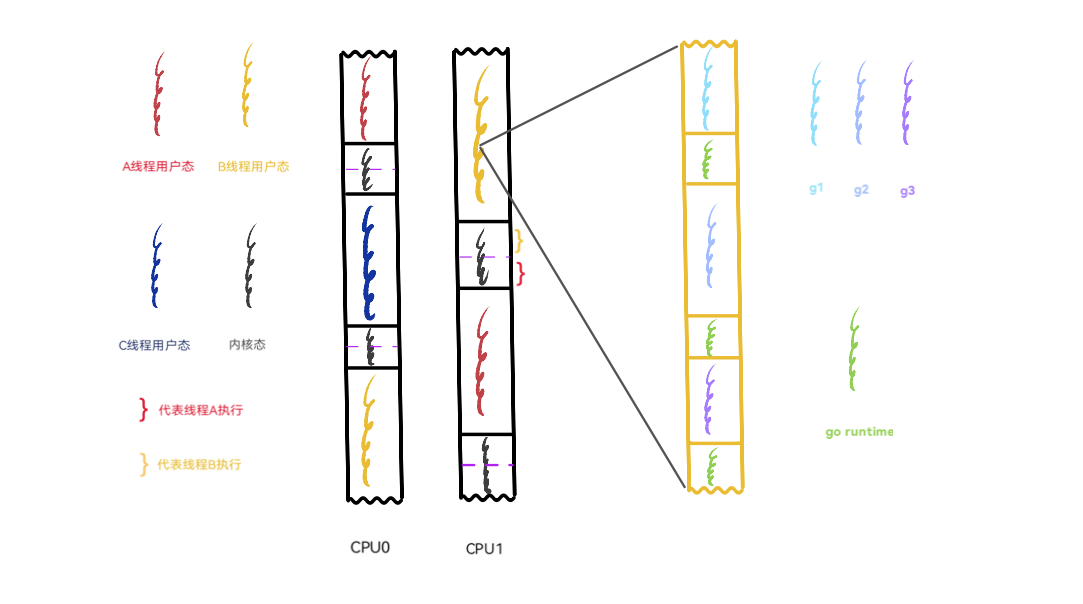
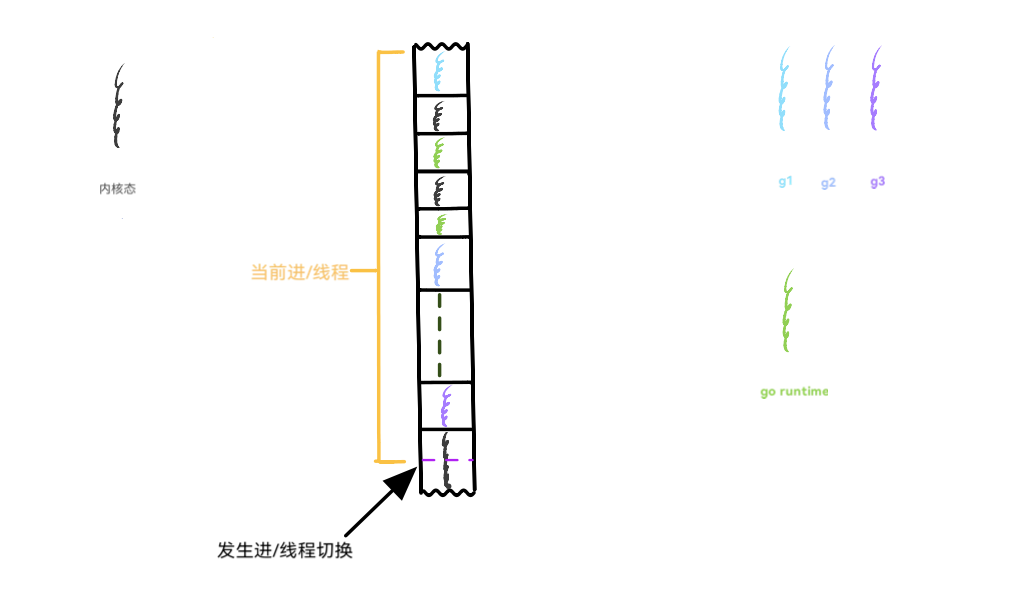
仍然以前面展示进程切换时的图作为基础,为了配合 Go 的实际情况,将图中的进程换成线程来讲。现在想象一下,线程 A、B、C 是 go 程序底层的操作系统线程(GMP中的M),g1、g2、g3 为 go 程序在用户空间实现的协程,或者说叫 goroutine。值得注意的是,内核并不知道 goroutine 的存在,它仍然按照自己一贯的行为方式对 A、B、C 三个线程进行调度。
当A线程的时间片用完,或者发出阻塞的系统调用时,就会被内核调度出 CPU,继而把 C 线程调度到 CPU 上来执行。图中显示 A线程被换下 CPU0 的时候,B 线程仍然在 CPU1 上,这意味着其余的 goroutine 依然会得到执行的机会。再看被调度到 CPU0 上的 C 线程,它也是 go 程序底层的线程,这意味着在一个拥有双核的机器上,goroutine 总是有机会运行的,即便有些 goroutine 因为系统调用等某些原因导致其所在的操作系统线程被换下。go 总会保证有两个“活的”的线程一直待在 CPU 上轮番寻找 goroutine 来执行,除非操作系统内核看不下去,换其它的程序线程来执行,但 go 总会保证有两个准备好的线程可以随时被内核调度。
再来切一下近景,把 B 线程放大。在内核看来,黄色部分只代表 B 线程的用户态执行流,但就在这个黄色用户态执行流的内部正在轮番上演形形色色的任务,g1、g2、g3 三个 goroutine 正轮流在CPU上执行,绿色执行流代表 go 的 runtime,正是 runtime 居中调度,指挥得当,才让以 goroutine 为单位的任务都获得执行的机会。内核对这些一无所知,CPU也只会觉得奇怪:这个线程的用户态代码怎么老是频繁的切换堆栈?(见《溯源 goroutine 堆栈》 中对 go 协程堆栈的描述)
这种并发模型的优势显而易见,让我们来直观地感受一下。操作系统线程每次上下文切换需要大约 1000ns 的时间,而硬件有望在每纳秒的时间里执行 12 条指令,也就是说,当任务必须等待时,操作系统就会花费 12k 条指令去做线程切换,却不能将这些指令用在有意义的业务上。而 go 在用户态进行协程切换,极大地缓和了这种浪费,go 进行一次协程切换大概需要 200ns 或者 2.4k 条指令。简言之,go 用尽可能少的 os 级的线程调度来做更多的事情,方式就是在用户空间调度,这是语言级别的一种能力,可不严谨的说,go 的调度比 os 级调度便宜 5 倍,甚至更多!
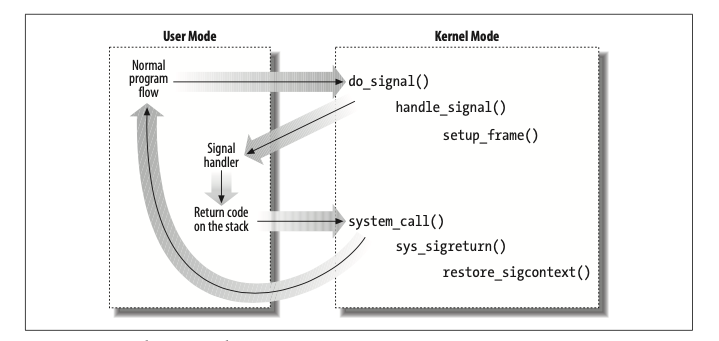
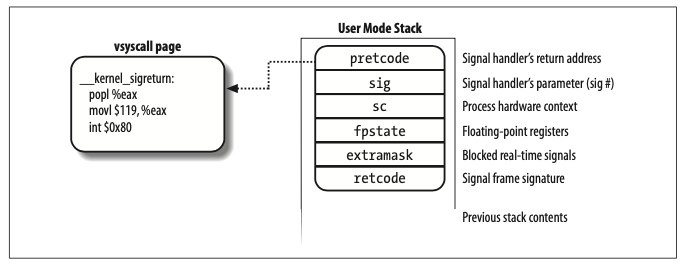
PT_REGS_SP(regs) = (unsignedlong) frame; PT_REGS_DI(regs) = sig; /* In case the signal handler was declared without prototypes */ PT_REGS_AX(regs) = 0; /* * This also works for non SA_SIGINFO handlers because they expect the * next argument after the signal number on the stack. */ PT_REGS_SI(regs) = (unsignedlong) &frame->info; PT_REGS_DX(regs) = (unsignedlong) &frame->uc; PT_REGS_IP(regs) = (unsignedlong) ksig->ka.sa.sa_handler;
除了设置堆栈、程序计数器之外也设置了 rdi、rsi、rds 这几个寄存器,这是 x86_64 架构下 C 语言的函数调惯例,三个寄存器分别用于存放函数调用时前三个参数。记住这一点,后面介绍 Go 时会用到。
// Called using C ABI. TEXT runtime·sigtramp(SB),NOSPLIT,$0 // Transition from C ABI to Go ABI. PUSH_REGS_HOST_TO_ABI0()
// Call into the Go signal handler NOP SP // disable vet stack checking ADJSP $24 MOVQ DI, 0(SP) // sig MOVQ SI, 8(SP) // info MOVQ DX, 16(SP) // ctx CALL ·sigtrampgo(SB) ADJSP $-24
POP_REGS_HOST_TO_ABI0() RET
sigtramp实际上是真正的信号处理函数,进程从内核态收到信号回到用户态调用的处理函数就是它,注释中表明这个函数以 C 语言的调用惯例被调用,Go 在这里通过PUSH_REGS_HOST_TO_ABI0保存 go 自己调用惯例用的寄存器后,转换成自己的调用规范,等函数调用完毕之后,再通过POP_REGS_HOST_TO_ABI0恢复这些寄存器的值。
还记得上一节介绍 5.10版本的内核修改用户态寄存器时设置的 rdi、rsi、rdx 的值吗?这三个寄存器的值就是内核模仿调用sigtramp时传入的参数,现在 go 需要以自己的调用规约将其放置到堆栈上,来表示 sig、info、ctx 这三个参数(go1.17 改变了调用规约,已经由堆栈传递参数改为寄存器传递了,不知道为何此处仍然使用堆栈传递,我此处引用的代码是版本 1.18.1)。
// doSigPreempt handles a preemption signal on gp. funcdoSigPreempt(gp *g, ctxt *sigctxt) { // Check if this G wants to be preempted and is safe to // preempt. if wantAsyncPreempt(gp) { if ok, newpc := isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()); ok { // Adjust the PC and inject a call to asyncPreempt. ctxt.pushCall(abi.FuncPCABI0(asyncPreempt), newpc) } }
// Acknowledge the preemption. atomic.Xadd(&gp.m.preemptGen, 1) atomic.Store(&gp.m.signalPending, 0)
信号处理程序一旦被执行,舞台就交到了 go runtime 手里,ctxt的类型为*sigctxt,指向的是用户态堆栈中存放内核态堆栈内容的地址。然后信号处理程序通过isAsyncSafePoint来判断抢占位置是否安全,并返回安全的抢占地址。如果确认抢占没有问题,接着会调用pushCall方法来修改ctxt中的用户态硬件上下文,用于稍后再一次从内核态返回用户态时模拟出一个用户态程序调用asyncPreempt的假象:
1 2 3 4 5 6 7 8
func(c *sigctxt) pushCall(targetPC, resumePC uintptr) { // Make it look like we called target at resumePC. sp := uintptr(c.rsp()) sp -= goarch.PtrSize *(*uintptr)(unsafe.Pointer(sp)) = resumePC c.set_rsp(uint64(sp)) c.set_rip(uint64(targetPC)) }
TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0 PUSHQ BP MOVQ SP, BP // Save flags before clobbering them PUSHFQ // obj doesn't understand ADD/SUB on SP, but does understand ADJSP ADJSP $368 // But vet doesn't know ADJSP, so suppress vet stack checking NOP SP MOVQ AX, 0(SP) ...... MOVUPS X15, 352(SP) CALL ·asyncPreempt2(SB) MOVUPS 352(SP), X15 MOVUPS 336(SP), X14 ...... ADJSP $-368 POPFQ POPQ BP RET
// func mcall(fn func(*g)) // Switch to m->g0's stack, call fn(g). // Fn must never return. It should gogo(&g->sched) // to keep running g. TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8 MOVQ AX, DX // DX = fn
// save state in g->sched MOVQ 0(SP), BX // caller's PC MOVQ BX, (g_sched+gobuf_pc)(R14) LEAQ fn+0(FP), BX // caller's SP MOVQ BX, (g_sched+gobuf_sp)(R14) MOVQ BP, (g_sched+gobuf_bp)(R14)
// switch to m->g0 & its stack, call fn MOVQ g_m(R14), BX MOVQ m_g0(BX), SI // SI = g.m.g0 CMPQ SI, R14 // if g == m->g0 call badmcall JNE goodm JMP runtime·badmcall(SB) goodm: MOVQ R14, AX // AX (and arg 0) = g MOVQ SI, R14 // g = g.m.g0 get_tls(CX) // Set G in TLS MOVQ R14, g(CX) MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp PUSHQ AX // open up space for fn's arg spill slot MOVQ 0(DX), R12 CALL R12 // fn(g) POPQ AX JMP runtime·badmcall2(SB) RET
这两句是保存程序计数器的值到g->sched:
1 2
MOVQ 0(SP), BX // caller's PC MOVQ BX, (g_sched+gobuf_pc)(R14)
由此观之,asyncPreempt更像是 Linux 内核中的schedule():调度发生在函数执行过程中,而函数执行完毕要等到下一次被调度的时候才会发生。 而 go 借助信号机制所实现的抢占,无非就是依靠信号处理程序这一次控制权埋点,以便在执行流最终从内核态返回时执行asyncPreempt代码,从而再一次收获 CPU 的控制权。
是时候再从指令的视角在宏观上来理解 go 的信号抢占流程了:
图 8-1 显示了通过异步抢占执行流从 g1 切换到 g2 的过程:
g1被时钟中断,从内核返回时发现有抢占信号。
执行流从内核态返回到用户态,执行信号处理程序(第一个绿色的 go runtime 执行流)。
信号处理程序执行完毕返回内核,内核做一些恢复后,再次返回到用户态。
从内核态返回后的执行流被 go runtime 窃取,转而执行调度(第二个绿色的 go runtime 执行流)。
g2 被选择,换上 CPU 执行。
9
文章写到这里,基本上把我想讲的已经讲完了,也算基本上完成了自己“观其大略,本其脉络”的目标,我曾在《从CPU的视角说起》 一文中说道:我目前所寻求的信息,意在建立计算机系统的世界观与 Go 语言的世界观,是在陷入具体细节之前为自己提供一个大致的轮廓,让自己对计算机运行的脉络有一个关键性的认识。 即便如此,里面也不可避免的出现很多具体而微的内容。我略过了很多环节,并不是因为它们不重要,是因为它们是细节,是更丰富的东西,也是我尚未探索的东西。
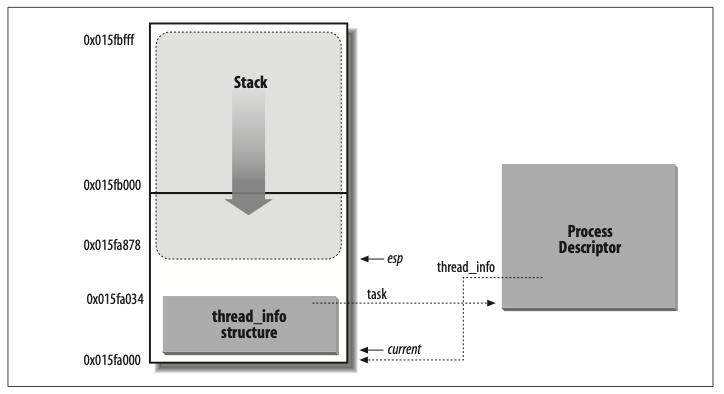
我们在上一篇讨论了进线程的堆栈,现在继续探索 go 中的协程栈。如果吊一下书袋的话,口称 go 协程是不严谨的,go 的协程不同于其他语言的协程,go 的协程是一种有栈协程,每一个协程都有自己的协程堆栈,因此 go 官网发明了一个新词 goroutine,以区别于普通的 coroutine。我们接下来就聊聊 goroutine 的堆栈。在此之前,先来回顾一下上一篇中对进线程堆栈位置的总结。
go 重写了运行时,如果不使用 cgo 的话,编译完成的 go 程序是静态链接的,不依赖任何C库,这使它拥有不错的可移植性,在较新内核上编译好的程序,拉到旧版本内核的操作系统上依然能够运行。在这一点上,rust 并没有多少优势,反而新生语言 hare 表现足够强劲。
不依赖 C 库,意味着 go 对 heap 的管理有自己的方式。 那么, go 管理的 heap 是否与之前内存空间布局图中的 heap 位置相同就要打一个大大的问号了。要搞清楚这个问题,我们需要到 runtime 的源码中一探究竟,且要挖到 go 与内核的接口处,找出其申请内存的方式方可。
本文并不打算分析 go 的内存分配器,也不打算介绍堆栈的分配算法,仅仅为了解决 goroutine 堆栈在虚拟地址空间中位置的疑惑。想了解内存管理和堆栈分配算法的读者可以参考详解Go中内存分配源码实现与一文教你搞懂 Go 中栈操作。
先从普通 goroutine 的创建开始吧!
在 go 中,每通过go func(){}的方式开启一个 goroutine 时,编译器都会将其转换成对 runtime.newproc的调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Create a new g running fn. // Put it on the queue of g's waiting to run. // The compiler turns a go statement into a call to this. funcnewproc(fn *funcval) { gp := getg() pc := getcallerpc() // 切换到线程堆栈创建 g systemstack(func() { newg := newproc1(fn, gp, pc)
_p_ := getg().m.p.ptr() runqput(_p_, newg, true)
if mainStarted { wakep() } }) }
newproc 仅仅是对 newproc1 的包装,创建新 g 的动作不能在用户堆栈上进行,所以这里切换到底层线程的堆栈来执行。
// Create a new g in state _Grunnable, starting at fn. callerpc is the // address of the go statement that created this. The caller is responsible // for adding the new g to the scheduler. funcnewproc1(fn *funcval, callergp *g, callerpc uintptr) *g { _g_ := getg()
if fn == nil { _g_.m.throwing = -1// do not dump full stacks throw("go of nil func value") } acquirem() // disable preemption because it can be holding p in a local var
_p_ := _g_.m.p.ptr() // 从 P 的空闲链表中获取一个新的 G newg := gfget(_p_) // 获取不到则调用 malg 进行创建 if newg == nil { newg = malg(_StackMin) casgstatus(newg, _Gidle, _Gdead) allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. } ...... }
newproc1 方法很长,里面主要是获取 G ,然后对获取到的 G 做一些初始化的工作。当创建 G 时,会先从缓存的空闲链表中获取,如果没有空闲的 G ,再进行创建。所以,我们这里只看 malg 函数的调用。
// Allocate a new g, with a stack big enough for stacksize bytes. funcmalg(stacksize int32) *g { newg := new(g) if stacksize >= 0 { stacksize = round2(_StackSystem + stacksize) systemstack(func() { newg.stack = stackalloc(uint32(stacksize)) }) newg.stackguard0 = newg.stack.lo + _StackGuard newg.stackguard1 = ^uintptr(0) // Clear the bottom word of the stack. We record g // there on gsignal stack during VDSO on ARM and ARM64. *(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 } return newg }
malg 会创建新的 G 并为其设置好堆栈,以及堆栈的边界,以供日后扩容使用。这里重点看 stackalloc 函数,堆栈的内存的分配就是由它来完成的,函数的返回值赋给新 G 的 stack 字段。
G 的 stack 字段是一个 stack 结构体类型,里面标记了堆栈的高地址和低地址:
1 2 3 4 5 6 7
// Stack describes a Go execution stack. // The bounds of the stack are exactly [lo, hi), // with no implicit data structures on either side. type stack struct { lo uintptr hi uintptr }
我们接着看这个 stack 是怎么创建出来的。
stackalloc 的函数比较长,里面涉及到大堆栈和小堆栈的分配逻辑,这里就不贴大段的代码了。这个函数不管是从 cache 还是 pool 中获取内存,最终都会在内存不够时调用 mheap 的allocManual函数去分配新的内存:
// Try to add at least npage pages of memory to the heap, // returning how much the heap grew by and whether it worked. func(h *mheap) grow(npage uintptr) (uintptr, bool) { assertLockHeld(&h.lock) ask := alignUp(npage, pallocChunkPages) * pageSize totalGrowth := uintptr(0) // This may overflow because ask could be very large // and is otherwise unrelated to h.curArena.base. // curArena 无需初始化,但问题是怎么判断 Arena 边界呢 end := h.curArena.base + ask nBase := alignUp(end, physPageSize) if nBase > h.curArena.end || /* overflow */ end < h.curArena.base { // 尝试分配新的 Arena,但有可能跨越 hint 区域,所以全额申请 // Not enough room in the current arena. Allocate more // arena space. This may not be contiguous with the // current arena, so we have to request the full ask. av, asize := h.sysAlloc(ask) // 此时已经将需要的内存 reserve 了 if av == nil { print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n") return0, false }
ifuintptr(av) == h.curArena.end { // 说明是连续的,拓展此 curArena 的边界 // The new space is contiguous with the old // space, so just extend the current space. h.curArena.end = uintptr(av) + asize } else { // 感觉像是这一次不够分配的,但也别浪费,把剩余的内存标记为已使用,加入到一个地方以供分配 // The new space is discontiguous. Track what // remains of the current space and switch to // the new space. This should be rare. if size := h.curArena.end - h.curArena.base; size != 0 { // Transition this space from Reserved to Prepared and mark it // as released since we'll be able to start using it after updating // the page allocator and releasing the lock at any time. sysMap(unsafe.Pointer(h.curArena.base), size, &memstats.heap_sys) // Update stats. atomic.Xadd64(&memstats.heap_released, int64(size)) stats := memstats.heapStats.acquire() atomic.Xaddint64(&stats.releagrowsed, int64(size)) memstats.heapStats.release() // Update the page allocator's structures to make this // space ready for allocation. h.pages.grow(h.curArena.base, size) totalGrowth += size } // Switch to the new space. // 把 curArena 切换到新的地址 h.curArena.base = uintptr(av) h.curArena.end = uintptr(av) + asize }
// Recalculate nBase. // We know this won't overflow, because sysAlloc returned // a valid region starting at h.curArena.base which is at // least ask bytes in size. nBase = alignUp(h.curArena.base+ask, physPageSize) }
// 更新 base // Grow into the current arena. v := h.curArena.base h.curArena.base = nBase
// 把分配的那块内存标记为 Prepared // Transition the space we're going to use from Reserved to Prepared. sysMap(unsafe.Pointer(v), nBase-v, &memstats.heap_sys)
// ...... 省略部分代码
// Update the page allocator's structures to make this // space ready for allocation. h.pages.grow(v, nBase-v) totalGrowth += nBase - v return totalGrowth, true }
func(h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) { assertLockHeld(&h.lock)
n = alignUp(n, heapArenaBytes)
// First, try the arena pre-reservation. v = h.arena.alloc(n, heapArenaBytes, &memstats.heap_sys) if v != nil { size = n goto mapped }
// Try to grow the heap at a hint address. for h.arenaHints != nil { hint := h.arenaHints p := hint.addr if hint.down { p -= n } if p+n < p { // We can't use this, so don't ask. v = nil } elseif arenaIndex(p+n-1) >= 1<<arenaBits { // Outside addressable heap. Can't use. v = nil } else { v = sysReserve(unsafe.Pointer(p), n) } // 如果不相等,则说明 mmap 在建议的地址上没能分配成功 if p == uintptr(v) { // Success. Update the hint. if !hint.down { p += n } // 成功后,hint 的地址也跟着更新 hint.addr = p size = n break } // 此时,丢弃这次分配的内存,尝试下一个 arenaHints, 也就是下一个 1T 区间 // Failed. Discard this hint and try the next. // // TODO: This would be cleaner if sysReserve could be // told to only return the requested address. In // particular, this is already how Windows behaves, so // it would simplify things there. if v != nil { sysFree(v, n, nil) } h.arenaHints = hint.next h.arenaHintAlloc.free(unsafe.Pointer(hint)) }
if size == 0 { if raceenabled { // The race detector assumes the heap lives in // [0x00c000000000, 0x00e000000000), but we // just ran out of hints in this region. Give // a nice failure. throw("too many address space collisions for -race mode") }
// All of the hints failed, so we'll take any // (sufficiently aligned) address the kernel will give // us. // 所有的 hint 都失败了,然后让内核自动分配一个定量内存 v, size = sysReserveAligned(nil, n, heapArenaBytes) if v == nil { returnnil, 0 }
// Create new hints for extending this region. hint := (*arenaHint)(h.arenaHintAlloc.alloc()) hint.addr, hint.down = uintptr(v), true hint.next, mheap_.arenaHints = mheap_.arenaHints, hint hint = (*arenaHint)(h.arenaHintAlloc.alloc()) hint.addr = uintptr(v) + size hint.next, mheap_.arenaHints = mheap_.arenaHints, hint } // ......省略大段代码 return }
这里真正申请内存的操作是 sysReserve,让我们来一睹究竟:
1 2 3 4 5 6 7
funcsysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer { p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0) if err != 0 { returnnil } return p }
// sysMmap calls the mmap system call. It is implemented in assembly. funcsysMmap(addr unsafe.Pointer, n uintptr, prot, flags, fd int32, off uint32) (p unsafe.Pointer, err int)
mmap调用中的 flag _PROT_NONE, _MAP_ANON|_MAP_PRIVATE表示申请的内存块是无文件背景的匿名映射,这里在调用时传入了一个提示地址,用于告知内核尽量从要求的地址开始分配。
// 如果不相等,则说明 mmap 在建议的地址上没能分配成功 if p == uintptr(v) { // Success. Update the hint. if !hint.down { p += n } // 成功后,hint 的地址也跟着更新 hint.addr = p size = n break } // 此时,丢弃这次分配的内存,尝试下一个 arenaHints, 也就是下一个 1T 区间 // Failed. Discard this hint and try the next. // // TODO: This would be cleaner if sysReserve could be // told to only return the requested address. In // particular, this is already how Windows behaves, so // it would simplify things there. if v != nil { sysFree(v, n, nil) } h.arenaHints = hint.next h.arenaHintAlloc.free(unsafe.Pointer(hint))
// 只看 64 位系统的初始化部分 // Create initial arena growth hints. if goarch.PtrSize == 8 { // On a 64-bit machine, we pick the following hints // because: // // 1. Starting from the middle of the address space // makes it easier to grow out a contiguous range // without running in to some other mapping. // // 2. This makes Go heap addresses more easily // recognizable when debugging. // // 3. Stack scanning in gccgo is still conservative, // so it's important that addresses be distinguishable // from other data. // // Starting at 0x00c0 means that the valid memory addresses // will begin 0x00c0, 0x00c1, ... // In little-endian, that's c0 00, c1 00, ... None of those are valid // UTF-8 sequences, and they are otherwise as far away from // ff (likely a common byte) as possible. If that fails, we try other 0xXXc0 // addresses. An earlier attempt to use 0x11f8 caused out of memory errors // on OS X during thread allocations. 0x00c0 causes conflicts with // AddressSanitizer which reserves all memory up to 0x0100. // These choices reduce the odds of a conservative garbage collector // not collecting memory because some non-pointer block of memory // had a bit pattern that matched a memory address. // // However, on arm64, we ignore all this advice above and slam the // allocation at 0x40 << 32 because when using 4k pages with 3-level // translation buffers, the user address space is limited to 39 bits // On ios/arm64, the address space is even smaller. // // On AIX, mmaps starts at 0x0A00000000000000 for 64-bit. // processes. for i := 0x7f; i >= 0; i-- { var p uintptr switch { case raceenabled: // The TSAN runtime requires the heap // to be in the range [0x00c000000000, // 0x00e000000000). p = uintptr(i)<<32 | uintptrMask&(0x00c0<<32) if p >= uintptrMask&0x00e000000000 { continue } case GOARCH == "arm64" && GOOS == "ios": p = uintptr(i)<<40 | uintptrMask&(0x0013<<28) case GOARCH == "arm64": p = uintptr(i)<<40 | uintptrMask&(0x0040<<32) case GOOS == "aix": if i == 0 { // We don't use addresses directly after 0x0A00000000000000 // to avoid collisions with others mmaps done by non-go programs. continue } p = uintptr(i)<<40 | uintptrMask&(0xa0<<52) default: p = uintptr(i)<<40 | uintptrMask&(0x00c0<<32) } hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc()) hint.addr = p hint.next, mheap_.arenaHints = mheap_.arenaHints, hint } } }
// Try to grow the heap at a hint address. for h.arenaHints != nil { hint := h.arenaHints p := hint.addr if hint.down { p -= n } if p+n < p { // We can't use this, so don't ask. v = nil } elseif arenaIndex(p+n-1) >= 1<<arenaBits { // Outside addressable heap. Can't use. v = nil } else { v = sysReserve(unsafe.Pointer(p), n) } // 如果不相等,则说明 mmap 在建议的地址上没能分配成功 if p == uintptr(v) { // Success. Update the hint. if !hint.down { p += n } // 成功后,hint 的地址也跟着更新 hint.addr = p size = n break } // 此时,丢弃这次分配的内存,尝试下一个 arenaHints, 也就是下一个 1T 区间 // Failed. Discard this hint and try the next. // // TODO: This would be cleaner if sysReserve could be // told to only return the requested address. In // particular, this is already how Windows behaves, so // it would simplify things there. if v != nil { sysFree(v, n, nil) } h.arenaHints = hint.next h.arenaHintAlloc.free(unsafe.Pointer(hint)) }
mmap 的调用都是围绕着 arenaHints 来进行的,并且每次申请成功后都会更新 hint 的 addr,这样就实现了连续增长,直到失败。如果失败了,就从下一个 1TiB 的区间再次开始!
go 的 GPM 模型此处不作介绍,建议阅读Scheduling In Go : Part II - Go Scheduler 来了解并发模型。我们只说其中的 M,每个M 都有一个 g0 堆栈,用于执行 runtime 代码,其中较为特殊的 M0 (即 go 进程的主线程,每个 go 程序仅有一个 M0)的 g0 堆栈是通过汇编语言进行初始化的。
我们先来看看 go 程序的入口地址:
richard@Richard-Manjaro:~ » readelf -h carefree
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x463f20
Start of program headers: 64 (bytes into file)
Start of section headers: 456 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 7
Size of section headers: 64 (bytes)
Number of section headers: 23
Section header string table index: 3
读取 ELF文件头可知,入口地址为0x463f20,因为禁用了 cgo,没有动态链接库,所以 Entry point 指示的地址既是程序的入口地址。继续看一下该地址指示的代码:
richard@Richard-Manjaro:~ » lldb ./carefree
(lldb) target create "./carefree"
Current executable set to '/home/richard/carefree' (x86_64).
(lldb) image lookup --address 0x463f20
Address: carefree[0x0000000000463f20] (carefree.PT_LOAD[0]..text + 405280)
Summary: carefree`_rt0_amd64_linux
(lldb)
_rt0_amd64_linux 即为程序的入口,当运行程序时,shell 会 fork 一个子进程出来,之后执行 execve() 系统调用来装载 go 的可执行文件,当内核装载完毕之后,会将 CPU 的程序计数器设置为此入口点,之后 go 程序开始执行。
// Disable signals during clone, so that the new thread starts // with signals disabled. It will enable them in minit. var oset sigset sigprocmask(_SIG_SETMASK, &sigset_all, &oset) ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(abi.FuncPCABI0(mstart))) sigprocmask(_SIG_SETMASK, &oset, nil)
if ret < 0 { print("runtime: failed to create new OS thread (have ", mcount(), " already; errno=", -ret, ")\n") if ret == -_EAGAIN { println("runtime: may need to increase max user processes (ulimit -u)") } throw("newosproc") } }
effective go 中文版 是我个人的文档轮子。为了帮助需要的人准确理解原文,特采纳中英双语格式,目前翻译初稿已经完成。
互联网上已有 effective go 的中文版,甚至还不止一版,那为什么还要再造这个轮子呢?首先,我个人的初衷是为了锻炼自己的英文理解与翻译水平,同时也能磨砺中文的语言组织能力,更是为了把 go 语言的基础夯实。
其次呢,我在读第一遍英文时,碰到有疑问的地方在中文版里往往得不到想要的答案,后来自己思考也解决了一些疑惑,有些问题呢是出自翻译的问题,比如最后一章有一句话:The program here provides a nicer interface to one form of data: given a short piece of text, it calls on the chart server to produce a QR code, a matrix of boxes that encode the text.
冒号之后的内容姑且不论,它是对 a nicer interface 的详细阐述。我们看前半句中的 one form of data 到底指指什么?从字面意思看,或者由翻译软件翻译的话意思应该是:一种数据类别。我所见的两个翻译版本分别翻译成了 一种数据格式 和 某种形式的数据,可见就是照字面翻译,只是为了语句通顺问题,各自进行了调整。但即便是进行了调整,整个句子依然说不通,此程序为一种数据格式提供了更好的的接口 其意几何呢?
其实,下文中文档便给出了详细代码,html 的代码中有一个输入表单。我们知道 form 不仅有形式、类别、种类的意思,还具有表格的意思,并且在前端领域我们习惯于术语表单。所以此处分明是一个数据的表单之意!再者说,form 之前使用了数量词 one 而非定冠词 a ,我认为这是另一条佐证,这句话的本意是:本程序为表单数据提供了更加友好的接口。
除翻译问题外,春秋笔法,微言大义似乎也能造成困扰。effective go 虽为入门级必读资料,其内容算不上艰深,然而某些细微之处,于新手而言并不见得就能轻易领会,所以我在某些地方也注释了自己的心得。这看起来颇有几分古人注书的感觉,只不过我注的内容未必都对,所注条目也不甚多,但总归是自己花了精力的所思所想,相必对有些人有用也未可知,因此闲暇之余,又翻译了一版,很期待各位能够给予斧正。
// AvailableBuffer returns an empty buffer with b.Available capacity. // This buffer is intended to be appended to and // passed to an immediately succeeding Write call. func(b *Writer) AvailableBuffer() []byte { return b.buf[b.n:][:0] }
funcmain() { w := bufio.NewWriter(os.Stdout) for _, i := range []int64{1, 2, 3, 4} { b := w.AvailableBuffer() b = strconv.AppendInt(b, i, 10) b = append(b, ' ') w.Write(b) } w.Flush() }
文中的示例基于 X86_64 体系架构,基于 Linux 内核 5.9.16 版本,汇编语言采用 AT&T 汇编
在上一篇文章中,我简要介绍了 CPU 执行指令的过程,以及 CPU 如何将一段内存用于 stack。这篇文章会将讨论的重点集中于进程的内存布局上面,因为要搞明白 stack 的运作原理,必然要知晓 stack 在内存中分配的位置。而谈到位置,必然绕不开虚拟内存。
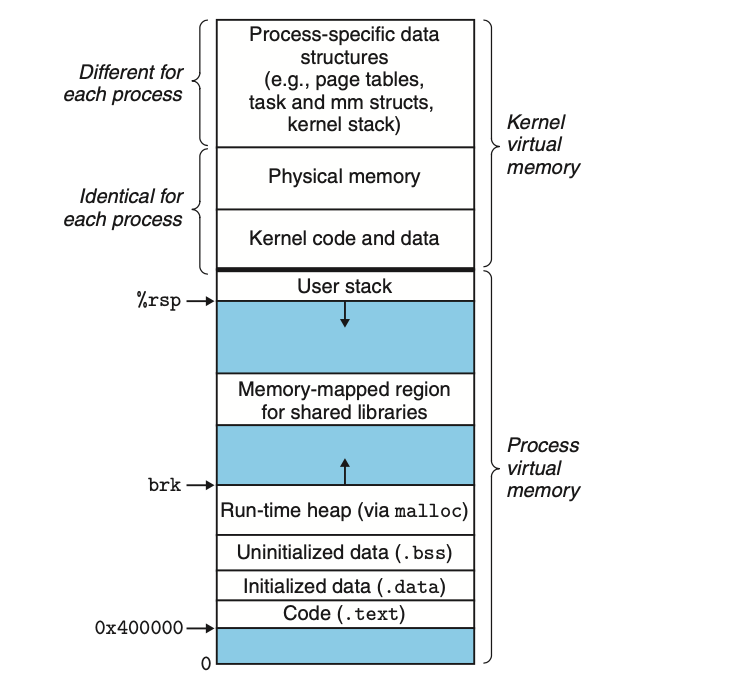
图 2-1 描述了一个 Linux 进程的虚拟内存布局,类似的布局图已经充斥于互联网的每个角落,虽形态各异,但描述的内容大抵相同。这张图我引用自 深入理解计算机系统.第三版,是一个比较详尽且权威的图(以后的文章中会经常出现此书,这是一本每个程序员必读的书):
这张图是进程的内存视角,从图中可知,进程虚拟内存的地址空间被分成两大部分:用户空间(Process virtual memory,也被称为user space)和 内核空间(Kernel virtual memory,也被称为kernel space)。每个进程拥有相同的用户空间视图(但彼此隔离),共享部分内核空间(如内核代码,图中的Identical for each process部分)。内核空间的另一部分是每个进程私有的, 如进程的内核堆栈、页表等。每个进程在内核空间都会有一块这样的私有区域(图中的Different for each process部分)。
但由于当时的计算机非常昂贵,人们很自然地想要减少这种浪费。在计算机的体系结构里,IO 设备和 CPU 是两种独立运行的部件,一个程序在进行 IO 的时候,CPU 往往无事可干。这当然是一种不能容忍的浪费,更何况任务的接续是由人来进行干预的。为了解决作业切换需要人员干预而造成的 CPU 浪费问题,人们改良了作业的运行机制,使得计算机在运行完一件作业之后可以自动的载入下一个作业,这就是真正的批处理时代。
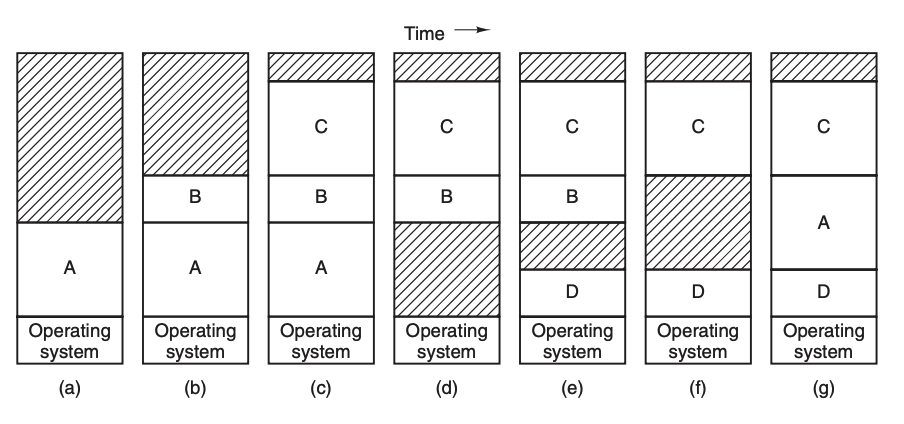
然而,批处理并没有解决作业在进入 IO 等待时 CPU 的闲置问题,如果一个程序在等待 IO 完成,那么何不将下一个程序调入内存来执行呢?于是计算机便进入了多道程序(multiprogramming)时代。图 2-3 展示了三个作业同驻内存的情况:
这种解决方案将内存分为几个部分,每个部分存放不同的作业,当一个作业在等待 I/O 完成时,另一个作业就可以使用 CPU。假如内存足够大,就可以容纳所需的全部任务,而 CPU 也就可以达到 100% 的利用率。
开始时内存中只有进程 A,之后创建进程 B 和 C。当 D 需要运行的时候,由于内存已经不足以容纳 D,A 即被交换到磁盘,D 装入内存。之后 B 运行完毕被调出,A 又被调入,但 A 的位置较之前发生了改变,所以在其被调入内存时需要特殊的手段对其进行重定位,比如我们之前介绍的段寄存器就适用于这种场景,代码段和堆栈段的寄存器都需要修改。
系统中的所有进程共享 CPU 和主存,这本身就是对操作系统内核的巨大挑战。如果其中的某些进程需要太多的内存,那么有可能就无法运行;如果某个进程不小心写了另一个进程的内存,程序便会出现某些迷惑的 BUG;甚至操作系统内核也暴露在这种风险之下,也许在某个时候整个机器就会莫名其妙的停止运行。所以现代的操作系统都提供了一种对主存的抽象,叫做虚拟内存。
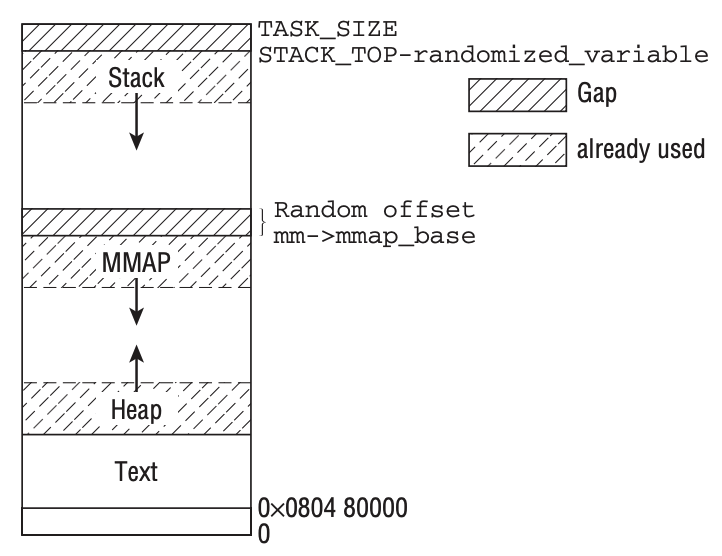
x86_64 架构下 Linux 平台二进制可执行文件的代码段总是从地址的 0x40000 处开始,这是在链接阶段就决定的。但是如果你在稍微新一点的 Linux 上去做测试的话,代码段的起始地址很大程度上并不是从 0x40000 处开始,它似乎是一个随机的值。比如,我用下面一个简单的 C 程序来观察其地址空间的分布:
==================================================== Complete virtual memory map with 4-level page tables ====================================================
Notes:
- Negative addresses such as "-23 TB" are absolute addresses in bytes, counted down from the top of the 64-bit address space. It's easier to understand the layout when seen both in absolute addresses and in distance-from-top notation.
For example 0xffffe90000000000 == -23 TB, it's 23 TB lower than the top of the 64-bit address space (ffffffffffffffff).
Note that as we get closer to the top of the address space, the notation changes from TB to GB and then MB/KB.
- "16M TB" might look weird at first sight, but it's an easier to visualize size notation than "16 EB", which few will recognize at first sight as 16 exabytes. It also shows it nicely how incredibly large 64-bit address space is.
书中的论断于当今的 Linux 内核是否仍适用,我目前也无从证明,但这已无关紧要。进程的虚拟地址空间布局也经过多次变迁,我们如今讨论的默认空间布局想来也不会一成不变。但 Linux 内核志在为用户呈现虚拟内存抽象的思想已可见一斑。可以肯定的是,它一定在繁芜的细节上做了大量细致的工作,才有了用户空间代码使用内存时的举重若轻。
3.2 stack 能长到多大 ?
要验证 stack 能长多大,说来也很容易,下面这段 C 代码就可以探测到 stack 的边界:
1 2 3 4 5 6 7 8 9 10 11 12
#include<alloca.h> #include<stdio.h> intmain(void) { long a = 0; for (;;) { void *y; y = alloca(128); a += 128; printf ("\nStack Size = %ld", a); } }
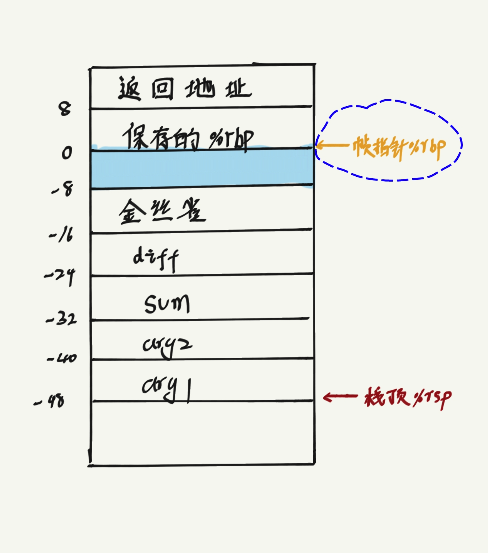
每一个函数在 stack 分配的空间统称为该函数的栈帧(stack fram),图 2-12 给出了运行时 stack 的通用结构,包括把它划分为栈帧,当前正在执行的函数的帧总是在栈顶。假设 函数 P 在执行过程中调用了函数 Q,当函数 P 调用函数 Q 时,会把返回地址压入栈中,指明当 Q 返回时,要从 P 程序的哪个位置继续执行。我们把这个返回地址当做 P 的栈帧的一部分,因为它存放的是与 P 相关的状态。
Q 的代码会扩展当前堆栈的边界,为它的栈帧分配所需的空间。在此空间中, Q 可以保存寄存器的值,分配局部变量,如果它还调用其它函数,则为被调用的函数设置参数。函数 P 可以通过寄存器传递最多 6 个参数,如果 Q 的参数个数超过了 6 个,则 P 在调用之前会在自己的栈帧里存储好这些参数。
函数调用需要打破当前 CPU 顺序执行指令的状态,使其跳转至另外一部分代码块。这种控制转移自然是通过修改程序计数器(PC)来达成的,将控制从 P 转移到 Q,仅需将 PC 修改为 Q 的代码的起始位置。不过当 Q 返回的时候,CPU 必须要知道它要在 P 中继续的位置。x86_64 机器中,这个过程是通过 call和ret指令配合完成的。
首先,函数调用通过call Q来进行,该指令会把地址 A 压入堆栈中,并将 PC 设置为 Q 的起始地址。压入的地址 A 通常叫做返回地址,是紧随 call 指令之后的那条指令的地址。对应的指令 ret会从堆栈中弹出地址 A,并把 PC 设置为 A。
All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change must be stored on the heap instead. The heap is less organized: when you put data on the heap, you request a certain amount of space. The memory allocator finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. This process is called allocating on the heap and is sometimes abbreviated as just allocating. Pushing values onto the stack is not considered allocating. Because the pointer is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer.
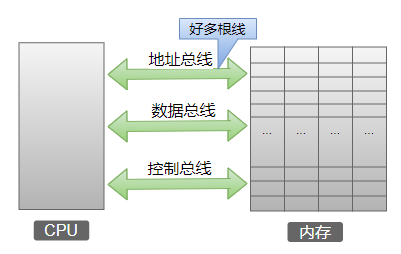
众所周知,计算机内部用二进制表示一切。从应用的角度而言,内存中存放的信息大致可分为指令和数据,然而在内存看来,这些信息并没有什么区别。一段信息是指令还是数据,全看 CPU 如何使用它们。CPU 在工作的时候,把有的信息看作指令,有的信息看作数据,为同样的信息赋予了不同的意义。那这是如何做到的呢?我们以 8086 CPU 为例来简要说明。
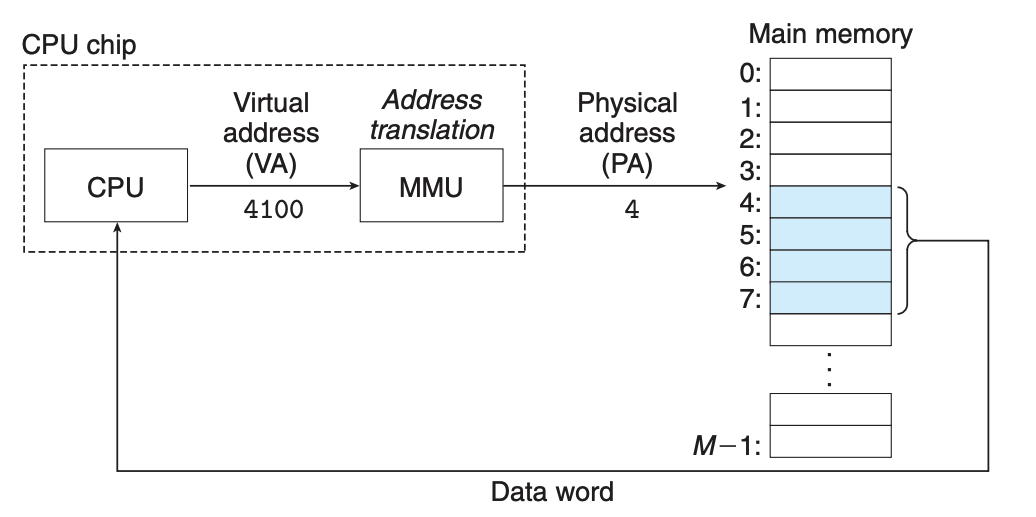
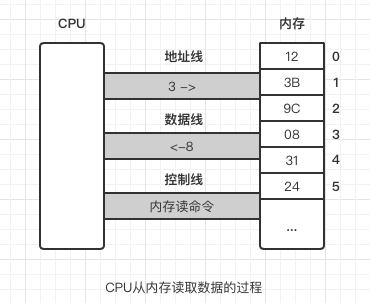
如图所示,CPU 与内存之间有三类总线,分别为地址总线、控制总线和数据总线。数据的读、写就是靠这三类总线配合完成的。我们来看一下 CPU 从内存 3 号单元中读取数据的过程。
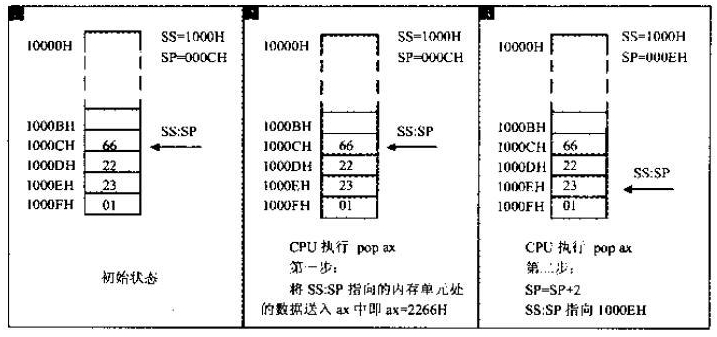
CPU 把主存当做什么用,完全看我们的规划以及使用的指令,比如设置了代码段之后,代码段部分保存的数据就被 CPU 看做指令,当设置了 DS 数据段之后,使用 mov 等操作时 CPU 即将内存中的内容视作数据,当设置了 SS 段之后,使用 PUSH 和 POP 时 CPU 就把那块内存当做堆栈来使用。
CPU 对主存的一视同仁可以在另外一个现象上得到印证,如果使用现代的编译器编译为汇编文件,你会发现很多理论上应该使用 PUSH 的地方却使用了 MOV,这是因为编译器做了优化,PUSH 隐含了两个操作,一个是移动数据,一个是维护堆栈指针。当操作较多时,指针维护较为频繁,为性能计转而使用 mov 来达到目的,并在必要的时候手动维护栈顶指针。这间接说明了堆栈段的内存并无甚特别之处,其特别只在于使用的方式(入栈和出栈的操作同样可以用 mov 和数据段来配合达到)。
Intel 在 8086 的继任者身上实现了保护模式,对虚拟内存提供了硬件上的支持。保护模式依然使用段来加强寻址,且方案设计非常复杂精巧,这种方式人们将其称为 IA-32 保护模式,但是此种模式应用甚少,进入 64 bit 时代后,CPU 仅仅作为兼容需要予以保留。
AMD 是第一个吃螃蟹的,首次从架构上将 CPU 的虚拟寻址空间带入 64 bit 模式(可参考 wiki x86-64 的描述,内容还算详实),虽然在架构上已支持 64 bit,但是 AMD 在处理器的实现上实际仅支持 48 bit 的虚拟寻址空间,以及 40 bit 的物理寻址空间;对应的 Intel i7 实现为 48 bit 虚拟寻址空间 和 52 bit 的物理寻址空间。这主要是出于经济上的考虑,并在架构设计上做了功夫,使得日后可以很容易扩展到真正的 64 位。不要小看 48 bit 的寻址空间,这意味着当前实现的 CPU 最大支持 256 TB 的内存寻址,然而当下几乎没有场景会达到这一临界点。更详细的内容可以参考这两篇讨论:
why virtual address are 48 bits not 64 bits?
Why do x86-64 systems have only a 48 bit virtual address space?
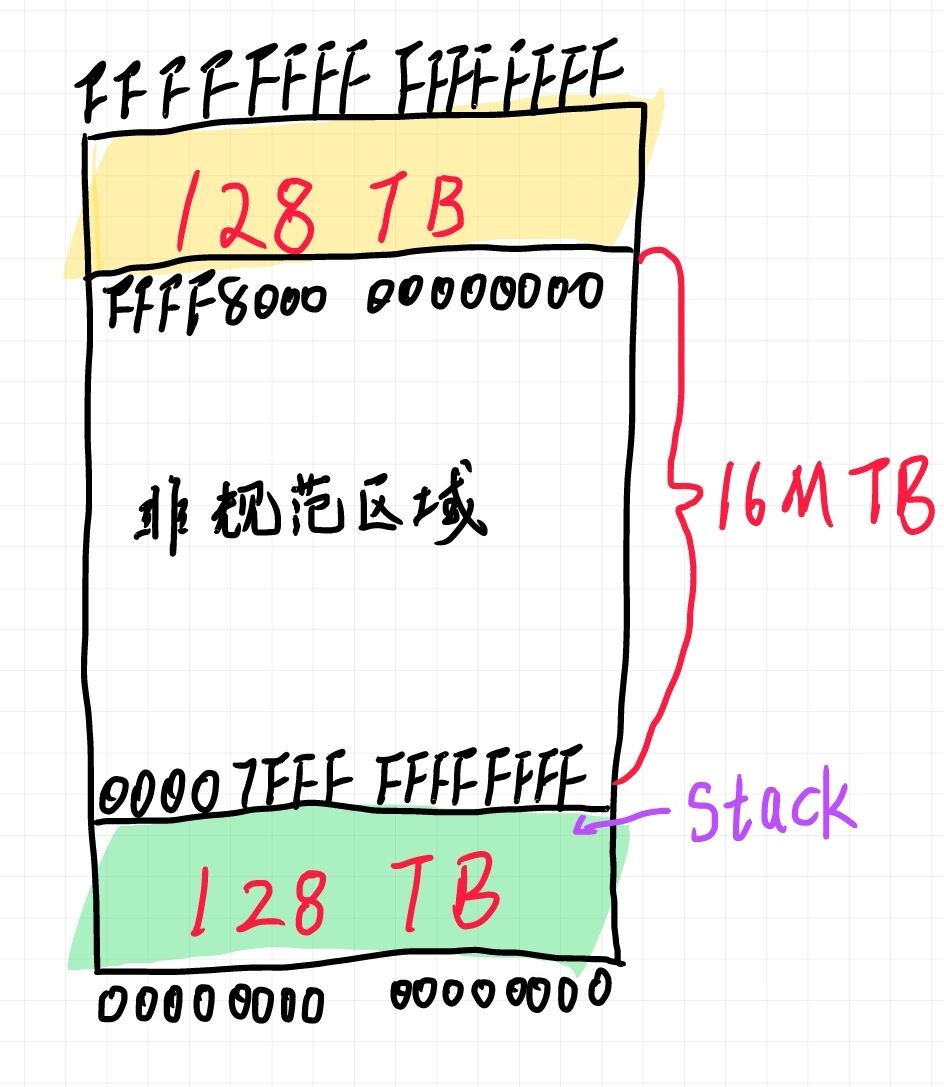
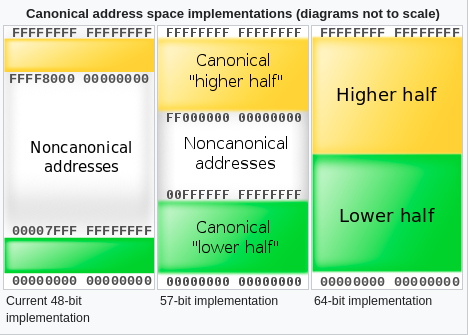
在这里有必要提一下 64 bit 模式下与寻址相关的Canonical form addresses,AMD 标准规定:虚拟地址的高 16 位 也就是从 48 位到 63 位必须拷贝第 47 位的值。Canonical form addresses 规定有效的地址空间为 0 到 00007FFF'FFFFFFFF,以及 FFFF8000'00000000 到 FFFFFFFF'FFFFFFFF,可以看下图形象的表示:
Canonical form addresses 将空间分为上下两部分,可见 48 bit 寻址空间下中间有很大的的空洞。Linux 将上部 128TB 用于内核空间,下部 128TB 用于用户空间,即可以寻址 256 TB 的内存空间。无论如何地址已经是 64 bit 的了,不再需要借助段寄存器。
想象一下这样一个工具:它会遍历一个目录,并返回所能找到的所有以.go结尾的文件名称。如果此工具不能和文件系统交互,那么它将毫无用处。现在,假设有一个 web 应用,它内嵌了一些静态文件,比如images, templates, and style sheets等等。那这个 Web 应用程序在访问这些相关assets时应使用虚拟文件系统,而不是真实文件系统。
funcGoFiles(root string) ([]string, error) { var data []string
err := filepath.Walk(root, func(path string, info os.FileInfo, err error)error { if err != nil { return err } base := filepath.Base(path) for _, sp := range SkipPaths { // if the name of the folder has a prefix listed in SkipPaths // then we should skip the directory. // e.g. node_modules, testdata, _foo, .git if strings.HasPrefix(base, sp) { return filepath.SkipDir } }
for _, s := range SkipPaths { // ex: ./.git/git.go // ex: ./node_modules/node_modules.go names = append(names, filepath.Join(s, s+".go")) }
for _, f := range names { if err := os.MkdirAll(filepath.Join(dir, filepath.Dir(f)), 0755); err != nil { b.Fatal(err) } if err := ioutil.WriteFile(filepath.Join(dir, f), nil, 0666); err != nil { b.Fatal(err) } }
list, err := GoFiles(dir)
if err != nil { b.Fatal(err) }
lexp := 2 lact := len(list) if lact != lexp { b.Fatalf("expected list to have %d files, but got %d", lexp, lact) }
sort.Strings(list)
exp := []string{"foo.go", "web/routes.go"} for i, a := range list { e := exp[i] if !strings.HasSuffix(a, e) { b.Fatalf("expected %q to match expected %q", list, exp) } }
funcBenchmarkGoFilesExistingFiles(b *testing.B) { for i := 0; i < b.N; i++ {
list, err := GoFiles("./testdata/scenario1")
if err != nil { b.Fatal(err) }
lexp := 2 lact := len(list) if lact != lexp { b.Fatalf("expected list to have %d files, but got %d", lexp, lact) }
sort.Strings(list)
exp := []string{"foo.go", "web/routes.go"} for i, a := range list { e := exp[i] if !strings.HasSuffix(a, e) { b.Fatalf("expected %q to match expected %q", list, exp) } }
funcGoFilesFS(root string, sys fs.FS) ([]string, error) { var data []string
err := fs.WalkDir(sys, ".", func(path string, de fs.DirEntry, err error)error { if err != nil { return err }
base := filepath.Base(path) for _, sp := range SkipPaths { // if the name of the folder has a prefix listed in SkipPaths // then we should skip the directory. // e.g. node_modules, testdata, _foo, .git if strings.HasPrefix(base, sp) { return filepath.SkipDir } }
type FS interface { // Open opens the named file. // // When Open returns an error, it should be of type *PathError // with the Op field set to "open", the Path field set to name, // and the Err field describing the problem. // // Open should reject attempts to open names that do not satisfy // ValidPath(name), returning a *PathError with Err set to // ErrInvalid or ErrNotExist. Open(name string) (File, error) }
// ReadDir reads the contents of the directory and returns // a slice of up to n DirEntry values in directory order. // Subsequent calls on the same file will yield further DirEntry values. // // If n > 0, ReadDir returns at most n DirEntry structures. // In this case, if ReadDir returns an empty slice, it will return // a non-nil error explaining why. // At the end of a directory, the error is io.EOF. // // If n <= 0, ReadDir returns all the DirEntry values from the directory // in a single slice. In this case, if ReadDir succeeds (reads all the way // to the end of the directory), it returns the slice and a nil error. // If it encounters an error before the end of the directory, // ReadDir returns the DirEntry list read until that point and a non-nil error.
funcBenchmarkGoFilesFS(b *testing.B) { for i := 0; i < b.N; i++ { files := MockFS{ // ./foo.go NewFile("foo.go"), // ./web/routes.go NewDir("web", NewFile("routes.go")), }
for _, s := range SkipPaths { // ex: ./.git/git.go // ex: ./node_modules/node_modules.go files = append(files, NewDir(s, NewFile(s+".go"))) }
mfs := MockFS{ // ./ NewDir(".", files...), }
list, err := GoFilesFS("/", mfs)
if err != nil { b.Fatal(err) }
lexp := 2 lact := len(list) if lact != lexp { b.Fatalf("expected list to have %d files, but got %d", lexp, lact) }
sort.Strings(list)
exp := []string{"foo.go", "web/routes.go"} for i, a := range list { e := exp[i] if e != a { b.Fatalf("expected %q to match expected %q", list, exp) } }
虽然本文介绍了如何使用新的io/fs包来增强我们的测试,但这只是该包的冰山一角。比如,考虑一个文件转换管道,该管道根据文件的类型在文件上运行转换程序。再比如,将.md文件从Markdown转换为HTML,等等。使用io/fs包,您可以轻松创建带有接口的管道,并且测试该管道也相对简单。 Go 1.16有很多令人兴奋的地方,但是,对我来说,io/fs包是最让我兴奋的一个。