在 CPU 上起舞,聊一聊 Linux 调度和 Go 的 Runtime 调度
CPU是一个舞台,操作系统内核是位技艺精湛的指挥家,形形色色的进程就是舞者,它们在内核的指挥下轮番上台表演,演奏一场生命的赞歌!
1
调度是件很神奇的事,一直以来我都对它无比着迷,并不断地钻营个中奥妙。几年下来,略有心得,于是思索着记录下来,以备将来优哉游哉忘乎所以后回来检索之用。
然而吸引我的并不是调度算法,而是调度的时机和原理。因此这篇文章只讨论调度时机和 Linux 内核的调度原理,与调度算法无涉,本文将调度算法当成一个黑盒,优先了解调度行为本身。
计算机操作系统进入多道程序后,需要支持多个程序并发运行,这就需要操作系统必须有能力管理多个程序的运行,必要的时候进行程序切换,使得多个程序轮流获得CPU的使用权。当操作系统需要协调多个程序运行时,就有必要做点什么来保证各个程序可以无冲突并发运行(并发和并行的区别,此处不予讨论)。我们不妨做个不严谨的类比,如果需要使用文字来描述每个任务,那么把所有的任务写在一个文档里显然不是明智之举,即便是计算机新手,也懂得为每个任务单独建一个文档分别管理;当任务变得复杂,发展出很多支线时,一个文档很快又会捉襟见肘,不利于管理了。此时,聪明的做法就是为这个任务创建一个文件夹,每个文件夹中有若干文档,这些文档描述了任务的主线和若干支线,如果有必要它们可以共享文件夹中的图片、音视频等多媒体。
我想你一眼就能看出来,上面的描述是在说进程和线程。不过我类比的重点并不是进、线程本身,而意在说明:要管理多个任务,就必然会采取某种结构来分门别类,分而治之!也就是说,操作系统内核会使用一个结构体来描述进程、线程及其相关的一切。那可以称这个结构体为进程或者线程吗?答案当然是否定的!谈调度自然绕不开进程和线程,因此我们要直面一个难题:你永远无法轻易地说清楚进程是什么!
2
《操作系统导论》将进程定义为:操作系统为正在运行的程序提供的抽象!认为进程只是一个正在运行的程序,并且声明机器状态(程序在运行时可以读取或更新的内容)为进程的一部分,机器状态包括内存和寄存器。
无独有偶,《深入理解计算机系统》对进程的定义是:进程是操作系统对一个正在运行的程序的一种抽象。这和《操作系统导论》中给出的定义如出一辙,但是它紧接着还给出了线程的定义:进程往往不只有单一的执行流,进程实际上可以由多个称为线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。
《深入理解Linux内核》补充说:可以把进程看作充分描述程序已经执行到何种程度的数据结构的汇集。这直接印证了我们之前的类比,从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的实体。这本书更偏爱于将进程描述成拥有多个相对独立的执行流,程序运行的本质就是CPU不断的执行一系列的指令序列,所以看起来就像是不断行进的流。
传统的Unix进程只拥有一个执行流,即便是现代主流语言的编程模式,如果你不采用多线程编程的话,进程也只有一个执行流,我们习惯称之为主线程;一旦使用了多线程的编程范式,进程就会拥有多个独立的执行流,Linux 内核就会为每个执行流分配单独的数据结构来管理资源的使用及其机器状态。实际上,Linux内核中的数据结构并不区分进程和线程,统一都使用task_struct这个结构体来描述一个执行流,程序的调度也是基于这个结构来进行的,而同属于一个进程的线程结构会共享某些资源,比如代码段、虚拟地址空间、打开的文件描述符、信号、堆等,只有堆栈是每个线程私有的。因此,当我们谈论进程时更多的是从资源的角度去思考,而谈到线程时,更多的是从执行流的角度去考虑。
综上,可以给出我心中对于进程的定义:进程是若干个活动的执行流以及各类相关资源的总称,这些资源包括了内核结构、地址空间(内存),寄存器等,其中进程的地址空间包括了多种类型的资源,代码段、数据段、堆、线程堆栈、文件映射等等;有些资源是线程共享的,比如堆、代码段,有些是线程私有的,比如堆栈。这些资源和若干独立执行流共同组成了进程这个抽象概念!
我们即将要探讨的就是:内核是如何将一个执行流从 CPU 上换下,代之以另一个执行流的!
3
这一章节中出现新进程和新建进程两个词语,未免混淆特此说明如下:
新进程:上下文切换时,被选中替换当前进程者
新建进程:使用fork、clone等创建的新进程或新线程
需要明确的一件事情就是内核调度的粒度,你定然听过“线程是调度的基本单位”这样的说法,这种说法固然没有错,但具体每个操作系统的实现却多有不同。以 Linux 为例,其内核角度并不区分进程和线程,用于标识调度单位的结构一律都是task_struct,因此后续的行文不会刻意区分进程和线程。
为了控制进程的执行,内核必须有能力挂起正在 CPU 上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换、任务切换、上下文切换。这是从 CPU 的角度来看,如果站在内核的角度,那么这种行为就是在进行进程调度。
进行任务切换或者调度的根本原因在于 CPU 和寄存器是共享的,大家必须轮流使用!
有意思的是,执行任务切换的并不是一个进程或者内核线程,而是一个函数schedule()。内核中有很多精心定义的点来执行schedule(),我们先来观察schedule()如何执行进程切换,至于调度的时机稍后进行讨论。
进程切换只会也只应发生在内核态,这本身就是内核的职责,需要申明的一点是:执行流进入内核态后,用户态的硬件上下文已经保存在该进程对应的内核态堆栈上了,当该进程从内核态返回用户态时即可恢复原貌,从之前的终止处继续执行。
进程切换由两步组成:
- 切换进程地址空间
- 切换内核态堆栈和硬件上下文
schedule 会调用 context_switch 执行上下文切换,我们以 Linux 内核 5.10 版本为例,假设此时已经由调度算法挑选出了下一个即将运行的进程next,执行流进入context_switch的代码执行上下文切换:
kernel/sched/core.c
1 | /* |
context_switch的前半部分完成进程地址空间切换,switch_to 完成硬件上下文切换,此处主要关注switch_to如何完成上下文切换,毕竟我们只对执行流的变更感兴趣。
switch_to 是个预定义的宏,因其是和硬件体系结构密切相关的,所以主要部分需用汇编语言实现,我们看一下它的内容:
arch/x86/include/asm/switch_to.h
1 |
__switch_to_asm 即是由汇编实现的程序主体:
arch/x86/entry/entry_64.S
1 | /* |
首先遵循被调用者原则保存6个寄存器的值,保存的方式就是压入即将被替换进程prev的内核栈,直到此时执行流依然使用prev的内核栈,不过接下来就开始切换内核栈了:
1 | /* switch stack */ |
依照内核函数的调用惯例,%rdi和%rsi两个寄存器分别存放调用时传入的第一和第二个参数:__switch_to_asm((prev), (next)))。
movq %rsp, TASK_threadsp(%rdi) 的结果是将当前内核栈的栈顶指针寄存器内容保存至prev进程(也就是当前进程)的thread->sp中,thread 是进程描述符task_struct 中一个类型为thread_struct的字段,里面会保存大部分 CPU 寄存器(但不包括 rax、rbx 等通用寄存器,它们的值保存至内核堆栈中)。而movq TASK_threadsp(%rsi), %rsp这一句将被选中进程next中之前被保存的栈顶指针恢复至rsp寄存器,执行完这一条之后执行流的内核堆栈就切换到新进程了。
严格来讲,从上面一条指令之后就是新进程的执行流了,可以说改变内核堆栈就意味着改变当前进程。这归因于和内核堆栈一起存放的一个名为thread_info的结构,内核都是通过它来寻找当前进程的描述符(参考《深入理解Linux内核》88页-标识一个进程)。
接下来,从新进程的内核堆栈中弹出之前保存的6个寄存器的值,然后 jmp 到 __switch_to 函数,__switch_to 函数依然做一些保存老进程上下文和加载新进程上下文的工作,此处不再深入展开,我们仅将注意力集中到jmp这条指令上。
如果你熟悉 2.6 版本的内核,读过《深入理解Linux内核》,你就会奇怪:为何此处切换了新进程的rsp,却没有rip的切换呢?2.6 版本是会将新进程 thread 字段中的ip推入内核堆栈作为返回地址(该指令地址就位于switch_to中),这样在 __switch_to 中ret时就会跳转到thread->ip指向的代码指令了,这也是为什么用jmp 不用 call的原因(call 会将ip 压栈,而jmp只是简单的跳转,不会压栈)。当我读到此处时,禁不住废书而叹,惊讶其设计的巧妙,但同时也生出疑问:既然新进程保存的地址就在附近,为何非要到thread->ip中绕一圈呢?直接把该地址推入内核堆栈效果不也一样吗?可能是内核的设计者也意识到这一点,在 2.6 版本 64 位内核直到最新的5.x版本就放弃了这种做法,不再去刻意的保存和恢复进程的rip 了,因为新进程的起点总是在switch_to函数中。
所以,此处在__switch_to 返回时会跳到开始的switch_to处:
1 |
栈帧一层层解开,会返回到 context_switch 函数调用,继而回到schedule()。可见,任何一个进入内核态调用schedule()执行任务切换的进程,最终都会等到schedule()调用的返回。我们稍后会讲到 Go 运行时的协程调度,其schedule函数是不会返回的,所以它看起来并不像一个函数,这是区别于操作系统调度函数一个重要的点。
分析到此处,我们可能会以手舞之,以足蹈之,感觉终于在指令级别“看到”进程切换的本质了!不过还没到欢欣鼓舞的时候,我们似乎忘掉了一种情形:如果被选中的新进程是新创建的,从来没有被运行过,该又如何呢?__switch_to中ret时执行流又将流向何方呢?毕竟新进程是没有执行过schedule()的。
依然是内核堆栈救了我们!
要意识到的一点是:新建进程的内核堆栈并不是空的,它 copy 自父进程并经过精心的构造。
以 clone系统调用为例,copy_thread用发出clone()系统调用时的CPU寄存器的值(此时都在父进程的内核堆栈中)来初始化子进程或者线程的内核堆栈。不过copy_thread会把rax寄存器对应字段的值(这是fork和clone系统调用在子进程或线程中的返回值)强行置为0,这就是为何我们使用fork时要通过返回值来判断此时执行的是子进程还是父进程。既然说到这里,就聊一下clone系统调用的封装接口吧!线程创建的接口是由标准库 glibc 中的包装函数实现的,它处理了返回值的问题,如果是主线程则返回到调用处,如果是新建线程则跳转到任务函数调用处,这是 glibc 封装函数通过推入新线程的堆栈实现的。我们可以观察一下glibc 的 clone 封装代码:
1 | /* The userland implementation is: |
开头的注释部分很好地揭示了用户态代码和内核态代码对于传参的不同要求,即寄存器的使用规则。关键点是movq %rdi,0(%rsi)这一句,它将线程要执行的fn地址推入了新进程的堆栈,并在L(thread_start):部分通过下面三条指令启动新线程执行流:
1 | popq %rax /* Function to call. 弹出函数地址 */ |
Go 并不使用标准的 C 库,其 runtime 重写了所有的系统调用封装函数,从 Go 的 clone 实现来看,也是相似的逻辑。不过,Go 使用 plan9 汇编,在阅读上会有一些不便:
1 | // int32 clone(int32 flags, void *stk, M *mp, G *gp, void (*fn)(void)); |
回到操作系统内核新建进程的话题上来,前面讲过,在内核 3.0 到最新的 5.x 版本不再去刻意的保存和恢复进程的rip 了,因为新进程(被选中的进程)的起点总是在switch_to函数中。那么在新建进程初次运行的问题上,新旧版本虽然看上去不同,但殊途同归,最终都会把执行流引向ret_from_fork(),我们先看看 2.6 版本 32 位内核的操作:
1 | #define switch_to(prev,next,last) do { \ |
从注释可以看出,在切换了内核堆栈之后,开始保存旧进程的EIP恢复新进程的EIP,恢复新进程的EIP是通过pushl %6来完成的,这句话的意思是将next->thread.eip的值压入内核堆栈,以便后面的C函数__switch_to返回时跳转。这是比较巧妙的一个地方,对于一个曾经被调度过的进程,其thread.eip中保存的就是1:标号处的指令,这是通过movl $1f,%1指令实现的(此处即上文提到的跳转地址本身就位于switch_to函数中)。问题是对于一个未曾运行过的新进程来说,是没有执行过switch_to代码的,所以此处pushl %6入栈的并不是标号1:处的代码,而是在创建进程时设置的ret_from_fork(),当__switch_to执行到ret 时,从内核堆栈弹出要跳转的地址,这个地址就是ret_from_fork(),新建进程的旅程便由此开始!
64 位的 2.6 内核版本稍微有些区别,但结果都是一样的,这里不再赘述,感兴趣的可以参考Evolution of the x86 context switch in Linux 这篇文章,其详细描述了从内核1.0版本到4.14版本上下文切换部分的设计变更。
回到我们开始讨论的 5.10 版本的__switch_to_asm,当被选中的新进程是一个新建进程时,jmp __switch_to返回后会跳转到哪里呢?答案当然是ret_from_fork(),新进程没有调用过schedule(),故不会回到其调用栈,此时只需搞清楚新进程的内核栈内容就能明白执行流的走向了,新建进程时执行完copy_thread()之后,进程的内核堆栈示意图如下:
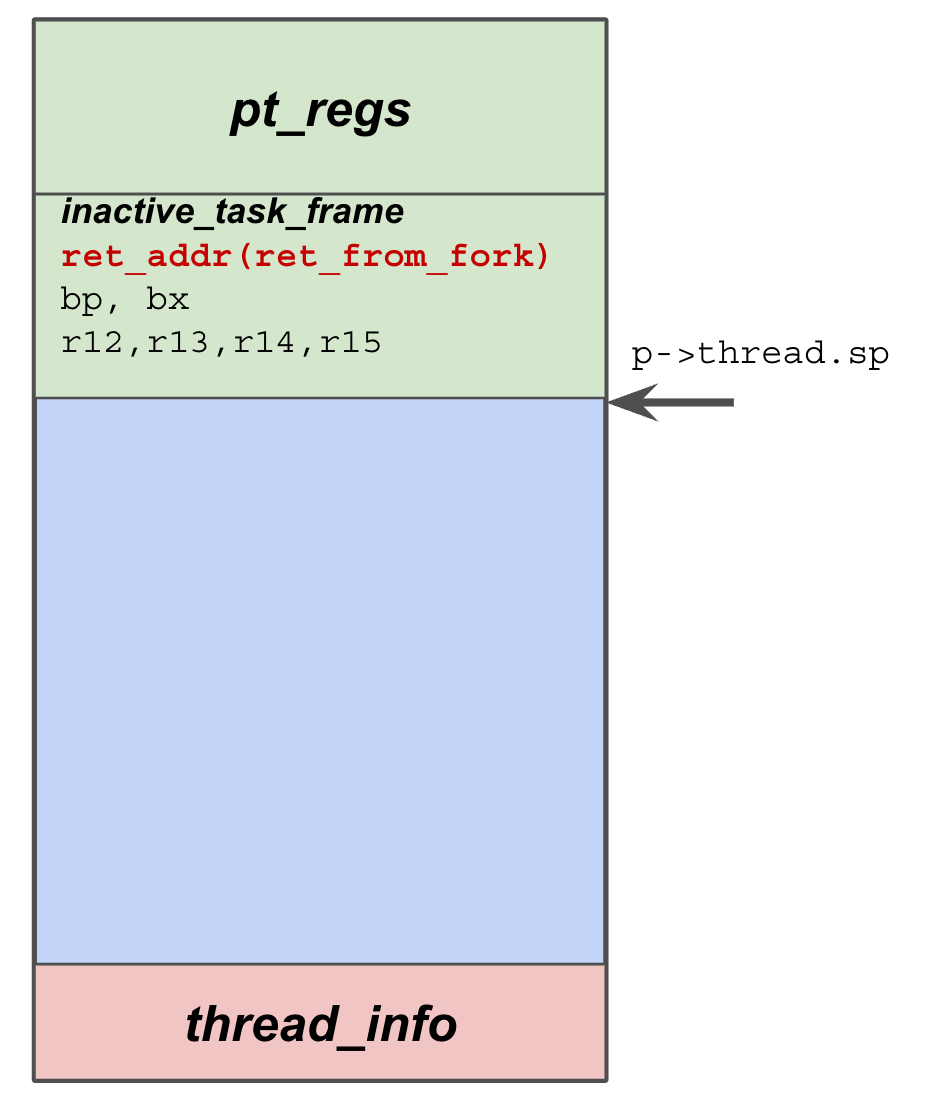
如图 3-1 所示,弹出6个寄存器之后,就只剩ret_from_fork()的地址了。
4
虽然ret_from_fork()是新建进程的开始,但在真正返回到用户空间之前仍然横着一道关卡,那就是检查是否需要进行再调度。这是有可能的,如果有一个优先级更高的进程需要运行,那么时钟中断处理程序兴许已经在thread_info中做好了标记,等待着schedule()被调用。在真正回到用户空间之前,ret_from_fork()会检查这些标记,如果有必要,就调用schedule()。所以,我们就可以发问了,schedule()返回之后,执行流会去向哪里?
于ret_from_fork()而言很简单,如果它真的调用了schedule(),当调度函数返回时,进程会以一个“老程序”的身份初次进入用户空间。因此问题的本质是何时会调用schedule(),换句话说,内核的调度时机有哪些?
Linux 调度时机主要有:
- 进程状态转换时刻:进程终止、进程睡眠;
- 当前进程的时间片用完;
- 进程主动调用
- 进程从中断、异常及系统调用返回到用户态时。
时机1,进程要调用sleep()或exit()等函数进行状态转换时,这些系统调用会主动调用调度函数进行进程调度。
时机2,由于进程的时间片是由时钟中断来更新的,因此,这种情况和时机4是密不可分的。
时机3,当进程某些资源无法获取,或者设备驱动程序执行长而重复的任务时,进程主动调用调度函数主动放弃CPU,比如锁、缺页等场景。
时机4,调度的绝大多数占比应属于此种情况,CPU 会在每次执行完一条指令之后检查是否有中断产生,如有则进入中断处理程序。当从中断、异常及系统调用返回到用户态时都会检查调度标志,如果检测为真则进入调度函数。
《操作系统导论》中说道:一旦时钟开始运行,操作系统就感到安全了,因为控制权最终会还给它,因此操作系统可以自由运行用户程序。
可见,在中断返回之前进行调度是一个绝妙的方法。因此,我们可以说:schedule()返回之后的去向并不唯一,有可能是中断、异常和系统调用返回用户空间之前,也有可能是在系统调用进行之中。这也是为何进程切换只会发生在内核态。
我用一幅图来描绘一下,进程的执行流在用户态和内核态之间变换以及进程切换的场景,让我们以指令的视角在进程的用户态和内核态之间,在进程与进程之间进行一场穿梭之旅。
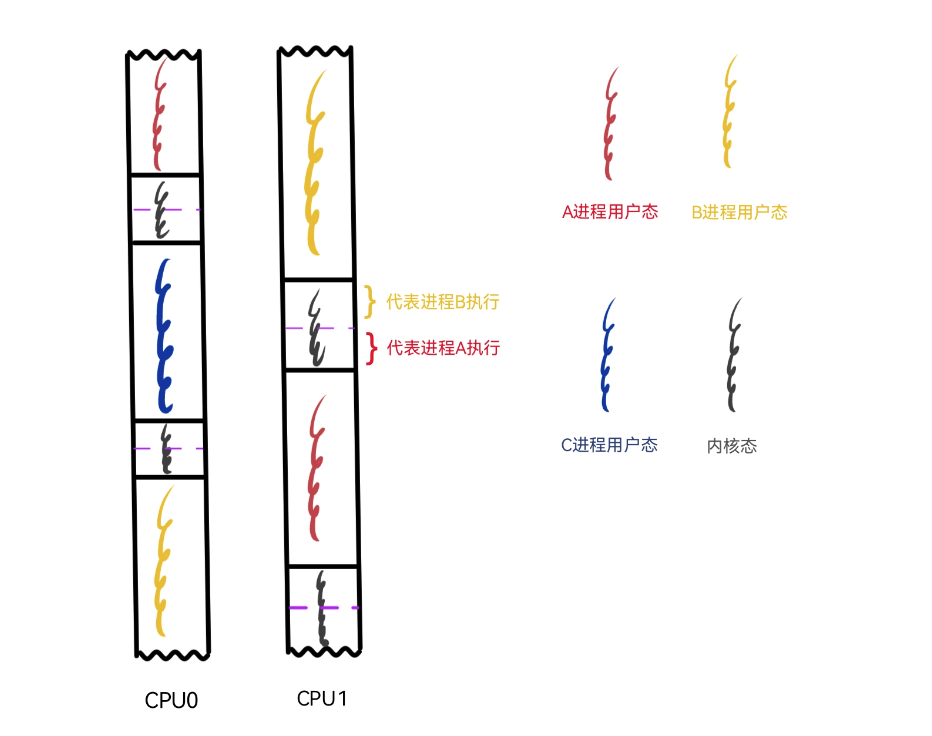
图 4-1 描述了3个进程在两颗CPU上的执行情况,注意这并不是以进程的视角来展现的,各种颜色的执行流仅表示进程处于用户态,灰色的执行流代表内核态,不同的是内核态的前半部分代表当前进程,后半部分则是经过进程切换后代表下一个进程。图中进程B切换为进程A,当执行流进入内核态执行切换时,切换之前内核代表进程B执行,切换之后内核代表新进程A执行。
图 4-1 仅仅展示了进程切换的场景,并不是指进程的执行流进入内核态后一定会发生进程切换
要理解“代表”的含义,就需要解释一下thread_info这个数据结构,我们前面曾提到过它,但未加以详述,此处有必要略作说明。
thread_info被称为线程描述符(不应纠结于概念,把线程理解为一个执行流即可),这个结构包含了指向进程描述符task_struct的指针,因此,内核若想确定当前运行的进程,只需要找到thread_info即可。但问题是如何确定其位置呢?内核的处理方法依然非常巧妙——将thread_info和进程内核堆栈一起存放!放一幅图即可一目了然:
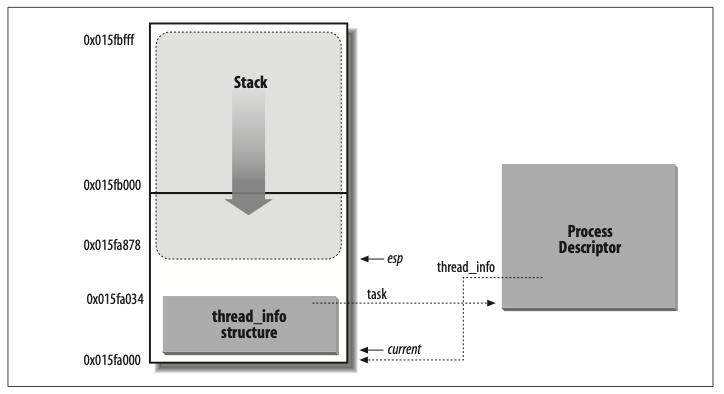
图 4-2 所示,这是一块 8k 大小的内存,内核堆栈由高地址向低地址增长,thread_info 存放在最底部,其大小通常是 52 字节,因此,内核堆栈能扩展到8140字节。这个大小看上去很小,至少远远小于进程的用户态堆栈的默认大小(Linux 上用户态堆栈的大小为8M)。这是因为内核控制路径用到的堆栈很少,只需几千字节足矣!
《深入理解Linux内核》说道,从效率的观点来看,thread_info结构与内核态堆栈之间的紧密结合提供的主要好处是:内核很容易从esp寄存器(栈顶指针寄存器)的值获得当前在CPU上正在运行进程的thread_info结构的地址。假设thread_info和内核堆栈的结合体大小就是 8K,那么内核屏蔽掉 esp 的低 13 位有效位就可以获得thread_info结构的基地址。由此可知:切换了内核堆栈就等于切换了当前进程。
还可以从资源使用统计上来理解“代表”的含义。当进程进入内核态时,其对CPU的时间的消耗则记录在进程的sys、hiq、siq 等指标上,由此可以想见一个内核的流氓特征:与我无关的中断处理对于CPU的消耗都算在了我的头上!
之所以强调“代表”,是为了说明进程是相对执行流而言的,而不是相对程序而言。这里的程序指的是躺在硬盘上的二进制数据,或者说用户态的指令集,其实用户态的指令集囊括了磁盘上的二进制数据。换句话说,如果程序是完全静态链接的,程序的二进制就完全包括了用户态指令集,反之,用户态指令集是大于二进制数据中的指令集的,这是由动态链接决定的。
我曾在论坛上与人争论过一个问题:向 redis 发出一个删除大量key的命令,redis 的主线程是否可以说被阻塞了?
很多人的观点是主线程要释放内存会进入系统调用,因释放内存耗时较长故主线程被阻塞。而我的观点是:在删除大量key时,redis 主线程并没有阻塞,阻塞的是发出指令的客户端以及排队发送指令的其它客户端!经过上面的论证,我们知道内核态的执行流一部分代表当前进程,一部分代表切换后的新进程,所以,在被调度之前,不管是用户态还是内核态,都表示这个进程仍在CPU上运行。不能说 redis 线程发起系统调用后陷入了内核,这个线程就被阻塞了,这是不正确的。此时CPU上的执行流依然属于 redis 主线程,其对资源的消耗仍会被记录在该线程名下。redis 主线程一直在努力干活,没有被阻塞,只是这个线程进入到内核态后干的时间比较长,阻塞了发出指令的客户端,同样也阻塞了后续发指令的客户端,而这是由 redis 处理网络请求是单线程模型决定的!
线程是操作系统为用户提供的最轻便的并发模型,它的轻便来自于和进程的对比,二者在资源的使用上不可同日而语。即便如此,线程的资源占用仍然相当可观。从资源的有限性出发,不可能为了并发而创建任意数量的线程。除去堆栈资源累加产生的内存占用之外,过多的线程数量也会加重内核调度的负担,这种负担体现在过多指令浪费在进程切换上,而没有为真正的程序逻辑所用。
对高并发的执着追求,诞生了编程语言世界里五花八门的协程,或者说用户态线程,概念并不重要,重要的是,它们只能在用户态做文章。像Python、Java、C++、Go、Rust 等语言都提供了基于协程的并发模型,这里面由于 Go 是相对比较新生的语言,没有任何历史包袱,从而提供了完美的用户态线程,且将此并发模型内置于语言自身。这样做的好处是,开发并发程序变得异常简单,一个简简单单的go关键字就可以创建一个独立的任务,即一个独立的执行流,如果换做其它语言,想要创建一个独立的执行流只有线程或者进程这种由操作系统提供的原生方式(当然,很多语言也有对应的协程库,因本人未做过详细研究,故只考虑原生的并发模型);然而,为了并发体系的自洽,Go 为其用户屏蔽了操作系统提供的线程模型,虽然用起来简单了,但理解上却多了些许障碍。
5
《操作系统概念》4.3节简单讨论了线程模型,书中说有两种不同的方法来提供线程支持,用户层的用户线程和内核层的内核线程,大致有如下三种模型
多对一模型
![图 5-1 多对一模型]()
这种模型将用户态的多个线程映射到一个内核线程上,这种方式最大缺点就是任何一个用户线程发生阻塞调用时,整个内核线程就会被调离 CPU ,致使其它的用户线程失去执行机会。
一对一模型
![图 5-2 一对一模型]()
一对一模型将每个用户线程映射到一个内核线程,如果一个线程阻塞在系统调用上时,剩余的仍然可以运行。这种模型唯一的缺点是创建一个用户线程就需要创建对应的内核线程,可以想见的是,创建内核线程的时间开销和资源开销是相当可观的,换句话说,成本决定了能开启线程的数量。Liunx和windows都实现了一对一的模型。
多对多模型
![图 5-3 多对多模型]()
对多对模型多路复用多个用户级线程到多个内核级线程,通常来说用户线程要比内核线程多的多,这种模型没有上述两种模型的缺点,当一个用户线程发出导致内核线程阻塞的系统调用时,其余的用户线程依然可以被其它内核线程调度。同时,因为用户线程无比轻量,时间和资源成本较少,因此可以开启任意数量的用户线程用于并发,当然量变会引起质变,数量过于庞大的用户线程也会加重资源的消耗,因此会出现了各种各样的协程池用于刹车。Go 语言的并发模型就实现了这种 M:N 的并发模型,稍后我们会讲到,现在先让我来批判一下《操作系统概念》中的概念模糊问题。
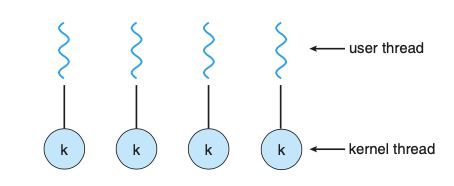
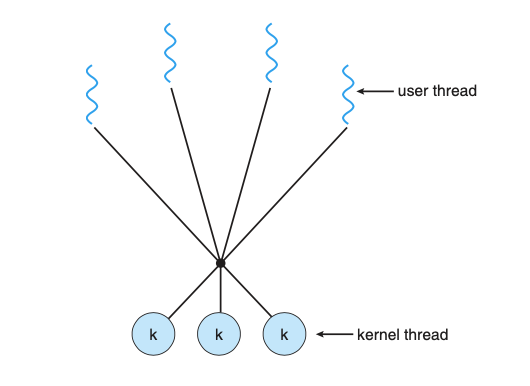
不知道你是否被上面的用户线程、内核线程、映射等概念搅的一头雾水呢?按照其语义,用户线程和内核线程就像是对立的两方,会有某个东西将它们联系起来构成“映射”,或许是内核,又或许是C库,但书中没讲,我能够理解《操作系统概念》是讲操作系统的设计与实现原理,会兼顾大部分操作系统,讲解的也是较为抽象的部分,不过现代绝大部分人只接触过Linux,而Linux内核提供的并发模型就只有一对一这一种,所里书里的内容如今看上去多少有些不合时宜。在 Linux 内核当中甚至并不区分进程和线程,它们统一都由task_struct这一种数据结构表示,并且基于其进行调度,也就是说,在内核看来每个task_struct只有一个执行流,至于在用户态这个大的执行流干些什么,内核并不关心。
要正确理解书中所表达的意图,就需要先把概念捋清楚,我以 Linux 为例来进行说明。
首先,需要把这里的内核线程拿掉,换成操作系统线程,即 Linux 内核提供的线程。我之所以不用内核线程是因为内核线程这个概念在 Linux 中也有对应的存在(参见《深入linux内核架构》2.4.2 内核线程),内核线程是一种只运行在内核地址空间的线程。所有的内核线程共享内核地址空间(对于 32 位系统来说,就是 3-4GB 的虚拟地址空间),所以也共享同一份内核页表,并且没有用户地址空间,这也是为什么叫内核线程,而不叫内核进程的原因。
其次,将用户线程换成协程来表达,这里之所以用协程,完全是因为操作系统线程实在是太耀眼,太深入人心了,以至于人们都忘记了它原本抽象的含义,当需要表达在用户态实现的这个实体时,就有了“用户线程”、“协程”、“go程”等五花八门的名字,特别是“用户线程”,听起来让人如堕五里雾中。
前面讲过,进程是一堆资源和若干执行流的总称,Linux 中的task_struct记录了分配的资源和执行流的状态,是一个勉强能够被称之为进程或者线程的实体,协程也有记录资源和执行流状态的对应实体,从这些“实体”的意义上讲,也可以称协程和操作系统线程之间存在对应关系。现在让我们重新理解一下“对多对模型多路复用多个用户级线程到多个内核级线程”这句话,可以换一种表达:对多对模型指的是在多个Linux操作系统线程之内运行多个协程。我这里使用了“之内”而不是“之上”,是想着重表达操作系统进/线程是一个罐罐儿,用户态的所有花样都是在罐罐儿里玩,并没有超出操作系统进/线程的活动范围。一言以蔽之,用户态程序永远无法逃脱进程地址空间和执行流的手掌心!
或许,我们可以换个角度,抛开这些定义,站在 CPU 的角度去理解问题。所谓线程就是内核维护的一个数据结构,内核依靠这个结构来控制 CPU 上运行的代码,指令无论在用户态还是内核态,都是这个线程,所有的资源消耗都计入此线程,即便是与此线程无关的中断所消耗的资源也被记在该线程名下。协程就是用户空间代码维护的一个数据结构,用户空间代码可以通过控制 ip、sp 等寄存器来控制用户空间执行流的走向,就可以实现在不同的协程间切换,并把执行流的状态记录在对应的数据结构上,重要的是协程代码本身就属于操作系统用户态执行流中的指令。
协程和操作系统线程 M:N 的这种模型,现实中实现并不多,Go 绝对是最耀眼的那一颗!
6
go runtime 中也有和操作系统内核类似的schedule(),它会在最终调用用汇编代码写成的runtime·gogo(buf *gobuf),正如《溯源 goroutine 堆栈》 中提到的,它会将新的 goroutine 恢复执行,最后的指令JMP BX意味着schedule()函数不会返回,schedule()总是会在合适的点被调用,直到选择出可以运行的 goroutine。如果一个 goroutine 自然终止,执行流也会回到事先埋好的点runtime·goexit,而 goexit 最终会调用schedule()。在通往schedule()的调用路径中总会有 runtime·mcall的身影,ip、sp 等寄存器的内容就是在此处被保存,并最终在schedule()中被恢复。
经过上面这些铺垫,我们可以从指令的视角在宏观上来理解一下 go 的协程运作过程:
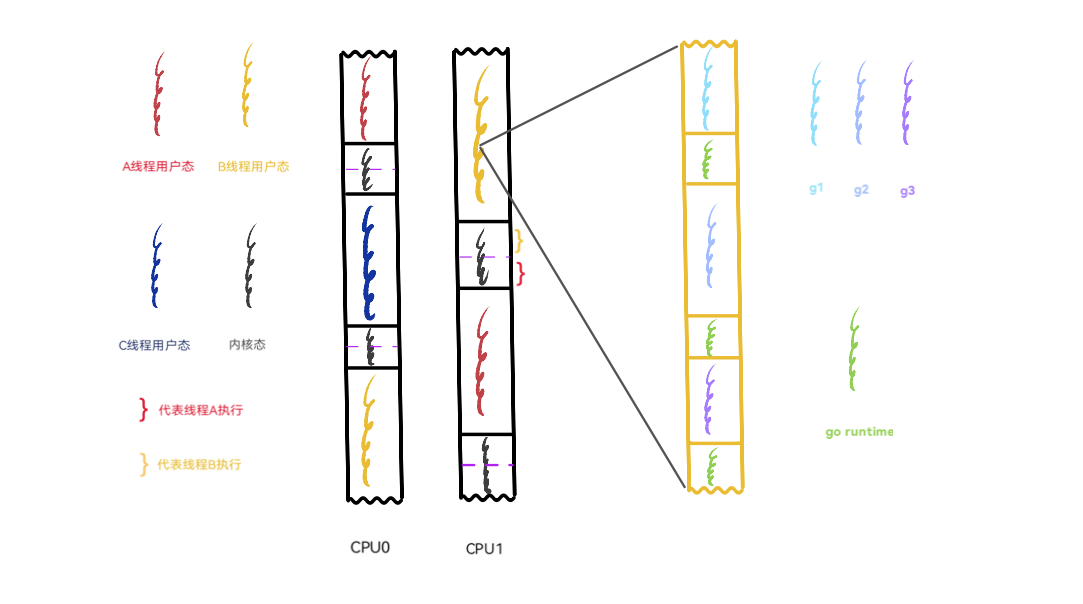
仍然以前面展示进程切换时的图作为基础,为了配合 Go 的实际情况,将图中的进程换成线程来讲。现在想象一下,线程 A、B、C 是 go 程序底层的操作系统线程(GMP中的M),g1、g2、g3 为 go 程序在用户空间实现的协程,或者说叫 goroutine。值得注意的是,内核并不知道 goroutine 的存在,它仍然按照自己一贯的行为方式对 A、B、C 三个线程进行调度。
当A线程的时间片用完,或者发出阻塞的系统调用时,就会被内核调度出 CPU,继而把 C 线程调度到 CPU 上来执行。图中显示 A线程被换下 CPU0 的时候,B 线程仍然在 CPU1 上,这意味着其余的 goroutine 依然会得到执行的机会。再看被调度到 CPU0 上的 C 线程,它也是 go 程序底层的线程,这意味着在一个拥有双核的机器上,goroutine 总是有机会运行的,即便有些 goroutine 因为系统调用等某些原因导致其所在的操作系统线程被换下。go 总会保证有两个“活的”的线程一直待在 CPU 上轮番寻找 goroutine 来执行,除非操作系统内核看不下去,换其它的程序线程来执行,但 go 总会保证有两个准备好的线程可以随时被内核调度。
再来切一下近景,把 B 线程放大。在内核看来,黄色部分只代表 B 线程的用户态执行流,但就在这个黄色用户态执行流的内部正在轮番上演形形色色的任务,g1、g2、g3 三个 goroutine 正轮流在CPU上执行,绿色执行流代表 go 的 runtime,正是 runtime 居中调度,指挥得当,才让以 goroutine 为单位的任务都获得执行的机会。内核对这些一无所知,CPU也只会觉得奇怪:这个线程的用户态代码怎么老是频繁的切换堆栈?(见《溯源 goroutine 堆栈》 中对 go 协程堆栈的描述)
这种并发模型的优势显而易见,让我们来直观地感受一下。操作系统线程每次上下文切换需要大约 1000ns 的时间,而硬件有望在每纳秒的时间里执行 12 条指令,也就是说,当任务必须等待时,操作系统就会花费 12k 条指令去做线程切换,却不能将这些指令用在有意义的业务上。而 go 在用户态进行协程切换,极大地缓和了这种浪费,go 进行一次协程切换大概需要 200ns 或者 2.4k 条指令。简言之,go 用尽可能少的 os 级的线程调度来做更多的事情,方式就是在用户空间调度,这是语言级别的一种能力,可不严谨的说,go 的调度比 os 级调度便宜 5 倍,甚至更多!
操作系统内核之所以可以大胆地把 CPU 的使用权交给用户态程序,是因为时钟中断总会让控制权重归内核。那么,完全运行在用户态的 runtime 是如何获得控制权来调度 goroutine 的呢?go1.14 之前确实没办法做到,控制权的转移完全依靠 goroutine 的主动放弃,通过 runtime.Gosched 调用主动让出执行机会,或者当发生执行栈分段时,检查自身的抢占标记,决定是否继续执行;其中第二种情况是通过编译器编译时在函数调用之前插入指令来实现的,也就是说只有在 goroutine 发生函数调用时,runtime 才会获得短暂的执行权来实施调度。不难想见的是,下面这种无函数调用的代码会导致 goroutine 永远霸占 CPU,runtime 根本得不到执行的机会:
1 | // 此程序在 Go 1.14 之前的版本不会输出 OK |
换句话说,这种调度方式属于协作式调度,完全依赖执行方的主动弃权;为此,go1.14 基于操作系统信号实现了异步抢占,之所以叫异步,是因为从发送信号到信号被处理这个过程是异步的,并不同步。我这里不准备讲信号的安装、信号的发送逻辑,仅就信号的处理捡扼要处略作说明,感兴趣的朋友可以参考从源码剖析Go语言基于信号抢占式调度这篇文章。
既然 go 的异步抢占处理是基于操作系统信号的,那么在进入go 的处理之前,先来看看操作系统是如何处理信号的吧!
7
请允许我略过对信号繁琐的介绍,直接从进/线程注意到一个信号到来开始。
每个进程从内核态返回用户态之前都会检查TIF_SIGPENDING标志的值,也就是说,每当内核处理完一个中断或异常后,在返回用户态之前都会检查是否存在挂起信号;为了处理信号,内核会调用do_signal()函数,我们假设这个信号安装了专门的处理程序,do_signal()函数必须强迫该处理程序的执行,这是通过handle_signal()进行的。
难点在于,信号处理程序属于用户空间代码,内核不能直接执行用户代码,要执行用户态的信号处理程序,内核必须返回用户态,而一旦返回用户态,内核栈上的内容就会被清空(内核态堆栈包含了被中断进程的硬件上下文),当信号处理程序执行完毕时,又该如何回到正常的执行流程上呢?另外的复杂性是信号处理函数可以执行系统调用,依然要到内核态逛一圈再回到用户态,并且是回到信号处理程序,而不是回到进程原本的正常执行流。
Linux 采用的解决方案是把保存在内核态堆栈中的硬件上下文拷贝到当前进程的用户态堆栈中(稍后会看到go的信号处理抢占程序是如何利用这一点的)。用户态的堆栈也会被修改,使得信号处理函数执行完毕之后,自动调用sigreturn()系统调用把硬件上下文拷贝回内核态堆栈中,并恢复用户态堆栈中原来的内容。
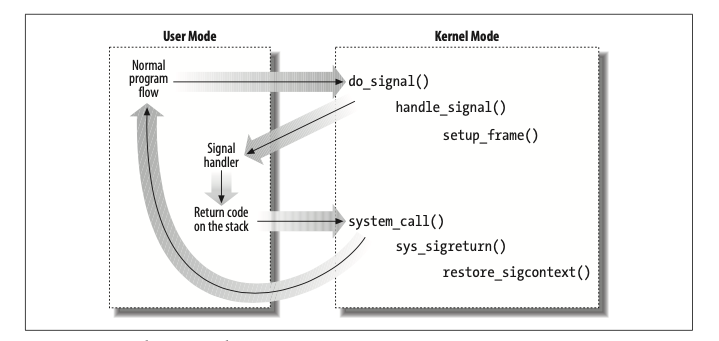
图 7-1 说明了进程处理信号时的执行流,当中断或者异常发生的时候,进程陷入内核。在要返回用户态之前,执行了do_signal()函数,并开始处理信号(调用handle_signal()),在用户态堆栈上建立栈帧(调用setup_frame()或setup_rt_frame)。
因为进入内核态时,用户态的寄存器值已被保存到内核态的堆栈上了,所以内核很容易拿到用户态堆栈的地址,并加以修改。建立的栈帧如下图所示:
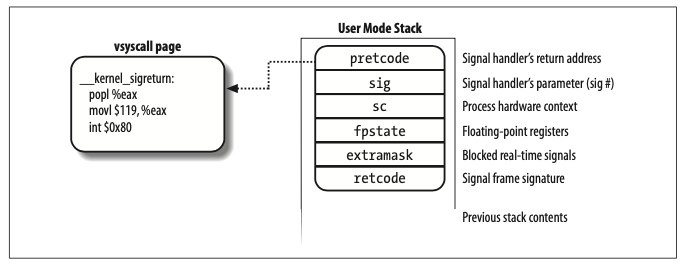
其中sc中保存了进程的硬件上下文,这是从当前进程的内核堆栈上 copy 来的。precode位于栈顶,是信号处理函数的返回地址,将会发出sigreturn()系统调用。
当栈帧构造完成之后,内核需要修改保存在内核态堆栈上用户态寄存器程序计数器的值,让它指向信号处理程序,这样返回用户态之后就会跳转到信号处理程序处执行了:
1 | regs->esp = (unsigned long) frame; |
这段代码来自《深入理解Linux内核》,大概是 2.6 版本的代码,我找了一下 5.10 版本的内核,其中设置用户栈和寄存器的函数是setup_signal_stack_si,我摘录其中修改内核栈中用户态硬件上下文的内容如下:
1 | PT_REGS_SP(regs) = (unsigned long) frame; |
除了设置堆栈、程序计数器之外也设置了 rdi、rsi、rds 这几个寄存器,这是 x86_64 架构下 C 语言的函数调惯例,三个寄存器分别用于存放函数调用时前三个参数。记住这一点,后面介绍 Go 时会用到。
之后,再经过一系列检查,handle_signal()返回到do_signal(),do_signal()返回到用户态,因为程序计数器指向信号处理程序的第一条指令,而栈顶指向已推进用户态堆栈的第一个内存单元。因此,信号处理程序被执行。
信号处理程序结束时,返回栈顶地址,该地址指向栈帧的precode字段所引用的vsyscall页中的代码:
1 | _ _kernel_sigreturn: |
它发出一个系统调用,再次陷入内核,调用restore_ sigcontext( ) 函数,将 sc 中记录的硬件上下文恢复到内核态堆栈,并从用户态堆栈删除之前建立的栈帧,之后返回用户态,程序的执行流开始回到中断之处继续执行。
稍后我们会看到,内核从 sc 恢复的内容是被 go 的 runtime 修改过的!
有这些内容做铺垫,就可以聊一聊 go 的信号抢占了!
8
go 在 M 上通过initsig()来初始化信号,对于需要安装处理程序的信号,会通过setsig来设置对应的动作,真正执行抢占动作的是doSigPreempt,此时的调用栈为:
1 | sigtramp-->sigtrampgo-->sighandler-->doSigPreempt |
doSigPreempt有个*sigctxt类型的参数,它表示的是我们上一节介绍过的内核保存在用户态堆栈的内核态堆栈内容(比较拗口,需要多读几遍),其中存放的是当前进程用户态的硬件上下文。这个参数是从sigtramp一路传下来的,我们看一下sigtramp的代码:
1 | // Called using C ABI. |
sigtramp实际上是真正的信号处理函数,进程从内核态收到信号回到用户态调用的处理函数就是它,注释中表明这个函数以 C 语言的调用惯例被调用,Go 在这里通过PUSH_REGS_HOST_TO_ABI0保存 go 自己调用惯例用的寄存器后,转换成自己的调用规范,等函数调用完毕之后,再通过POP_REGS_HOST_TO_ABI0恢复这些寄存器的值。
还记得上一节介绍 5.10版本的内核修改用户态寄存器时设置的 rdi、rsi、rdx 的值吗?这三个寄存器的值就是内核模仿调用sigtramp时传入的参数,现在 go 需要以自己的调用规约将其放置到堆栈上,来表示 sig、info、ctx 这三个参数(go1.17 改变了调用规约,已经由堆栈传递参数改为寄存器传递了,不知道为何此处仍然使用堆栈传递,我此处引用的代码是版本 1.18.1)。
当调用到doSigPreempt时,会将ctx这个参数传入,其中包含了进程用户态硬件上下文,希望你还记得这一点。
1 | // doSigPreempt handles a preemption signal on gp. |
信号处理程序一旦被执行,舞台就交到了 go runtime 手里,ctxt的类型为*sigctxt,指向的是用户态堆栈中存放内核态堆栈内容的地址。然后信号处理程序通过isAsyncSafePoint来判断抢占位置是否安全,并返回安全的抢占地址。如果确认抢占没有问题,接着会调用pushCall方法来修改ctxt中的用户态硬件上下文,用于稍后再一次从内核态返回用户态时模拟出一个用户态程序调用asyncPreempt的假象:
1 | func (c *sigctxt) pushCall(targetPC, resumePC uintptr) { |
pushCall干了两件事:
- 修改程序计数器的指向为
asyncPreempt函数的地址。 - 修改栈顶指针,将当前 goroutine 的原本中断地址放入堆栈。
细心的你可能会问:内核在跳转信号处理程序之前不是已经拓展了堆栈,往里面塞了一个frame么?go runtime 在这里基于原始的栈顶再往里塞一个返回地址,不会引起冲突么?
确实不会引起冲突,因为在 X86-64 调用规范中有一个重要标准——红色区域(Red zone)。它指出:在 rsp 指向的栈顶之后的128 字节被保留,不能被信号和中断处理程序使用,因此我们可以在 Linux 的源码中看到如下处理:
1 | struct rt_sigframe __user *frame; |
内核在构造这个frame的时候留出了 128 字节的空隙,go runtime 见缝插针,将当前 goroutine 被中断时的下一条指令地址放入堆栈。这一套移花接木的功夫打完,信号处理函数执行完毕返回内核态,内核重新恢复原内核态堆栈上的内容,此时的内容是被 go runtime 修改后的。之后,执行流从内核态返回用户态,内核态堆栈被弹出,相关寄存器被恢复,程序计数器指向asyncPreempt,开始运行用户态代码。下面是asyncPreempt的汇编代码,我省略了大部分寄存器的保存和恢复指令:
1 | TEXT ·asyncPreempt(SB),NOSPLIT|NOFRAME,$0-0 |
asyncPreempt保存执行现场后,调用了asyncPreempt2,这里要提一下,CALL ·asyncPreempt2(SB) 指令先将下一条指令的地址入栈再进行跳转,这样栈顶的地址就是asyncPreempt2返回时的地址。
asyncPreempt2会调用mcall函数,最终会执行调度函数schedule(),还记得吗?schedule()不会返回,执行完runtime·gogo(buf *gobuf)后,新的 goroutine 就在 CPU 上运行了,所以我们要看一下mcall函数保存的现场:
1 | // func mcall(fn func(*g)) |
这两句是保存程序计数器的值到g->sched:
1 | MOVQ 0(SP), BX // caller's PC |
可见,保存的地址是栈顶的内容,而此时栈顶内容是函数asyncPreempt中CALL ·asyncPreempt2(SB)的下一条指令,即MOVUPS 352(SP), X15;也就是说,当该 goroutine 再次被调度时,会从asyncPreempt2中继续执行,然后返回到asyncPreempt,asyncPreempt返回时从堆栈弹出将要跳转的地址,而这个地址就是 go 见缝插针塞进来的地址,这看起来就像是 goroutine 调用asyncPreempt一般。执行流走到这里,才真正意义上完成了 goroutine 的恢复执行。
由此观之,asyncPreempt更像是 Linux 内核中的schedule():调度发生在函数执行过程中,而函数执行完毕要等到下一次被调度的时候才会发生。 而 go 借助信号机制所实现的抢占,无非就是依靠信号处理程序这一次控制权埋点,以便在执行流最终从内核态返回时执行asyncPreempt代码,从而再一次收获 CPU 的控制权。
是时候再从指令的视角在宏观上来理解 go 的信号抢占流程了:
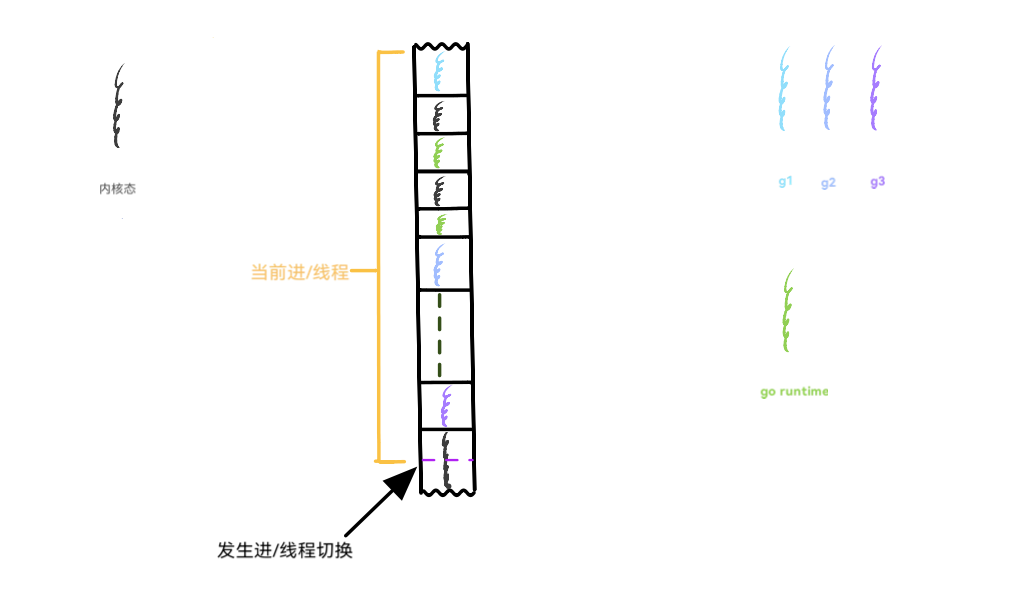
图 8-1 显示了通过异步抢占执行流从 g1 切换到 g2 的过程:
- g1被时钟中断,从内核返回时发现有抢占信号。
- 执行流从内核态返回到用户态,执行信号处理程序(第一个绿色的 go runtime 执行流)。
- 信号处理程序执行完毕返回内核,内核做一些恢复后,再次返回到用户态。
- 从内核态返回后的执行流被 go runtime 窃取,转而执行调度(第二个绿色的 go runtime 执行流)。
- g2 被选择,换上 CPU 执行。
9
文章写到这里,基本上把我想讲的已经讲完了,也算基本上完成了自己“观其大略,本其脉络”的目标,我曾在《从CPU的视角说起》 一文中说道:我目前所寻求的信息,意在建立计算机系统的世界观与 Go 语言的世界观,是在陷入具体细节之前为自己提供一个大致的轮廓,让自己对计算机运行的脉络有一个关键性的认识。 即便如此,里面也不可避免的出现很多具体而微的内容。我略过了很多环节,并不是因为它们不重要,是因为它们是细节,是更丰富的东西,也是我尚未探索的东西。
苏轼有自己的一套读书方法叫做“八面受敌”,他在写给侄女婿王庠的《又答王庠书》中作了详细介绍:“但卑意欲少年为学者,每一书皆作数过尽之。书富如入海,百货皆有,人之精力,不能兼收尽取,但得其所欲求者尔。故愿学者每次作一意求之。如欲求古今兴亡治乱、圣贤作用、但作此意求之,勿生余念。又别作一次,求事迹故实典章文物之类,亦如之。他皆仿此。此虽迂钝,而他日学成,八面受敌,与涉猎者不可同日而语也。”
这段话可谓深得我心,“人之精力,不能兼收尽取,但得其所欲求者尔”、“故愿学者每次作一意求之”,我欲寻求堆栈的本源,翻尽家中藏书,完成了《学渣三部曲》,又执着于调度,翻阅同样的书,才有了这一篇万字长文,此虽迂钝,而他日学成,八面受敌,与涉猎者不可同日而语也。
最后再聊一聊“程序”,第4节曾讨论过“程序”一词的含义,平时我们习惯将开发最终交付的制品称为“程序”,或有“我写了某某程序”之类云云,“程序”若是躺在计算机硬盘中的二进制文件,那当它被调入内存醒来时,一定会哀叹自己生命的不完整,因为每当它想“耳听之而为声,目遇之而成色”的时候,面前总会横着一道“系统调用”的鸿沟,以至于它永远无法亲自触摸“大自然”的无尽藏。换句话说,我们到底创造了什么?一条流动的进程中,有多少是属于我们这样平凡之人的?刨去内核指令,刨去运行时、库以及不可胜数的框架代码,我相信已所剩无几!
我之所以无法骄傲,是因为站在巨人的肩上!
参考文献
- 操作系统导论
- 深入理解计算机系统
- 深入理解LINUX内核
- 深入 Linux 内核架构
- 操作系统概念
- The Definitive Guide to Linux System Calls
- 深入golang runtime的调度
- 从源码剖析Go语言基于信号抢占式调度
- Misc on Linux fork, switch_to, and scheduling
- Evolution of the x86 context switch in Linux
- Go 语言原本
- Scheduling In Go : Part II - Go Scheduler