异步 I/O 探秘 —— 为什么说 Go 为我们提供了同步的网络编程接口 ?
本文主要讲述了我对 I/O 的一些理解,剖析了 Go 语言
netpoller是如何结合 epoll 和 goroutine 的,文章还简单畅想了 io_uring 可能会带来的改变,并阐述了我对于异步编程的一点浅陋思考,希望能跟大家一起探讨。
作为 Gopher,你想必听过“Go 为我们提供了同步的网络 I/O 编程接口”,或者“Go 为我们提供了阻塞的网络 I/O 编程接口”这样的表述。
那么,这样的表达有什么问题吗?
答案是:完全没问题!
这两句话所传达的事实是确凿无疑的,但前提是,你需要多思考一步:优异的网络框架不应该是同步的!
如果网络的读写都是同步的,就无法应对高并发、高吞吐的应用场景,二十多年前的计算机前辈们就提出了 C10K 问题,也就是单机如何支持 1 万个并发连接的问题。
在 Linux 上, C10K 问题最终的解决方案是非阻塞 IO+epoll 的 I/O 多路复用技术,且一直沿用至今。
所以,一门优秀的语言必须解决 C10K 问题。事实上,这里的“同步”仅仅是指 Go 提供的“编程接口”,而不是内在的网络模型。
但是,为什么一定要提供同步的编程接口呢?
人类生活在一个充满异步的世界里,许多事物和事件并行发生,而计算机的发展却是从同步开始的,汇编语言以及其它的低级语言为我们塑造了原始的同步编程模型,我们已经越来越习惯它了,这就导致异步编程成为一件复杂且困难的事。
因此,以高效的内在网络模型为内核,向外提供同步的用户编程接口,会成为解救程序员思维,让编程体验极度舒适的善举。
为什么需要异步
对异步的渴求,其实是源自于对高效率的渴望。
一切都因为 CPU 太快,I/O 设备太慢,需要运行的任务太多。这是目前计算机所面临的现状。
然而,CPU 和 I/O 设备是可以并行工作的。通过异步操作,CPU 可以在等待 I/O 操作完成的同时继续执行其他指令,充分利用其计算能力。当 I/O 操作完成时,CPU 会收到通知,并处理 I/O 返回的结果,唤醒等待者。
可见,这种异步模型能极大地提高系统的吞吐量和响应能力,尤其在需要同时处理大量 I/O 操作时,异步的优势相比同步会更加明显。
简单总结一下异步 I/O 的优势,有如下两点:
- 能够在等待 I/O 操作的同时执行其它任务,充分利用 CPU 的计算能力。换句话说,正在 CPU 上披荆斩棘的线程不会因为一次 I/O 而停下脚步,在提交了 I/O 申请之后可以去执行下一个任务,而执行下一个任务的能力是由并发模型决定的。
- 最大限度地发挥 I/O 设备的吞吐能力。当系统中存在大量并发的 I/O 操作,或者有多个独立的任务可以并行处理时,异步 I/O 能够提供更好的性能和资源利用率。
最常见的文件 I/O 和网络 I/O 是最需要异步的,文件读写极有可能会遇到所读内容不在高速页缓存中的情况,此时需要等待慢速磁盘将内容读入内存;网络读写也无法永远保证 socket 缓冲区的就绪状态(读/写系统调用发生时,缓冲区有内容可读与有空间可写)。等待这两种 I/O 完成的代价实在太大,也就很有必要将其异步化——在 I/O 设备工作的同时,让 CPU 去完成其它任务。
然而,需要留意的是:异步 I/O 的效率提升主要取决于系统中存在的并行任务数量和性质。如果计算机只有少量任务且这些任务必须串行进行,那么异步 I/O 可能不会带来明显的性能提升,因为任务之间无法并行执行。
同步、异步、阻塞、非阻塞
同步、异步、阻塞、非阻塞这两对儿概念总是绕不过去的,同时也是无法轻易阐述明白的,本文无意做这种努力。软件领域并不存在一以贯之的概念,想要在概念上把软件行为掰扯清楚明白将注定徒劳无功。
能够确定的是,在很多场景下,这两对概念可以描述同一件事情,比如,以电商系统中用户下单为例,对支付系统需不需要等待订单处理系统的反馈问题上,可以分为同步、异步或者阻塞、非阻塞两种情况。如果支付系统需要等待订单处理的结果,那么就可以说这个过程是同步的,或者说订单处理流程阻塞了用户下单;如果支付系统在用户支付后就向用户反馈结果,并将新生成的订单以消息事件的方式通知下游订单系统处理,就可以说这个过程是异步的,订单的处理是非阻塞的。
但事情并不总是这样,比如谈到网络 I/O 时,这两对儿概念就不能等量齐观了。
每个 socket 连接都有两个缓冲区,一个用于发送,一个用于接收,当接收缓冲区为空,发送缓冲区满的时候,网络的读/写就会阻塞,此时意味着线程会失去 CPU,应用发出的读/写系统调用在内核代码路径中会触发进/线程的调度,在缓冲区就绪之前,线程会被换下 CPU 进入被阻塞的等待状态。因此,当在系统调用、内核态等上下文中提到阻塞的时候,往往意味着进/线程的切换,意味着有人失去 CPU,进而失去执行其它任务的机会。
同步就像是函数调用,一旦发出请求,就必须等到执行完成后返回,才能继续往下进行;异步则不然,发出请求后会立马返回,I/O 操作会在未来某个时刻完成并通知请求者。这样看来,在网络 I/O 这件事上,同步和阻塞的表达看上去没有什么区别,而非阻塞和异步就有些微妙了,这还要从非阻塞的功能意义上说起。
fnctl系统调用可以通过O_NONBLOCK标志将文件设置为非阻塞,吊诡的是,这个非阻塞标志只对网络文件描述符起作用,对于普通的磁盘文件描述符是没有任何效果的。
这其实完全可以理解,文件并不像网络有一个缓冲区,文件流永远都是就绪的。那么,当网络文件描述符被设置为非阻塞之后会有什么样的表现呢?我们分别描述一个网络文件描述符在阻塞和非阻塞状态下read系统调用的过程。
假设应用基于这个文件描述符发出read系统调用的时候,socket 接收缓冲区为空(网络消息尚未到达):
- 阻塞:当前的应用线程会因此被阻塞,进而被内核调离 CPU,当网络消息到达之后,缓冲区就绪,产生网络中断,内核获得 CPU 使用权,再次将应用线程换上 CPU ,
read系统调用继续,CPU 将消息拷贝至用户空间,系统调用完成。 - 非阻塞:
read系统调用会立即返回,并附带一个EWOULDBLOCK或者EAGAIN的错误,从错误含义就可以看出一些端倪,仿佛内核告诉你:“这次调用会造成阻塞,不过没关系,我发现你设置了非阻塞标志,我不会将你挂起,请你过一会儿再试吧!” 此时,应用就可以去做其它的任务,并在需要的时候重新发起read系统调用进行读取,缓冲区一旦就绪,CPU 就会将消息拷贝至用户空间。
很明显的一点是,非阻塞调用除了通知应用缓冲区尚未就绪之外,没做其它的事情。应用需要不断地试探,在某一次碰巧赶上缓冲区就绪时,这次read系统调用才宣告成功,因此问题的关键是:应用在得知缓冲区就绪之前,不知道要发出多少系统调用来试探!
而异步的网络 I/O,除了会在系统调用发出后立即返回之外,还会在“后台”完成真正的 I/O 操作,在这里就是将 socket 缓冲区中的内容拷贝至用户空间,并以某种方式通知应用,可见非阻塞和异步的区别还是很大的。
那么 Linux 平台提供异步 I/O 的支持了吗?
简单说,有,但很难用,很多时候没法用!
POSIX 有对应的 aio_read 、aio_write等异步函数实现,但无奈太拉胯,性能奇差。
Linux 内核也有原生的异步 I/O 支持,并冠以AIO之名,但限制很多,如只支持O_DIRECT访问、只支持特定设备、性能表现不佳等等,社区满意度极低,饱受诟病,我甚至找不到异步网络 I/O 的例子,因此可以说,当前 Linux 只支持有限的文件异步 I/O,不支持网络异步 I/O(至少没有应用场景)。
要知道,在异步 I/O 的概念出现之前,还有一种中间形态——IO 多路复用。
直到现在,IO 多路复用依然是 Linux 平台高并发网络的主流解决方案,以epoll为支点的事件循环结构铸就了当今互联网绝大多数网络程序的 Reactor模型。
I/O 多路复用
我们可以用非阻塞+单线程或多线程的网络模型来处理大量网络连接,但是由于需要浪费 CPU 来试探缓冲区是否就绪,所以效率难免会大打折扣。
那么索性就让操作系统来通知我们就绪的网络文件描述符吧!这就是 I/O 多路复用:应用只要阻塞在单个系统调用上,就可以监听多个网络文件描述符事件。
Linux 内核对 I/O 多路复用支持的变迁史可简单描述为select->poll->epoll的改进路线 ,这三种方式原理大致相同,但性能越来越高。
我在读 Stevens 先生的《UNIX网络编程》时,常常奇怪:为什么书中只介绍了select和poll,却对epoll只字未提。后经求证,两部《UNIX网络编程》分别成书于 1990 年和 1999 年,epoll首次出现在 Linux 内核是在 2002 年。令人扼腕的是,Stevens 先生于 1999 年辞世,身后为我们留下了 7 部传世名著,其中就包括大家熟知的《TCP/IP详解》三部曲。
让我们沿着伟人的叙述脉络,来看一看 I/O 多路复用与其它 I/O 模型的比较:
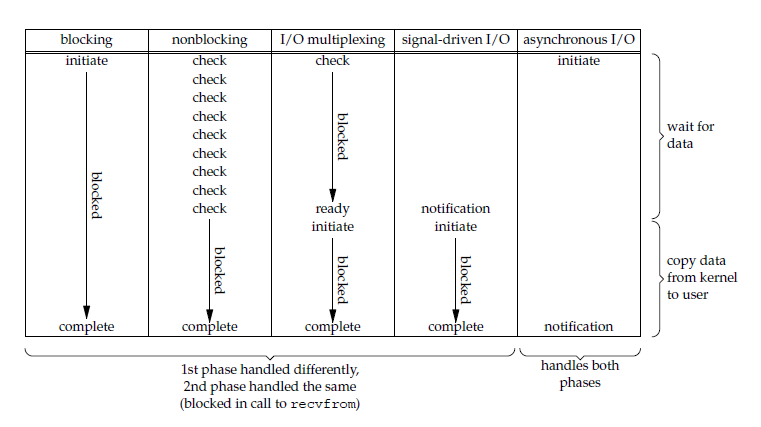
一次网络 I/O 读取操作分成两个阶段:
(1)等待数据就绪
(2)从内核空间拷贝数据到用户空间
可见,只有 blocking I/O 和 asynchronous I/O 能为请求者包揽两个阶段,其余的 I/O 模型在第 1 阶段的表现各不相同,却在第 2 阶段表现一致,即均需要请求者主动完成。noblocking I/O 为了探知数据是否就绪而空耗 CPU,这肯定是无法容忍的,于是内核出马,I/O 多路复用诞生。
至于 blocking I/O ,它是最简便的网络模型,用它来进行网络编程简洁却不高效,因为它会阻塞当前线程,引发线程切换,所以我们才会在寻求高效 I/O 模型的道路上孜孜不倦。
图中有三种模型的第二阶段被标注为blocked,对此我有一点不同的看法, 当我们谈及系统调用的时候,阻塞通常意味着线程因工作无法继续而被调离 CPU,我们看上图中的 noblocking I/O、I/O 多路复用和 signal-driven I/O 三种模型,它们在第 1 阶段通过不同的方式得知数据已经就绪(noblocking I/O 不是收到通知,而是通过撞运气),第 2 阶段发出系统调用开始读取数据,窃以为第 2 阶段并不存在阻塞,也并没有绝对的首恶元凶导致线程切换,这一阶段也就不应被称为“blocked”,如果非要用什么概念来描述一下的话,我愿用“同步”来称呼它。
事实上,Stevens 先生在讨论 asynchronous I/O 的时候,确实将前面 4 种 I/O 模型称为“同步 IO”,我认为这一说法成功把水搅浑了,特别是当 noblocking I/O 和 I/O 多路复用尚拥有一点“异步”特质的情况下,这往往让后来者很容易迷失在概念里。
正确的做法是:把概念丢掉,在内核和指令的维度去体认每一种 I/O 模型。即便真的存在两个可以称之为“同步”、“异步”的明确概念,也大可不必将 noblocking I/O、I/O 多路复用和 signal-driven I/O 套用其中。可以把它们看成一种中间形态,毕竟“同步”、“异步”的定语是修饰整个 I/O 过程的,而非其中的某一步。
非阻塞 I/O 和 epoll 的组合或者说就是 I/O 多路复用,是目前 Linux 平台主流的高并发网络解决方案,基本上所有的高性能网络框架或者服务器都是由此打造。然而每一项技术都不是独立存在的,也不应当被独立理解,Linux 为我们提供了 I/O 多路复用这样一块积木,至于用这块积木能构建成怎样的世界,可能性似乎是无限的,Reactor 网络模型就是其中一例。
Reactor 是利用非阻塞 I/O 和 epoll 构建的事件循环模型,是对 epoll 的抽象和封装,使得使用更加便捷,因为对事件分发,使用相应的 handler 来处理事件,非常像核反应堆,所以得名 Reactor。Reactor 的形式有多种多样,本文并不想去详细介绍个中细节,谈及 Reactor 仅仅是想说明:对于事物的理解,先要从一座森林理解一棵树,然后才能从一棵树理解整座森林。
“异步编程”和“异步”这两个概念是有所区别的,“异步”是一种特性,“异步编程”是基于此特性演化出的编程范式。
在编程语言领域,我认为异步编程的终极形态是为上层开发者隐藏异步编程的复杂性,提供同步的编程接口。就像 Go 语言netpoller 那样,底层使用了目前最优秀的非阻塞和 epoll 模型构造的单线程 Reactor,上层为开发者呈现出简洁、直观的同步编程接口。
netpoller
在进入繁琐的netpoller源码之前,先来切身地体验一下 Go 的网络编程,相信下面的代码对每个 Gopher 来说都不陌生:
1 | package main |
这段代码是使用net包编写的一个简单的网络 Server,其中handleConnection展示了如何读取 socket 中的内容,n, err := conn.Read(buffer)以同步阻塞的方式发出了Read请求,对于开发者来说一个读取操作就这样轻松完成了,简洁到无以复加!内里乾坤甚至是初学者根本不会去想的,这就是 Go 为开发者提供的网络编程接口,复古而优雅。
因为,根本不用担心 goroutine 所在的 M 线程被阻塞!
使用 epoll 进行网络程序的编写,需要三个步骤,分别是 epoll_create,epoll_ctl 和 epoll_wait。这三个 API 基本对应着 epoll 实例创建、增加监听描述符、poll 网络事件这三个动作,接下来我会就这三个动作来剖析一下 netpoller,此处参考 go 1.18 的源代码。
epoll 初始化
netpoller 创建 epoll 实例的关键代码位于 pollDesc 这个结构体的 init 方法中:
internal/poll/fd_poll_runtime.go
1 | type pollDesc struct { |
poll.pollDesc 是 poll.FD 中的一个字段,poll.FD 表示文件描述符,os 包和 net 包都包含它来组成上层意义的网络连接和 OS 文件。poll.FD 的 Init 方法会调用 poll.pollDesc.init 来初始化 epoll 实例,初始化函数runtime_pollServerInit是个单例模式,也就是说,epoll 实例会在程序创建第一个文件描述符时被创建。我们看一下runtime_pollServerInit:
runtime/netpoll.go
1 | //go:linkname poll_runtime_pollServerInit internal/poll.runtime_pollServerInit |
poll_runtime_pollServerInit 是一个未导出的方法,此处将其链接成了internal/poll.runtime_pollServerInit,因此可以在 internal/poll 包里直接调用。netpollGenericInit调用了netpollinit,netpollinit使用epoll_create来创建 epoll 实例:
runtime/netpoll_epoll.go
1 | func netpollinit() { |
epfd 是 epoll 实例的文件描述符,它是一个全局变量,后续会作为 epoll_ctl 和 epoll_wait 系统调用的参数被传入。在创建完 epoll 实例之后,紧接着使用epoll_ctl加入了一个非阻塞的管道描述符,这里主要用于唤醒阻塞在 epoll_wait 上的 poll 线程。
这是可以理解的,毕竟 polling 事件的线程还有其它任务,如果待监听的描述符长时间无事件发生,不可能让线程一直阻塞下去。其实这个线程就是sysmon线程,一个不需要 P 即可运行的操作系统线程,稍后会介绍 sysmon 线程如何 polling 网络事件。
向 epoll 实例注册描述符
随着 epoll 实例的成功创建,接下来就可以使用epoll_ctl系统调用向其中添加感兴趣的文件描述符了,最终会使用epoll_wait来收取这些网络文件描述符上的网络事件,我们这里主要聚焦于描述符的注册之上。
Go 网络编程中涉及到向 netpoller 注册描述符的行为大致有Listen、Connect、Accept三类,为避免繁琐的代码,此处我以 TCP 为例,仅列出函数调用路径,至 epoll_ctl为止。
- 服务端 Accept 连接
1 | net.TCPListener |
这里值得一提的是,net.netFD.accept 调用 poll.FD.Accept, 进而调用 accept4 系统调用,将文件描述符设置为非阻塞。
1 | // Wrapper around the accept system call that marks the returned file |
- 服务端监听
1 | net.ListenTCP |
- 客户端拨号
1 | net.Dial |
三类操作最终都会调用 runtime.netpollopen,此函数会发出epoll_ctl调用,将fd与事件_EPOLLIN、_EPOLLOUT 、_EPOLLRDHUP 、_EPOLLET注册进 epoll 实例,并设置为边缘触发。
runtime/netpoll_epoll.go
1 | func netpollopen(fd uintptr, pd *pollDesc) int32 { |
epoll_ctl 有一个参数event,是和文件描述符关联的一个对象,在 go 源码中名为epollevent:
1 | type epollevent struct { |
其中data是用户设置的,kernel 必须保存它并在文件描述符就绪时(通过 epoll_wait 调用)一并返回。此处,ev.data被设置为pollDesc:
1 | *(**pollDesc)(unsafe.Pointer(&ev.data)) = pd |
每个网络文件描述符都会对应一个pollDesc,pollDesc是 Network poller descriptor,它控制着文件描述符的状态以及在该文件描述符上产生等待的 goroutine 的地址。
也就是说,当epoll_wait返回时,从就绪的ev.data中可以拿到等待读写的 goroutine 地址,我们接下来将详细剖析这个过程。
事件分发
epoll_wait的调用是由函数netpoll发出的,它会检查就绪的文件描述符,并且返回相关的 goroutine 列表,由此可见 netpoller 的事件分发特点:与 goroutine 紧密结合,将可读写的网络文件描述符转化为可运行的 goroutine,然后注入相关的运行队列,最终由调度器接管并伺机运行。
runtime/netpoll_epoll.go
1 | // netpoll checks for ready network connections. |
netpoll 并不像我们平时看到的 epoll 使用案例那样使用一个死循环来无限地epoll_wait,事实上它只epoll_wait一次,无限循环调用的任务放在了sysmon中,我们稍后会看到,现在将注意力放在如何将事件转化为对应的 goroutine 上。
从代码中可以看出,netpollready 会获取相关 goroutine 并插入到 toRun 链表:
runtime/netpoll.go
1 | // netpollready is called by the platform-specific netpoll function. |
这里交代一下 pollDesc 中的 rg,wg 字段,这两个字段就是控制描述符状态和相关 goroutine 地址的关键,它的定义如下:
runtime/netpoll.go
1 | type pollDesc struct { |
rg 和 wg 都是原子类型,里面可能存放的内容为:pdReady, pdWait, G waiting for read or nil,G 就是 goroutine 的地址,我们继续沿着调用向下看:
runtime/netpoll.go
1 | func netpollunblock(pd *pollDesc, mode int32, ioready bool) *g { |
拿到 *g 之后,就可以插入toRun链表了:
runtime/proc.go
1 | // A gList is a list of Gs linked through g.schedlink. A G can only be |
toRun是gList类型,gList是一个靠g.schedlink串联起来的单链表。
是时候看看netpoll的调用者如何处理这些 goroutine 链表了,前面说过这个工作是sysmon来完成的,sysmon会在单独的操作系统线程中运行,看一下其创建过程:
runtime/proc.go
1 | // The main goroutine. |
sysmon的功能很多,我们这里只看它如何 polling network:
1 | // Always runs without a P, so write barriers are not allowed. |
如果距离上次 polling 过了 10ms,那么就再次发出 polling,如果结果不为空,则调用 injectglist,而 injectglist 会将结果链表中的 goroutine 的状态修改为runnable后放入本地或全局队列,后面就是调度器接手了,此处不再赘述。
goroutine 的停泊与 pollDesc
上面介绍了网络事件如何转换为对应的 goroutine ,这个过程依靠的关键是pollDesc中的 rg 和 wg,但是 rg 和 wg 是在何时设置为当前 goroutine 的地址的呢?当 socket 缓冲区未就绪时,一个Read调用将会发生什么呢?
其实,只要稍加思索就会明白,这两个问题极具相关性。Go 中的网络连接是线程安全的,允许多个 goroutine 同时发出读写操作,而 pollDesc 只有一个 rg 和 wg,因此多个 goroutine 读写必定是用锁来串行化的,rg 和 wg 也必然是在读写遭遇阻塞时设置的。事实上,我也正是从这个思路出发,在源码中找到关键所在的。
让我们从一个Read调用开始,看看其内在端倪。
以 TCP 的读取为例,沿着 conn 的 Read 接口调用路径net.netFD.Read--->poll.FD.Read,可以定位到poll.FD.Read:
internal/poll/fd_unix.go
1 | // Read implements io.Reader. |
当 socket 缓冲区未就绪,读取一个非阻塞的网络文件描述符时会返回EAGAIN或者EWOULDBLOCK错误,紧接着调用链runtime.pollDesc.waitRead--->runtime.pollDesc.wait--->poll.runtime_pollWait--->runtime.netpollblock会触发调度,将当前 goroutine 换下 CPU,寻找一个新的 goroutine 来运行。
runtime/netpoll.go
1 | // returns true if IO is ready, or false if timedout or closed |
netpollblock会将pollDesc中的 rg 或 wg 设置为pdWait,然后调用gopark将当前 goroutine 休眠,进入schedule流程挑选新的 goroutine 来运行。
gopark的调用在一个if判断里,按目前的代码只要netpollcheckerr没有错误发生,就会调用gopark,因此我觉得waitio特别是像为真正的异步 I/O 预留的接口,以备向后兼容。
请记住传入gopark的前两个参数:netpollblockcommit和unsafe.Pointer(gpp),然后再来看gopark中的相关内容:
runtime/proc.go
1 | // Puts the current goroutine into a waiting state and calls unlockf on the |
gopark会获取当前所在的m,并将函数netpollblockcommit和unsafe.Pointer(gpp)(pollDesc 中的 rg)分别赋值给mp.waitlock和mp.waitunlockf,接下来进入mcall(park_m)的调用,mcall 是个汇编函数,它会调用传参中的函数且不再返回,我们看一下mcall的内容,明确一下将要传给函数park_m的参数:
runtime/asm_amd64.s
1 | // func mcall(fn func(*g)) |
根据Go internal ABI specification的描述,amd64平台下整型参数传递依次使用如下寄存器:
1 | RAX, RBX, RCX, RDI, RSI, R8, R9, R10, R11 |
这里有一个知识点:R14 寄存器存放当前 goroutine 的地址,可以从汇编代码中看到mcall是如何利用 R14 寄存器切换到 g0 的。
mcall的主要工作就是保存当前 goroutine 的状态,切换到 g0 堆栈并执行传入的函数fn,这里即将执行park_m。
MOVQ R14, AX // AX (and arg 0) = g这一句将当前 g 的地址存入 AX 寄存器,并在接下来CALL R12 // fn(g)的时候,充当第一个参数。
接下来进入park_m:
runtime/proc.go
1 | // park continuation on g0. |
此时,参数gp是发出Read系统调用的 goroutine 地址,在进入schedule()调度循环之前,我们仅关注ok := fn(gp, _g_.m.waitlock)这一句,gopark函数已经将netpollblockcommit和unsafe.Pointer(gpp)(pollDesc 中的 rg)分别赋给了mp.waitlock和mp.waitunlockf,所以这里的调用实际上是netpollblockcommit(gp, unsafe.Pointer(gpp))。
不知道你有没有好奇,挂起的明明是当前的 goroutine,为什么函数的名字是park_m呢?这里的m显然就是 GMP 中的线程 M 啊,我是这样理解的:M 就像是一列高速运行的汽车,乘客是goroutine,当某个乘客因某些原因不能继续乘坐时,M 需要停下来让乘客下车,然后再开动去寻找下一位乘客,所以这个挂起 goroutine 的过程就像是 M 停泊了一样。
但为了叙述方便,我还是称 goroutine 停泊好了,毕竟比喻并不十分恰当,从指令角度看 M 可是一路狂奔从未停过,只是从代码所有权角度来看, M 确实是换了一位乘客。
runtime/netpoll.go
1 | func netpollblockcommit(gp *g, gpp unsafe.Pointer) bool { |
atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp)))将rg的值更新为发出Read 调用的 goroutine地址。
至此,两件重要的事情已经完成:
- 休眠发出
Read调用的 goroutine。 - 设置与该
goroutine感兴趣的文件描述符相关的pollDesc.rg为该goroutine的地址,以便后续polling时促成网络事件向goroutine链表的转化。
这种模型的好处是非常节省 M,M 在 Go 的 GMP 并发模型中代表操作系统线程,因为网络 I/O 非阻塞的特性,M 会从系统调用中立即返回,不会因为数据未就绪而被内核剥离 CPU,M 当然就可以挂起当前 goroutine,转而去寻找其它的 goroutine 来运行。
反观文件 I/O 则不然,文件 I/O 没有异步和非阻塞特性(不考虑臭名昭著的AIO),当 M 因为系统调用陷入内核时,如果要读取的内容不在页高速缓存中,就会触发缺页处理,内核需要向磁盘发出 I/O 请求,因为这个过程不是异步的,内核会将 M 剥离,调度其它线程来运行。可想而知,此时此刻 go runtime 只能新建 M 来匹配 P,新建的 M 需要加入内核运行队列,等待内核调度,经过这样一番折腾,吞吐自然就下来了。
更可怕的是如果有大量 I/O 请求,势必会让更多的 M 陷入内核无法自拔,go runtime 除了创建更多的 M 之外别无良策,在这种情况下仍不断地创建 M 无异于扬汤止沸,如果 M 的数量超过 1 万,程序就 panic 了。
所以,go 并不适合文件 io 密集型任务,除非有真正的异步 I/O,使得文件也可以享用 Reactor 的好处。
本质上, netpoller 使用非阻塞I/O和epoll模型构建的是一个单线程的Reactor,即便如此,也已经可以满足绝大多数的场景需求,可以说这套模型是 Linux 平台的最佳、最高效的解决方案。然而实在是拗不过非阻塞I/O 和 epoll这对组合有一些不那么“同步”的特性,以讹传讹间,不少不明就里的人就把这种模型称为异步 I/O 了。
直到 2019 年 io_uring 横空出世,Linux 异步世界才终于迎来了一丝曙光!
下一代异步 I/O
io_uring 由 Jens Axboe 提出和实现,并于 2019 年 5 月随 Linux 5.1 发布。io_uring 是 Linux 内核引入的新型异步 I/O 框架,旨在改善 AIO 的性能和可扩展性,社区称“io_uring can change everything”。本文不准备对其做过多介绍,感兴趣的朋友可以参考 Efficient IO with io_uring 这篇文章。这里仅从系统调用的角度来谈一谈 io_uring 可能为上层带来的变化。
网络 I/O
以非阻塞 I/O 和
epoll为蓝本的 Reactor 在收到网络事件之后,仍然需要主动发起一次系统调用去读取 socket 的内容,在 io_uring 下就没有这一步系统调用了,当等待者被唤醒以后,数据就已经在手边了。不过,要适配 io_uring 还需要不少工作要做,比如 go 的 netpoller 就需要对 runtime 做改造适配,当然适配完成后的网络模型就不是 Reactor 了,而是 Proactor,当然了,叫什么并不重要,重要的是它怎么干这件事。文件 I/O
前面讨论过,Reactor 并不能拯救文件 I/O,Go 运行时甚至会出现“卡线程”的情况。但是,io_uring 完美解决了这一痛点,不像它的前任 AIO 每次追加请求以及获取结果都要发起一次系统调用,io_uring 实现了用户空间和内核空间的内存无锁共享,很多很多的系统调用被节省了,所有 I/O 全都可以交给专门的线程负责,这就是 Proactor。
如果 Go runtime 适配了 io_uring 会怎样?届时意味着“卡线程”成为历史,Go 不仅适合网络密集型I/O,也会适合文件密集型I/O 。
事实上,Go 社区已经在讨论适配的可能性了(见#31908),进展算不上快,但未来可期!
再论异步编程模型
直接进行异步编程是复杂且困难的,你需要设计专门的模块统一处理 I/O 请求,并且具备唤醒机制,即便这些问题得到了完美解决,你也会发现你创造了另一个 Reactor 或者 Proactor。但如果不做这些,异步就无法发挥作用。试想一下,一个任务发出异步请求之后,请求立即返回了,那么任务本身该何去何从呢?没有 I/O 的结果 任务就无法推进,这个时候就要有将任务 Park 的能力了。
由此可见,异步编程其实是考验并发模型的,也就是分解任务的能力,如果一门编程语言只能以线程来分解任务,那么使用异步的代价就会增加,这个问题的解决方案就是协程,如果编程语言实现了协程,那么任务分解的粒度变为协程,则更能有效的利用异步 I/O 带来的优势。
Go 就是这种玩法,非阻塞和异步都可以拿来和协程相配合,思路非常容易理解。Rust 的异步运行时也有协程的概念,走的是状态机路线(对话 ChatGPT 理解 Rust 异步网络 io),属于另外一种玩法,很难说孰优孰劣。Go 使用有栈协程,调度原理很好理解,编程接口简单直接,缺点是goroutine数量过多会有隐患;Rust 使用无栈协程,利用状态机实现协程切换,好处是节省了不少指令,理论上有性能优势,缺点是接口太过晦涩。
可见,trade-off 无处不在!
参考文献
- UNIX网络编程
- Linux/UNIX系统编程手册
- 网络编程实战
- Redis 源码剖析与实战
- Efficient IO with io_uring
- Ringing in a new asynchronous I/O API
- The rapid growth of io_uring
- What’s new with io_uring
- Getting Hands on with io_uring using Go
- #31908