这是不是说明 range 就是在遍历原fib本身呢?如果是遍历原fib,又为什么这里只循环了 2 次呢?
让我们看看spec中的说明:
The range expression x is evaluated once before beginning the loop, with one exception: if at most one iteration variable is present and len(x) is constant, the range expression is not evaluated.
这里的意思是:在进入循环之前,range 表达式只会计算一次!但这个evaluate具体指何意,spec 没有解答,看来只能在编译器源码中寻找答案了,我是没有大海捞针的精力了,不过已经有人替我们做了,美中不足的是参考的 gcc 的代码,不过想来都遵循语言规约的话,行为方式总是大差不差的,来看看 gcc 的 Go 编译器源码中 range 子句的注释:
1 2 3 4 5 6 7
// Arrange to do a loop appropriate for the type. We will produce // for INIT ; COND ; POST { // ITER_INIT // INDEX = INDEX_TEMP // VALUE = VALUE_TEMP // If there is a value // original statements // }
可见 range 循环仅仅是 C-style 循环的语法糖,所以当你 range 一个 array 时:
1 2 3 4 5 6 7 8 9
// The loop we generate: // len_temp := len(range) // range_temp := range // for index_temp = 0; index_temp < len_temp; index_temp++ { // value_temp = range_temp[index_temp] // index = index_temp // value = value_temp // original body // }
range slice 时:
1 2 3 4 5 6 7 8
// for_temp := range // len_temp := len(for_temp) // for index_temp = 0; index_temp < len_temp; index_temp++ { // value_temp = for_temp[index_temp] // index = index_temp // value = value_temp // original body // }
我们可以从中得到至少4点启示:
循环最终都是 C-style 的。
循环遍历的对象都会被赋值给一个临时变量。
由第 2 点可知,range 一个数组的成本要大于 range 切片。
for range 居然涉及到 2 次 copy,一次是 copy 迭代的对象,一次是集合中的元素 copy 到临时变量。
我们还原一下开篇提到的代码,大致是如下的样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fib := []int{0, 1}
var f1 int // copy 迭代对象 temp := fib for i := 0; i < len(temp); i++ { // copy 元素 f1 = temp[i] f2 := fib[i+1] fib = append(fib, f1+f2) if f1+f2 > 100 { break } } fmt.Println(fib)
If a map entry that has not yet been reached is removed during iteration, the corresponding iteration value will not be produced. If a map entry is created during iteration, that entry may be produced during the iteration or may be skipped.
概括来说,你可以在 range 循环中对 map 进行增删,删掉的元素不会在接下来被遍历到,增加的元素则不一定,也许会被遍历,也许不会,这是由 map 底层使用哈希表实现以及随机遍历机制决定的。
参考文献:
The Go Programming Language Specification
Go Range Loop Internals
Does Go's range Copy a Slice Before Iterating Over It?
我们这里不谈艺术不谈性能,仅仅从创作者与写作者的心智负担轻重角度讨论。对于写作,你当然无法同时去写几件事情,我在读金庸先生的作品时曾留意过他的叙事手法:剧情先是沿着主线流淌,因为某些事件的发生,几个人物分离,主线会择其中一人继续流淌,在未来的某个时间点会再次汇集,此时金庸先生会采用中断的方式,倒回去叙述另一人物的剧情,一直到交叉点为止。当然有些作者会采用多线叙事法,几处剧情同时进行,读者要在这几处剧情中几进几出,最后在某处汇集,但在作者的角度就是类似于一个单核 CPU 进行并发。
Go 语言的协程极大地拓展了这个上限,使得表达复杂事物变得简单了。大部分的场景你都可以给每一个小事安排一个房子,你不用再为了给它寻找位置而煞费苦心,你可以用大量的线条去勾勒一个复杂的整体,该添一笔的地方千万不要吝啬。毫无疑问,这降低了你的创作难度,你可以肆无忌惮地去表达你心中那个浑凝的整体,用一种近似浑凝的方式!
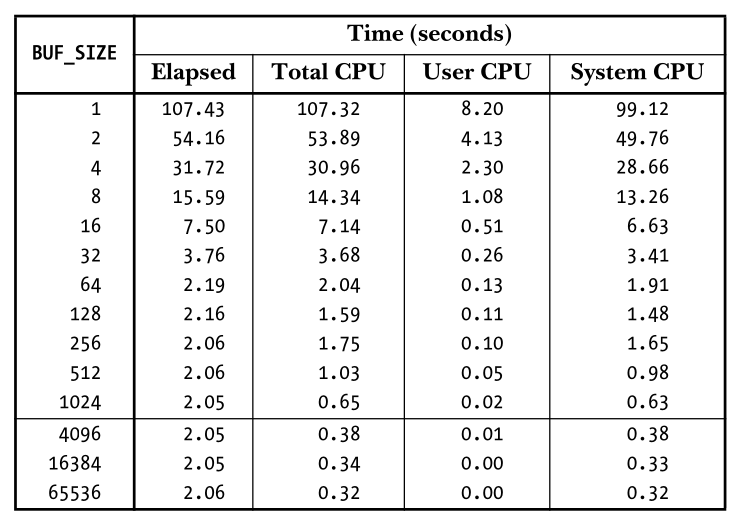
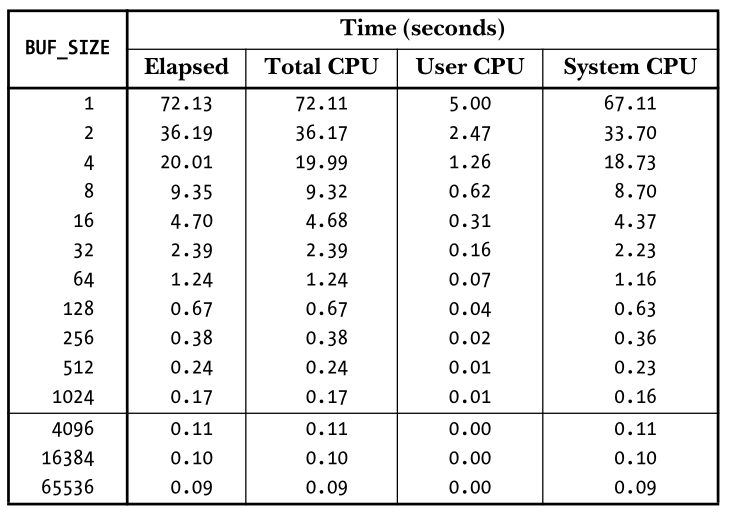
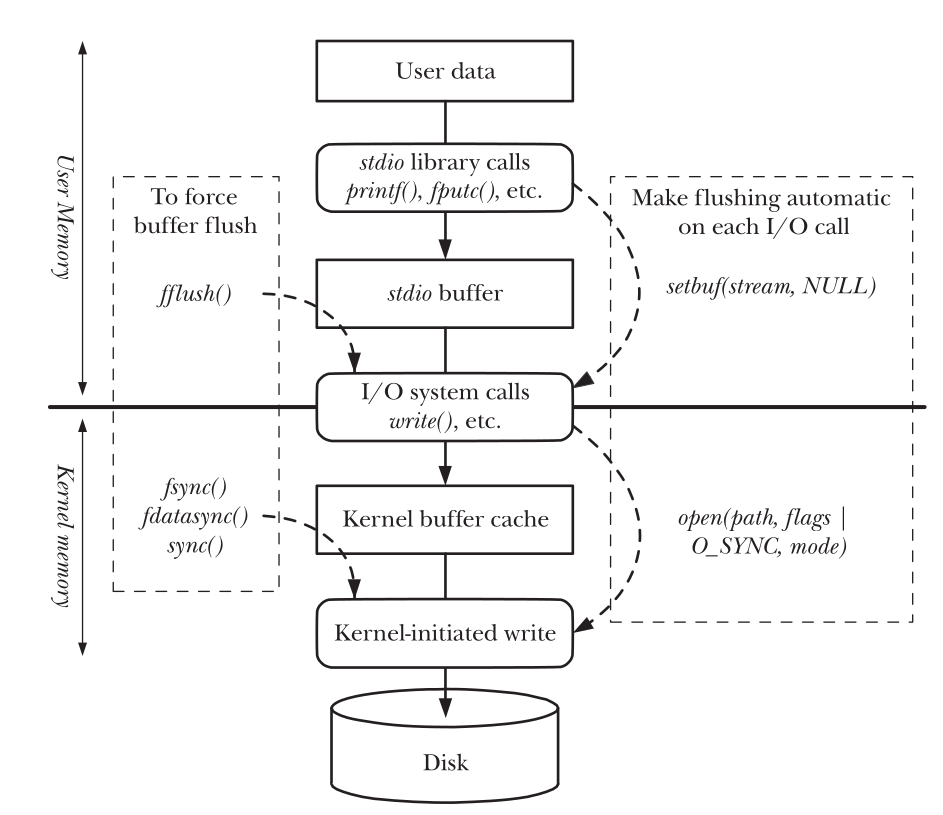
#include<unistd.h> ssize_tread(int fd, void *buffer, size_t count); Returns number of bytes read, 0 on EOF, or –1 on error ssize_twrite(int fd, void *buffer, size_t count); Returns number of bytes written, or –1 on error
这是 glibc 对系统调用read、write的封装,大部分应用的 IO 都是对这两个封装函数的调用,即便是不使用 C 库的语言,其标准库也提供对系统调用read、write的封装,比如 Go 语言,其标准库底层直接对接的系统调用,与 glibc 处于同一层级。
void _isatty(){ if (isatty(fileno(stdout))) { printf("stdout is connected to a terminal (line buffered)\n"); fprintf(stderr,"an error painted to stderr\n"); } else { printf("stdout is not connected to a terminal (fully buffered)\n"); fprintf(stderr,"an error painted to stderr, but redirected\n"); } }
Most computer programs are executed in the same order in which they are written. The first line executes, then the next, and so on. With synchronous programming, when a program encounters an operation that cannot be completed immediately, it will block until the operation completes. For example, establishing a TCP connection requires an exchange with a peer over the network, which can take a sizeable amount of time. During this time, the thread is blocked.
With asynchronous programming, operations that cannot complete immediately are suspended to the background. The thread is not blocked, and can continue running other things. Once the operation completes, the task is unsuspended and continues processing from where it left off. Our example from before only has one task, so nothing happens while it is suspended, but asynchronous programs typically have many such tasks.
Although asynchronous programming can result in faster applications, it often results in much more complicated programs. The programmer is required to track all the state necessary to resume work once the asynchronous operation completes. Historically, this is a tedious and error-prone task.
With asynchronous programming, operations that cannot complete immediately are suspended to the background,不能继续的任务,要被扔到后台。
The thread is not blocked, and can continue running other things,底层线程不因此而阻塞,继续运行其它任务。
Once the operation completes, the task is unsuspended and continues processing from where it left off,当被异步的操作完成后,被终止的任务恢复执行。
Rayon 默认只使用与 CPU 数量相同的线程来执行任务,执行效率反而比 Tokio 略好,Tokio 因为启动了大量的线程,导致我的电脑已无法正常响应键鼠了。
Object
区间
总耗时
平均
Go
676 s ~ 814 s
814 s
81.4 ms
Tokio
0.6 s ~ 564 s
564 s
56.4 ms
Rayon
0.00420079 s ~ 503 s
507 s
50 ms
由于例子的特殊性,在总的执行时间上,Go 没有任何优势可言,因为 Go 和 Rust 的定位不同,性能也有差距,所以比较总耗时并没有意义。我们这里主要观察每个任务的耗时区间。
这里有意思的是 Go 的所有任务耗时趋向于“平均”,而 Rust 的两个框架是在每个线程上串行执行任务,任务耗时如同信号图标📶,由低到高渐进式增长。
所以,如果计算任务之间没有依赖,更看重总的响应时间的话,使用与 CPU 核数相当的线程池进行并行计算能得到最佳效果;如果任务是并发的,更加注重单个任务的响应时间,类似于 Go 的并发模型可能是更好的选择。本文所举的示例,每个任务的计算量相当,并不能体现 Go 的这一优势,不过可以想象一下:并发途中,一个计算量很小的任务加入队列,上述两种任务处理方式会给出不同的结果。
Go 是为并发而生的语言,所以你会发现,在编写 Go 代码的时候,你根本不用去考虑并发任务是计算型还是 I/O 型的,在其并发模型下所有的任务都会尽可能得到及时的处理;而对于缺乏完善调度运行时的线程池来说,其注意事项就很多了,你要小心翼翼,不能在异步任务中写太多计算的代码。对此,甚至有博主指出:在进入.await之前,最好不要超过10 ~ 100 微秒。
道理不难理解,以 Tokio 为例,虽然可以运行 CPU 密集型任务,但是官方很明确的说你要新开实例去运行,不要饿死 I/O 任务,显然这是因为运行时缺乏调度能力的折中方案。CPU 密集型任务属于会阻塞 executor 线程的任务,容易霸占 CPU 而饿坏或者饿死其它任务,此时只能靠手动 yield 来让出 CPU,给其它任务以运行的机会;而网络 I/O 之所以适合,完全是因为有非阻塞特性和 Reactor 的存在,每个 I/O 读写点都是一次 yield 的机会!
Linux 内核也有原生的异步 I/O 支持,并冠以AIO之名,但限制很多,如只支持O_DIRECT访问、只支持特定设备、性能表现不佳等等,社区满意度极低,饱受诟病,我甚至找不到异步网络 I/O 的例子,因此可以说,当前 Linux 只支持有限的文件异步 I/O,不支持网络异步 I/O(至少没有应用场景)。
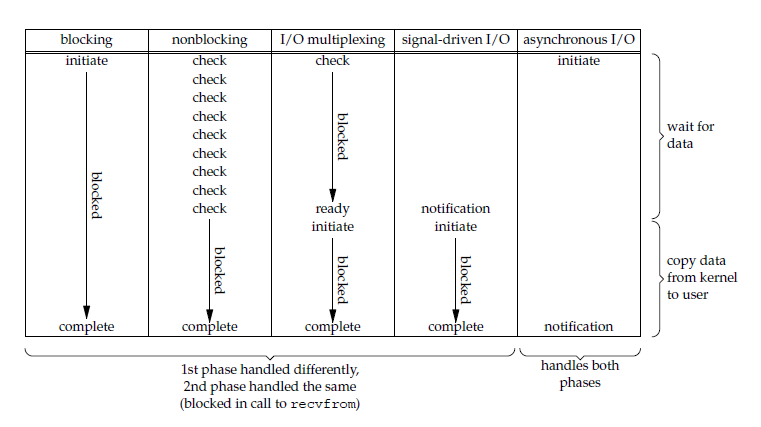
要知道,在异步 I/O 的概念出现之前,还有一种中间形态——IO 多路复用。
直到现在,IO 多路复用依然是 Linux 平台高并发网络的主流解决方案,以epoll为支点的事件循环结构铸就了当今互联网绝大多数网络程序的 Reactor模型。
I/O 多路复用
我们可以用非阻塞+单线程或多线程的网络模型来处理大量网络连接,但是由于需要浪费 CPU 来试探缓冲区是否就绪,所以效率难免会大打折扣。
// Wrapper around the accept system call that marks the returned file // descriptor as nonblocking and close-on-exec. funcaccept(s int) (int, syscall.Sockaddr, string, error) { ns, sa, err := Accept4Func(s, syscall.SOCK_NONBLOCK|syscall.SOCK_CLOEXEC) if err != nil { return-1, sa, "accept4", err } return ns, sa, "", nil }
// netpollready is called by the platform-specific netpoll function. // It declares that the fd associated with pd is ready for I/O. // The toRun argument is used to build a list of goroutines to return // from netpoll. The mode argument is 'r', 'w', or 'r'+'w' to indicate // whether the fd is ready for reading or writing or both. // // This may run while the world is stopped, so write barriers are not allowed. // //go:nowritebarrier funcnetpollready(toRun *gList, pd *pollDesc, mode int32) { var rg, wg *g if mode == 'r' || mode == 'r'+'w' { // 获取等待读操作的 g rg = netpollunblock(pd, 'r', true) } if mode == 'w' || mode == 'r'+'w' { // 获取等待写操作的 g wg = netpollunblock(pd, 'w', true) } if rg != nil { // 将等待读操作的 g 插入链表 toRun.push(rg) } if wg != nil { // 将等待写操作的 g 插入链表 toRun.push(wg) } }
type pollDesc struct { ... // rg, wg are accessed atomically and hold g pointers. // (Using atomic.Uintptr here is similar to using guintptr elsewhere.) rg atomic.Uintptr // pdReady, pdWait, G waiting for read or nil wg atomic.Uintptr // pdReady, pdWait, G waiting for write or nil ... }
rg 和 wg 都是原子类型,里面可能存放的内容为:pdReady, pdWait, G waiting for read or nil,G 就是 goroutine 的地址,我们继续沿着调用向下看:
for { old := gpp.Load() if old == pdReady { returnnil } if old == 0 && !ioready { // Only set pdReady for ioready. runtime_pollWait // will check for timeout/cancel before waiting. returnnil } varnewuintptr if ioready { new = pdReady } // 将 gpp 设置为 pdReady if gpp.CompareAndSwap(old, new) { if old == pdWait { // 如果设置为0,则 (*g)(unsafe.Pointer(old)) 为 nil old = 0 } // 将 old 的值转换为 *g 返回,old 通常就是发生等待的 goroutine 地址 return (*g)(unsafe.Pointer(old)) } } }
拿到 *g 之后,就可以插入toRun链表了:
runtime/proc.go
1 2 3 4 5 6 7 8 9 10 11
// A gList is a list of Gs linked through g.schedlink. A G can only be // on one gQueue or gList at a time. type gList struct { head guintptr }
// push adds gp to the head of l. func(l *gList) push(gp *g) { gp.schedlink = l.head l.head.set(gp) }
// The main goroutine. funcmain() { ... if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon systemstack(func() { newm(sysmon, nil, -1) }) } ... }
// Always runs without a P, so write barriers are not allowed. // //go:nowritebarrierrec funcsysmon() { ... for { ... // poll network if not polled for more than 10ms lastpoll := int64(atomic.Load64(&sched.lastpoll)) if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) list := netpoll(0) // non-blocking - returns list of goroutines if !list.empty() { // Need to decrement number of idle locked M's // (pretending that one more is running) before injectglist. // Otherwise it can lead to the following situation: // injectglist grabs all P's but before it starts M's to run the P's, // another M returns from syscall, finishes running its G, // observes that there is no work to do and no other running M's // and reports deadlock. incidlelocked(-1) injectglist(&list) incidlelocked(1) } } ... } }
// returns true if IO is ready, or false if timedout or closed // waitio - wait only for completed IO, ignore errors // Concurrent calls to netpollblock in the same mode are forbidden, as pollDesc // can hold only a single waiting goroutine for each mode. funcnetpollblock(pd *pollDesc, mode int32, waitio bool)bool { gpp := &pd.rg if mode == 'w' { gpp = &pd.wg }
// set the gpp semaphore to pdWait for { // Consume notification if already ready. if gpp.CompareAndSwap(pdReady, 0) { returntrue } if gpp.CompareAndSwap(0, pdWait) { break }
// Double check that this isn't corrupt; otherwise we'd loop // forever. if v := gpp.Load(); v != pdReady && v != 0 { throw("runtime: double wait") } }
// need to recheck error states after setting gpp to pdWait // this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl // do the opposite: store to closing/rd/wd, publishInfo, load of rg/wg if waitio || netpollcheckerr(pd, mode) == pollNoError { // 开启 park 流程,休眠当前 goroutine gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5) } // be careful to not lose concurrent pdReady notification old := gpp.Swap(0) if old > pdWait { throw("runtime: corrupted polldesc") } return old == pdReady }
netpollblock会将pollDesc中的 rg 或 wg 设置为pdWait,然后调用gopark将当前 goroutine 休眠,进入schedule流程挑选新的 goroutine 来运行。
// Puts the current goroutine into a waiting state and calls unlockf on the // system stack. // // If unlockf returns false, the goroutine is resumed. // // unlockf must not access this G's stack, as it may be moved between // the call to gopark and the call to unlockf. // // Note that because unlockf is called after putting the G into a waiting // state, the G may have already been readied by the time unlockf is called // unless there is external synchronization preventing the G from being // readied. If unlockf returns false, it must guarantee that the G cannot be // externally readied. // // Reason explains why the goroutine has been parked. It is displayed in stack // traces and heap dumps. Reasons should be unique and descriptive. Do not // re-use reasons, add new ones. funcgopark(unlockf func(*g, unsafe.Pointer)bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) { if reason != waitReasonSleep { checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy } mp := acquirem() gp := mp.curg status := readgstatus(gp) if status != _Grunning && status != _Gscanrunning { throw("gopark: bad g status") } // 此时 lock 是 gpp(pollDesc 中的 rg) mp.waitlock = lock // 此时 unlockf 是 netpollblockcommit mp.waitunlockf = unlockf gp.waitreason = reason mp.waittraceev = traceEv mp.waittraceskip = traceskip releasem(mp) // can't do anything that might move the G between Ms here. mcall(park_m) }
// func mcall(fn func(*g)) // Switch to m->g0's stack, call fn(g). // Fn must never return. It should gogo(&g->sched) // to keep running g. TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8 MOVQ AX, DX // DX = fn
// save state in g->sched // 下面这 5 行指令是保存当前 goroutine 的状态到 g->sched MOVQ 0(SP), BX // caller's PC MOVQ BX, (g_sched+gobuf_pc)(R14) LEAQ fn+0(FP), BX // caller's SP MOVQ BX, (g_sched+gobuf_sp)(R14) MOVQ BP, (g_sched+gobuf_bp)(R14)
// switch to m->g0 & its stack, call fn // 准备切换到 g0 及其堆栈 MOVQ g_m(R14), BX // 通过 R14 拿到当前的 m MOVQ m_g0(BX), SI // SI = g.m.g0 通过 m 拿到 m 的 g0 CMPQ SI, R14 // if g == m->g0 call badmcall JNE goodm JMP runtime·badmcall(SB) goodm: MOVQ R14, AX // AX (and arg 0) = g 把当前 goroutine 地址放入 AX MOVQ SI, R14 // g = g.m.g0 SI 是 g.m.g0,这一句将 goroutine 切换到 g0 get_tls(CX) // Set G in TLS MOVQ R14, g(CX) // 设置 g0 到线程本地存储 MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp 切换到 g0 堆栈 PUSHQ AX // open up space for fn's arg spill slot MOVQ 0(DX), R12 CALL R12 // fn(g) POPQ AX JMP runtime·badmcall2(SB) RET
根据Go internal ABI specification的描述,amd64平台下整型参数传递依次使用如下寄存器:
不知道你有没有好奇,挂起的明明是当前的 goroutine,为什么函数的名字是park_m呢?这里的m显然就是 GMP 中的线程 M 啊,我是这样理解的:M 就像是一列高速运行的汽车,乘客是goroutine,当某个乘客因某些原因不能继续乘坐时,M 需要停下来让乘客下车,然后再开动去寻找下一位乘客,所以这个挂起 goroutine 的过程就像是 M 停泊了一样。
但为了叙述方便,我还是称 goroutine 停泊好了,毕竟比喻并不十分恰当,从指令角度看 M 可是一路狂奔从未停过,只是从代码所有权角度来看, M 确实是换了一位乘客。
runtime/netpoll.go
1 2 3 4 5 6 7 8 9 10
funcnetpollblockcommit(gp *g, gpp unsafe.Pointer)bool { r := atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp))) if r { // Bump the count of goroutines waiting for the poller. // The scheduler uses this to decide whether to block // waiting for the poller if there is nothing else to do. atomic.Xadd(&netpollWaiters, 1) } return r }
反观文件 I/O 则不然,文件 I/O 没有异步和非阻塞特性(不考虑臭名昭著的AIO),当 M 因为系统调用陷入内核时,如果要读取的内容不在页高速缓存中,就会触发缺页处理,内核需要向磁盘发出 I/O 请求,因为这个过程不是异步的,内核会将 M 剥离,调度其它线程来运行。可想而知,此时此刻 go runtime 只能新建 M 来匹配 P,新建的 M 需要加入内核运行队列,等待内核调度,经过这样一番折腾,吞吐自然就下来了。
更可怕的是如果有大量 I/O 请求,势必会让更多的 M 陷入内核无法自拔,go runtime 除了创建更多的 M 之外别无良策,在这种情况下仍不断地创建 M 无异于扬汤止沸,如果 M 的数量超过 1 万,程序就 panic 了。