Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
Typically, the strategy pattern stores a reference to some code in a data structure and retrieves it. This can be achieved by mechanisms such as the native function pointer, the first-class function, classes or class instances in object-oriented programming languages, or accessing the language implementation's internal storage of code via reflection.
stackoverflow上亦有相同的发问 Is 'Strategy Design Pattern' no more than the basic use of polymorphism? 得票最高的回答也阐述了相同的意思:策略模式,或者说设计本身,它不是指细节代码,而是一种思维方式。
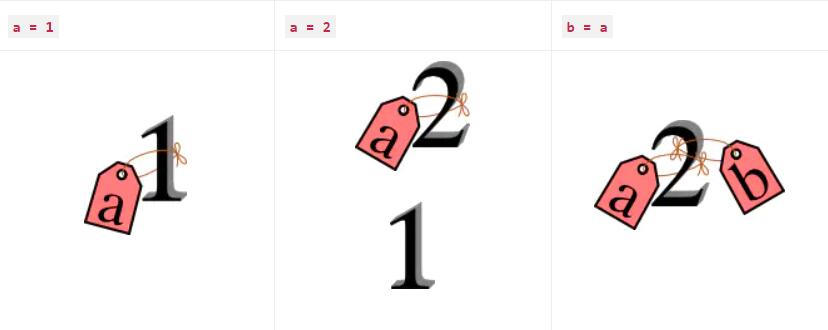
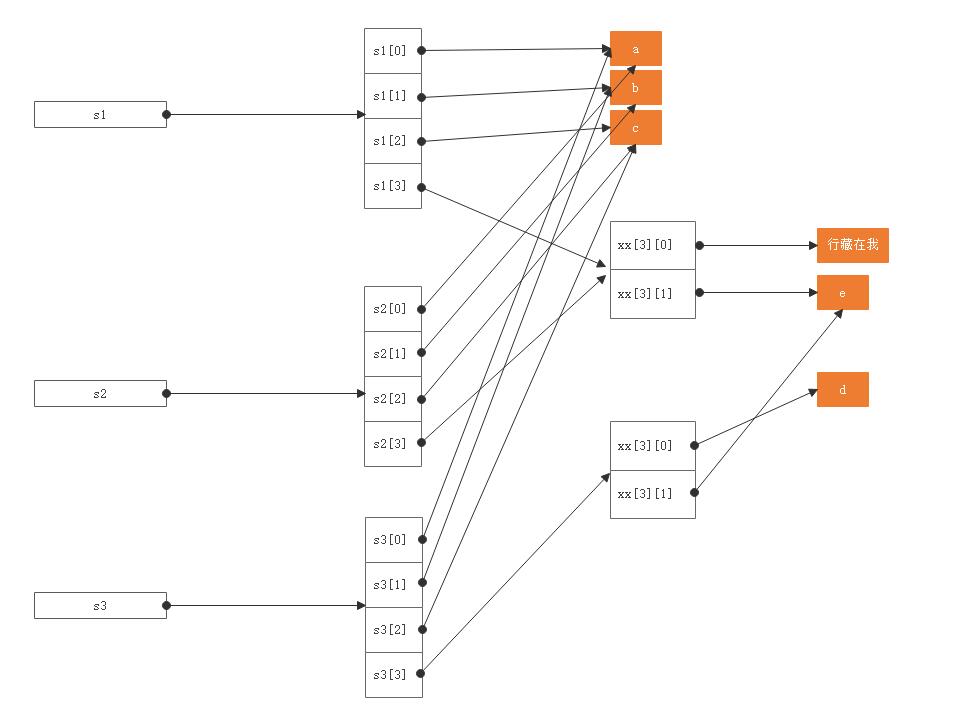
>>> a = [1,2,3,4,5] >>> b = a >>> a,b ([1, 2, 3, 4, 5], [1, 2, 3, 4, 5]) >>> id(a),id(b) (140232582690624, 140232582690624) >>> a == b True >>> a is b True
Objects are Python’s abstraction for data. All data in a Python program is represented by objects or by relations between objects. (In a sense, and in conformance to Von Neumann’s model of a “stored program computer”, code is also represented by objects.) Every object has an identity, a type and a value. An object’s identity never changes once it has been created; you may think of it as the object’s address in memory. The ‘is’ operator compares the identity of two objects; the id() function returns an integer representing its identity.
对于 python 中的变量赋值操作,有两种类比说法。一个是 “boxes vs. label” ,另一个是“names and bindings” 。我们采用“names and bindings” 这种说法,在 python 里一切都是对象,如interger、string、list、dict、set、function等。当我们赋值给一个变量的时候,我们仅仅把变量当成一个名字(name):
>>> a = 9527 >>> b = a >>> a,b (9527, 9527) >>> id(a),id(b) (140232581997552, 140232581997552) >>> b is a True >>> a = "bohu" >>> b = "bohu" >>> print(id(a)) 140090288720896 >>> print(id(b)) 140090288720896 >>> print(a is b) True
Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per se.
参数的传递是通过赋值进行传递(passed by assignment)。也就是说,参数传递时,只是让新变量与原变量指向相同的对象而已,并不存在值传递或是引用传递一说。
1 2 3 4 5 6 7
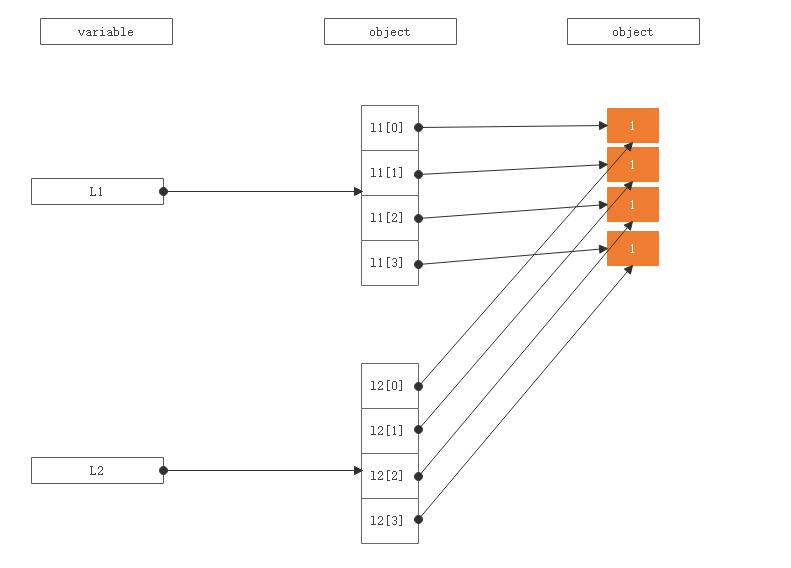
defmy_func1(b): b = 2
a = 1 my_func1(a) a 1
这里的参数传递,使变量 a 和 b 同时指向了 1 这个对象。但当我们执行到 b = 2 时,系统会重新创建一个值为 2 的新对象,并让 b 指向它;而 a 仍然指向 1 这个对象。所以,a 的值不变,仍然为 1。
那么对于上述例子的情况,是不是就没有办法改变 a 的值了呢?答案当然是否定的,我们只需稍作改变,让函数返回新变量,赋给 a。这样,a 就指向了一个新的值为 2 的对象,a 的值也因此变为 2。
1 2 3 4 5 6 7 8
defmy_func2(b): b = 2 return b
a = 1 a = my_func2(a) a 2
当你想获取改变后的值的时候,最好的选择就是返回一个元组来包含多个结果:
1 2 3 4 5 6 7 8
>>> deffunc1(a, b): ... a = 'new-value'# a and b are local names ... b = b + 1# assigned to new objects ... return a, b # return new values ... >>> x, y = 'old-value', 99 >>> func1(x, y) ('new-value', 100)
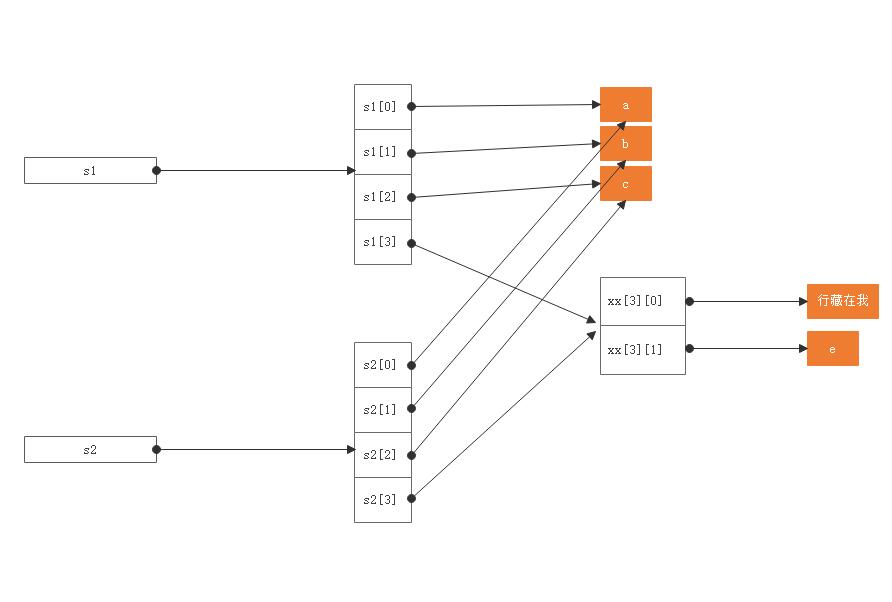
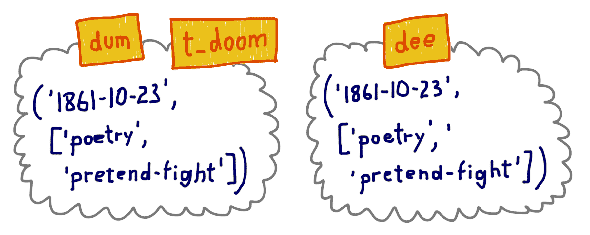
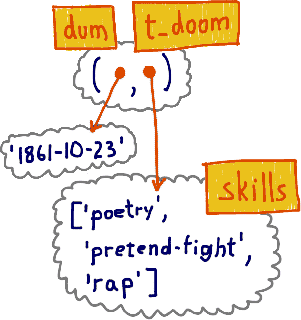
>>> dee = ('1861-10-23', ['poetry', 'pretend-fight']) >>> dum = ('1861-10-23', ['poetry', 'pretend-fight']) >>> dum == dee True >>> dum is dee False >>> id(dum), id(dee) (4313018120, 4312991048)
>>> t_doom = dum >>> t_doom ('1861-10-23', ['poetry', 'pretend-fight']) >>> t_doom == dum True >>> t_doom is dum True
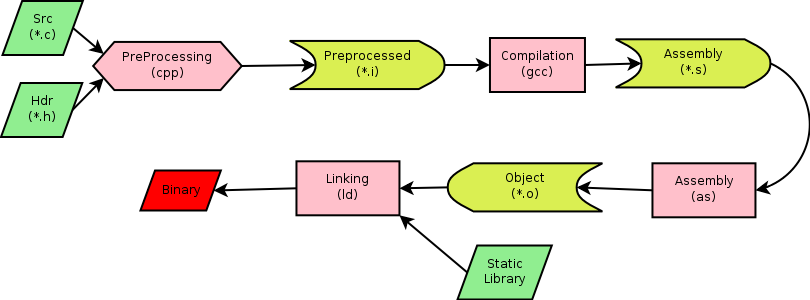
正如前文所言,当编译完成得到汇编文件之后,接下来的工作就交给汇编器来执行了,汇编器是将汇编代码转变成机器指令的工具,每一条汇编语句几乎都对应一条机器指令。所以汇编器的活儿相对来说比较简单,只是把汇编指令跟机器指令对照翻译一下,当然翻译完文件就由可读的汇编代码变为只有机器才可以看懂的二进制文件了。对于上面得汇编文件我们可以使用 as 来完成汇编:
1
as hello.s -o hello.o
或者使用 GCC 的 -c 选项,它的意思是编译或者汇编源文件,但不进行链接:
1
gcc -c hello.s -o hello.o
或者直接从 C 文件到目标文件(Object File 的概念非常重要,但此处不展开,留待以后单独讨论):
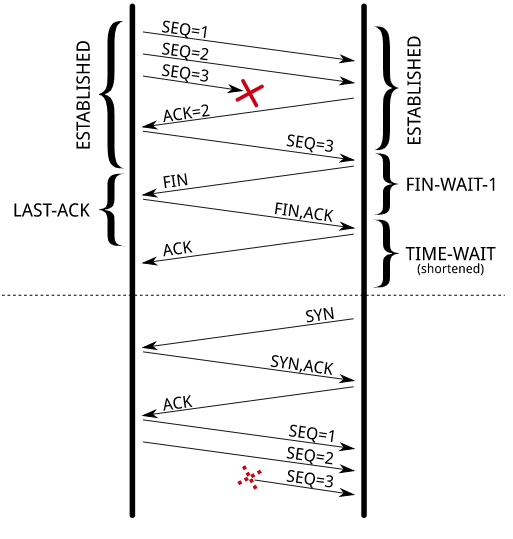
MSL(Maximum Segment Lifetime),意为最大报文生存时间,是 TCP 协议中的概念,指的是一个 TCP 的 Segment 在网络上生存的最大时间。很多书籍中都提到 MSL 是由 IP 层的 TTL 来保证的,但 TTL 和 MSL 不绝对相等,一般 MSL 会大于 TTL。我观 RFC793 中使用了 assume 一词(Since we assume that segments will stay in the network no more than the Maximum Segment Lifetime),所以我理解 TCP 并不会保证一个报文的最大生存时间,只是将 MSL 作为前提假设进行协议上的设计。
ISN(Initial Sequence Number),初始序列号 是一个连接建立之前双方商议的初始的序列号,也就是传输的第一个字节的编号(通常是 SYN 位,因为 SYN 消耗一个序列号,相对的 ACK 不会消耗序列号,毕竟 SYN 和 FIN 是要保证可靠传输的)。很显然这个初始序列号不能是 0 或者 1,它必须是一个随机的数,并会随时间改变,这样每一个连接都拥有不同的初始序列号。RFC793 指出初始化序列号可被视为一个32位的计数器,该计数器的数值每 4 微秒加 1,这样循环一次需要 4.55 小时。此举的目的在于为一个连接的报文段安排序列号,以防止出现与其它连接的序列号重叠的情况,尤其是对于同一个连接的两个不同实例(也叫不同的化身)而言,新的序列号也不能出现重叠的情况。
解释一下所谓的同一个连接的不同实例,我们知道标识一个连接需要 2 个 IP 和 2 个端口号,称为四元组。如果再加上协议类型就称为五元组,因为我们只讨论 TCP,所以也可以直接叫四元组。所谓的同一个连接的不同实例是指一个连接关闭后,又以相同的四元组打开了一个新的连接,通常称老的连接为前一个化身。
试想一下,一个连接因为某种原因被关闭,紧接着又以相同的四元组被重新建立。如果这时旧连接的一个延时的报文又到达了,碰巧这个延时的报文段的序列号对新连接又是有效的,那么这个报文就会被视为有效的数据进入新连接的数据流中。TCP 的很多设计目标都是为了避免这种恼人的情况,更为复杂的是随着网路性能的提升,带宽的增加,这种问题甚至出现在同一个连接实例当中,因为 SN 这个 32 位的字段也是要回绕重用的,如果一个回绕的时间太短,小于一个 MSL 的时候,我们也要面对延时报文的问题。
|- 2**32 ISN ISN | * * | x o * * | * * | o-->o* * | * * ^ | o o * | | * * | o * * S | * * e | o * * q | * * | o* * # | * * | o * |*_________________*____________ ^ Time --> 4.55hrs
Figure 7. Duplication on Fast Connection: Nc < 2**32 bytes
如图 Figure 7 所示是连接传输的字节小于 4GB 的情况,并在序列号 x 处连接关闭或者崩溃,紧接着一个新的化身被建立,而此时的 ISN 尚远远小于 x 的值。这样前一个化身的老的重复的报文段很轻易的就侵入到当前的连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
|- 2**32 ISN ISN | o * * | x * * | * * | o * * | o * ^ | * * | | o * * | * o * S | * * e | o * * q | * o * | * * # | o * | * o * |*_________________*____________ ^ Time --> 4.55hrs Figure 8. Duplication on Fast Connection: Nc > 2**32 bytes
图 Figure 8 所示是连接传输的字节大于 4GB 的情况,且序列号已经回绕(wrap around),原本已经分离的曲线,在序列号回绕到 x 处时又相交了。一旦窗口有重合,老的延迟报文段就会造成问题。
我们知道序列号是一个 32 位的无符号整型,用它来编码,我们最多编码 4GB 的数据,超过 4GB 后就需要将序列号回绕进行重用。这在以前网速慢的年代不会造成什么问题,但在一个速度足够快的网络中传输大量数据时,序列号的回绕时间就会变短。当 wrap around time 小于 MSL 的时候会发生什么呢?TCP 一切的设计都基于假设报文段最大的生存时间不会超过 MSL 的,如果序列号回绕的时间极短,我们就会再次面临之前延迟的报文段抵达后序列号依然有效的问题。这就让 TCP 协议难以自圆其说,试看下面的示例:
tcp_tw_reuse - INTEGER Enable reuse of TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. 0 - disable 1 - global enable 2 - enable for loopback traffic only It should not be changed without advice/request of technical experts. Default: 2
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender's timestamp clock. Such an extension is not part of the proposal of this RFC.
但是,如果对端是一个 NAT 网络的话(如:一个公司只用一个 IP 出公网)或是对端的 IP 被另一台重用了,这个事就复杂了。建连接的 SYN 可能就被直接丢掉了(你可能会看到 connection time out 的错误)。所以 NAT 就是 net.ipv4.tcp_tw_recycle 的死穴。
其实我认为理论上在正常的 NAT 网络中也会出现此问题。假设 NAT 网络中一个客户端主动关闭了连接,在收到服务端的 FIN 报文后向对端发送了最后的 ACK,之后进入了 TIME_WAIT 状态。这个报文在 RTT/2 时间到达了服务端,服务端进入了 CLOSED 状态,此时 NAT 网络中的另一个客户机发起了连接,注意原客户机此时仍在 TIME_WAIT 状态,那么服务端的四元组已经可以重用了,但是如果此时发起新连接的客户机携带的时间戳没有保证递增,那么还是会出现 SYN 被丢弃的情况。(之所以有此疑问,是因为我不清楚中间路由是否会记录连接信息,如果中间路由能阻止连接的发起那么就不会出现这种情况,希望懂的朋友给以指正。)
NAT behavior for handling RST packets, or connections in TIME_WAIT state is left unspecified. A NAT MAY hold state for a connection in TIME_WAIT state to accommodate retransmissions of the last ACK. However, since the TIME_WAIT state is commonly encountered by internal endpoints properly closing the TCP connection, holding state for a closed connection may limit the throughput of connections through a NAT with limited resources.
RFC7857 中又对 RST 的情况做了修正,建议在删除连接信息之前保存 4 分钟的时间:
1 2 3 4 5
Concretely, when the NAT receives a TCP RST matching an existing mapping, it MUST translate the packet according to the NAT mapping entry. Moreover, the NAT SHOULD wait for 4 minutes before deleting the session and removing any state associated with it if no packets are received during that 4-minute timeout.
看了左耳朵耗子推荐的这篇 TIME_WAIT and its design implications for protocols and scalable client server systems 讲 TIME_WAIT 的文章,感觉比较清晰,就翻译出来,在这里记录了一下,其实其中内容在《TCP/IP详解》和《UNIX网络编程》中有更详细的讲解。但是文章仍然值得一读,它从程序设计角度描述了应该如何避免 TIME_WAIT 的困扰,但对 TCP 本身着墨不是很多,比如要理解 TIME_WAIT 绕不开 ISN 和 MSL,以及在消除了 TIME_WAIT 之后如何解决延迟报文的问题也未予以详述,我会在我的下一篇文章中就 TIME_WAIT 问题再展开论述,增加自己对 TCP 掌握的熟练度,并结合 ISN、MSL、TIMESTAMP 等概念进行说明。
注:才疏学浅,翻译如有错漏之处,还望斧正。
When building TCP client server systems it's easy to make simple mistakes which can severely limit scalability. One of these mistakes is failing to take into account the TIME_WAIT state. In this blog post I'll explain why TIME_WAIT exists, the problems that it can cause, how you can work around it, and when you shouldn't.
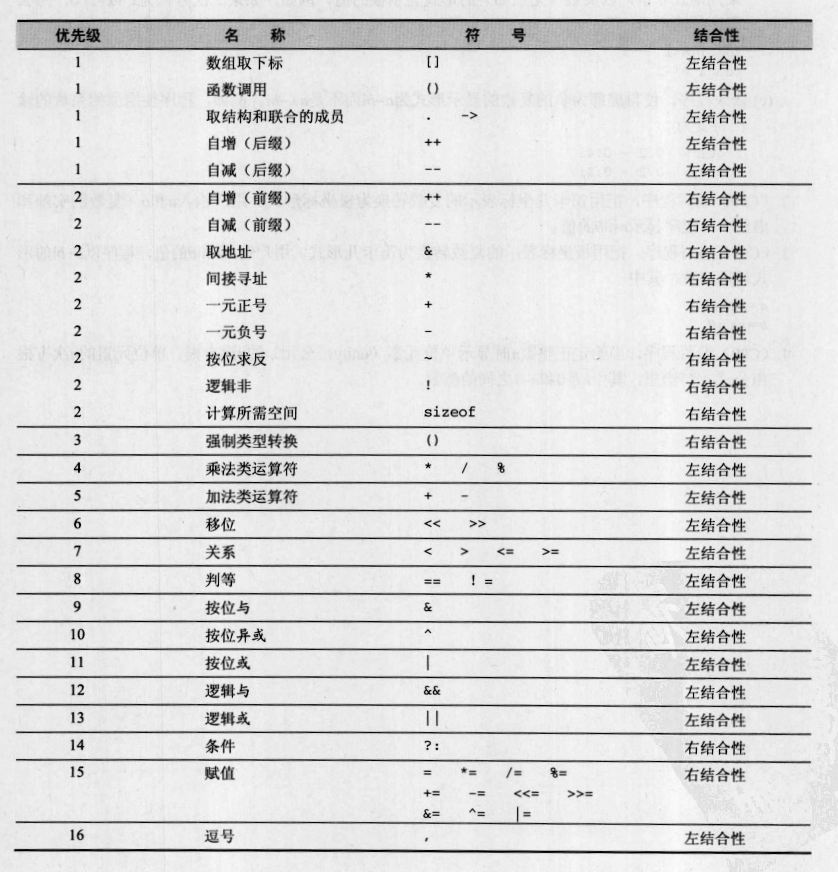
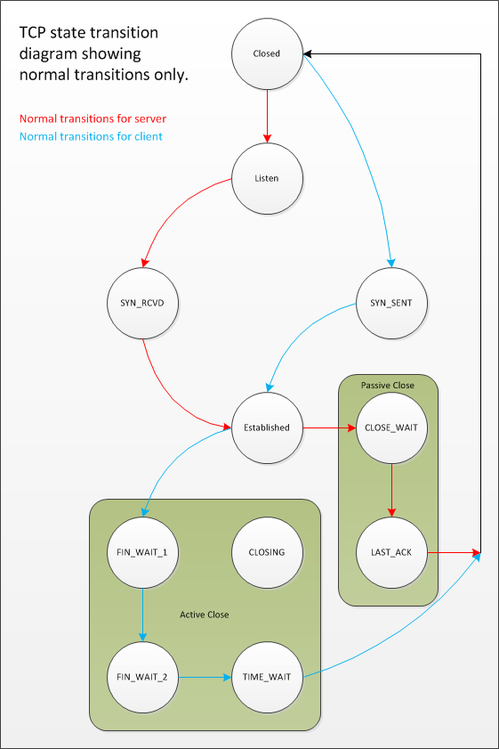
TIME_WAIT is an often misunderstood state in the TCP state transition diagram. It's a state that some sockets can enter and remain in for a relatively long length of time, if you have enough socket's in TIME_WAIT then your ability to create new socket connections may be affected and this can affect the scalability of your client server system. There is often some misunderstanding about how and why a socket ends up in TIME_WAIT in the first place, there shouldn't be, it's not magical. As can be seen from the TCP state transition diagram below, TIME_WAIT is the final state that TCP clients usually end up in.
Although the state transition diagram shows TIME_WAIT as the final state for clients it doesn't have to be the client that ends up in TIME_WAIT. In fact, it's the final state that the peer that initiates the "active close" ends up in and this can be either the client or the server. So, what does it mean to issue the "active close"?
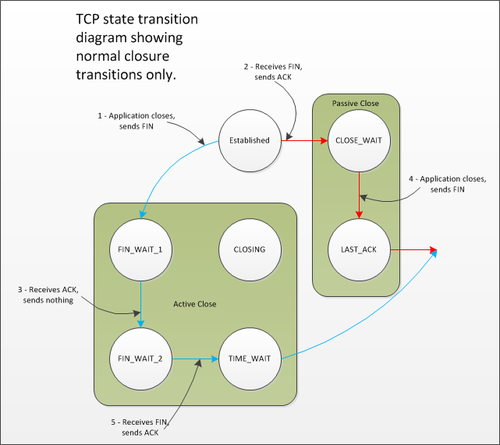
A TCP peer initiates an "active close" if it is the first peer to call Close() on the connection. In many protocols and client/server designs this is the client. In HTTP and FTP servers this is often the server. The actual sequence of events that leads to a peer ending up in TIME_WAIT is as follows.
TIME_WAIT is often also known as the 2MSL wait state. This is because the socket that transitions to TIME_WAIT stays there for a period that is 2 x Maximum Segment Lifetime in duration. The MSL is the maximum amount of time that any segment, for all intents and purposes a datagram that forms part of the TCP protocol, can remain valid on the network before being discarded. This time limit is ultimately bounded by the TTL field in the IP datagram that is used to transmit the TCP segment. Different implementations select different values for MSL and common values are 30 seconds, 1 minute or 2 minutes. RFC 793 specifies MSL as 2 minutes and Windows systems default to this value but can be tuned using the TcpTimedWaitDelay registry setting.
TIME_WAIT state 也称 2MSL wait state。这是因为转换为 TIME_WAIT 的套接字在此停留的时间为 2 个最大报文生存时间(MSL)。MSL 是 TCP 协议中任何报文在网络上最大的生存时间,任何超过这个时间的数据都将被丢弃。MSL 是由网络层的 IP 包中的 TTL来保证的(MSL 不与TTL 绝对相等,事实上 MSL 是 TCP 协议的假设基础)。不同的协议实现规定的 MSL 都不相同,通常为 30 seconds, 1 minute or 2 minutes。RFC 793 规定 MSL 为 2 minutes,Linux 默认为 30 seconds,windows 默认为 2 minutes,但是可以通过修改注册表 TcpTimedWaitDelay 的值来自定义。
The reason that TIME_WAIT can affect system scalability is that one socket in a TCP connection that is shutdown cleanly will stay in the TIME_WAIT state for around 4 minutes. If many connections are being opened and closed quickly then socket's in TIME_WAIT may begin to accumulate on a system; you can view sockets in TIME_WAIT using netstat. There are a finite number of socket connections that can be established at one time and one of the things that limits this number is the number of available local ports. If too many sockets are in TIME_WAIT you will find it difficult to establish new outbound connections due to there being a lack of local ports that can be used for the new connections. But why does TIME_WAIT exist at all?
There are two reasons for the TIME_WAIT state. The first is to prevent delayed segments from one connection being misinterpreted as being part of a subsequent connection. Any segments that arrive whilst a connection is in the 2MSL wait state are discarded.
TIME_WAIT 的存在主要有两个原因,第一个就是阻止前一个连接的延时报文被后续的连接错误接收(相同的五元组,不同的实例称为“化身”,这里指要阻止之前“化身”的报文被当前的连接错误接收)。一个连接处于 2 MSL 等待状态时,任何抵达的报文都将被丢弃(这里应该主要指数据报文,对于 FIN 报文还是要接收的,以便重新发送 ACK ,重新开始 2MSL 计时)。
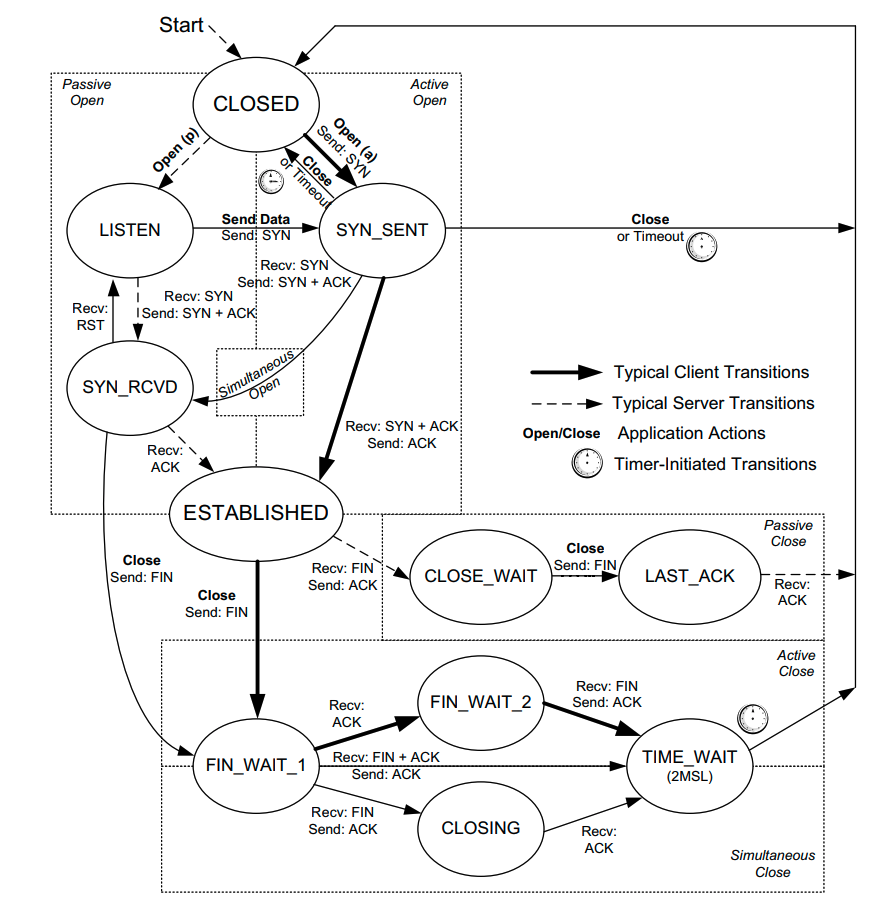
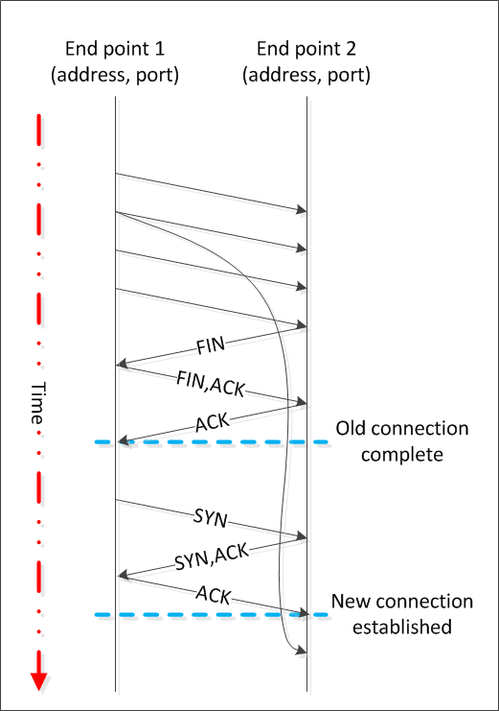
In the diagram above we have two connections from end point 1 to end point 2. The address and port of each end point is the same in each connection. The first connection terminates with the active close initiated by end point 2. If end point 2 wasn't kept in TIME_WAIT for long enough to ensure that all segments from the previous connection had been invalidated then a delayed segment (with appropriate sequence numbers) could be mistaken for part of the second connection...
上图有两个从 end point 1 到 end point 2 的连接,这两个连接的五元组相同(双方地址和端口相同)。第一个连接因 end point 2 主动关闭而终止,如果 end point 2 不在 TIME_WAIT 保持足够的时间以确保所有的报文在网络上失效的话,一个延迟的报文(拥有合适的 sequence number,意即对第二个连接来说是有效报文)会被第二个连接错误接收。
Note that it is very unlikely that delayed segments will cause problems like this. Firstly the address and port of each end point needs to be the same; which is normally unlikely as the client's port is usually selected for you by the operating system from the ephemeral port range and thus changes between connections. Secondly, the sequence numbers for the delayed segments need to be valid in the new connection which is also unlikely. However, should both of these things occur then TIME_WAIT will prevent the new connection's data from being corrupted.
The second reason for the TIME_WAIT state is to implement TCP's full-duplex connection termination reliably. If the final ACK from end point 2 is dropped then the end point 1 will resend the final FIN. If the connection had transitioned to CLOSED on end point 2 then the only response possible would be to send an RST as the retransmitted FIN would be unexpected. This would cause end point 1 to receive an error even though all data was transmitted correctly.
TIME_WAIT 存在的第二个原因就是:实现 TCP 的全双工连接可靠终止。如果 end point 2 最后发出的 ACK 丢失,依照 TCP 协议规则,end point 1 会重发 FIN。如果 end point 2 此时转为 CLOSED 状态,end point 2 的协议栈会响应一个 RST 报文,因为 这个重传的 FIN 并未被认可。 这将导致 end point 1 收获一个 error,即使所有的数据都已正确传输。
Unfortunately the way some operating systems implement TIME_WAIT appears to be slightly naive. Only a connection which exactly matches the socket that's in TIME_WAIT need by blocked to give the protection that TIME_WAIT affords. This means a connection that is identified by client address, client port, server address and server port. However, some operating systems impose a more stringent restriction and prevent the local port number being reused whilst that port number is included in a connection that is in TIME_WAIT. If enough sockets end up in TIME_WAIT then new outbound connections cannot be established as there are no local ports left to allocate to the new connection.
Windows does not do this and only prevents outbound connections from being established which exactly match the connections in TIME_WAIT.
Windows 不会这样做,它仅阻止建立与 TIME_WAIT 中的连接完全匹配的出站连接。
Inbound connections are less affected by TIME_WAIT. Whilst the a connection that is actively closed by a server goes into TIME_WAIT exactly as a client connection does the local port that the server is listening on is not prevented from being part of a new inbound connection. On Windows the well known port that the server is listening on can form part of subsequently accepted connections and if a new connection is established from a remote address and port that currently form part of a connection that is in TIME_WAIT for this local address and port then the connection is allowed as long as the new sequence number is larger than the final sequence number from the connection that is currently in TIME_WAIT. However, TIME_WAIT accumulation on a server may affect performance and resource usage as the connections that are in TIME_WAIT need to be timed out eventually, doing so requires some work and until the TIME_WAIT state ends the connection is still taking up (a small amount) of resources on the server.
Given that TIME_WAIT affects outbound connection establishment due to the depletion of local port numbers and that these connections usually use local ports that are assigned automatically by the operating system from the ephemeral port range the first thing that you can do to improve the situation is make sure that you're using a decent sized ephemeral port range. On Windows you do this by adjusting the MaxUserPort registry setting; see here for details. Note that by default many Windows systems have an ephemeral port range of around 4000 which is likely too low for many client server systems.
鉴于 TIME_WAIT 会因本地端口号的耗尽而影响到出站连接的建立,并且这些连接通常使用由操作系统从临时端口范围自动分配的本地端口,因此,你可以做的第一件事就是确保正在使用适当大小的临时端口范围。在 Windows 上你可以通过修改注册表选项 MaxUserPort 来自定义。请注意,默认情况下,许多 Windows 系统的临时端口范围约为 4000,这对于许多 C/S 系统而言可能太低了。
Whilst it's possible to reduce the length of time that socket's spend in TIME_WAIT this often doesn't actually help. Given that TIME_WAIT is only a problem when many connections are being established and actively closed, adjusting the 2MSL wait period often simply leads to a situation where more connections can be established and closed in a given time and so you have to continually adjust the 2MSL down until it's so low that you could begin to get problems due to delayed segments appearing to be part of later connections; this would only become likely if you were connecting to the same remote address and port and were using all of the local port range very quickly or if you connecting to the same remote address and port and were binding your local port to a fixed value.
Changing the 2MSL delay is usually a machine wide configuration change. You can instead attempt to work around TIME_WAIT at the socket level with the SO_REUSEADDR socket option. This allows a socket to be created whilst an existing socket with the same address and port already exists. The new socket essentially hijacks the old socket. You can use SO_REUSEADDR to allow sockets to be created whilst a socket with the same port is already in TIME_WAIT but this can also cause problems such as denial of service attacks or data theft. On Windows platforms another socket option, SO_EXCLUSIVEADDRUSE can help prevent some of the downsides of SO_REUSEADDR, see here, but in my opinion it's better to avoid these attempts at working around TIME_WAIT and instead design your system so that TIME_WAIT isn't a problem.
The TCP state transition diagrams above both show orderly connection termination. There's another way to terminate a TCP connection and that's by aborting the connection and sending an RST rather than a FIN. This is usually achieved by setting the SO_LINGER socket option to 0. This causes pending data to be discarded and the connection to be aborted with an RST rather than for the pending data to be transmitted and the connection closed cleanly with a FIN. It's important to realise that when a connection is aborted any data that might be in flow between the peers is discarded and the RST is delivered straight away; usually as an error which represents the fact that the "connection has been reset by the peer". The remote peer knows that the connection was aborted and neither peer enters TIME_WAIT.
上面的 TCP 转换图均展示的是有序连接终止。然而还有一种终止连接的方式,就是发送一个 RST 报文而不是 FIN 报文。一般是通过将 SO_LINGER 套接字选项设置为0来实现的。发送 RST 将导致待传输的数据(尚在发送缓冲区中)被丢弃,它不像发送 FIN 进行有序终止那样会等待数据被传送完成(一个 RST 报文会立即被送出,而 FIN 需要在缓冲区排队)。连接被终止时连接两端任何尚在流中的数据都将被丢弃,认识到这一点非常重要,因为 RST 报文会立即被传输;应用通常会收到“connection has been reset by the peer”的错误。这样远端就会意识到连接已经终止了,而且不会有任何一方进入 TIME_WAIT 状态。
Of course a new incarnation of a connection that has been aborted using RST could become a victim of the delayed segment problem that TIME_WAIT prevents, but the conditions required for this to become a problem are highly unlikely anyway, see above for more details. To prevent a connection that has been aborted from causing the delayed segment problem both peers would have to transition to TIME_WAIT as the connection closure could potentially be caused by an intermediary, such as a router. However, this doesn't happen and both ends of the connection are simply closed.
There are several things that you can do to avoid TIME_WAIT being a problem for you. Some of these assume that you have the ability to change the protocol that is spoken between your client and server but often, for custom server designs, you do.
For a server that never establishes outbound connections of its own, apart from the resources and performance implication of maintaining connections in TIME_WAIT, you need not worry unduly.
For a server that does establish outbound connections as well as accepting inbound connections then the golden rule is to always ensure that if a TIME_WAIT needs to occur that it ends up on the other peer and not the server. The best way to do this is to never initiate an active close from the server, no matter what the reason. If your peer times out, abort the connection with an RST rather than closing it. If your peer sends invalid data, abort the connection, etc. The idea being that if your server never initiates an active close it can never accumulate TIME_WAIT sockets and therefore will never suffer from the scalability problems that they cause. Although it's easy to see how you can abort connections when error situations occur what about normal connection termination? Ideally you should design into your protocol a way for the server to tell the client that it should disconnect, rather than simply having the server instigate an active close. So if the server needs to terminate a connection the server sends an application level "we're done" message which the client takes as a reason to close the connection. If the client fails to close the connection in a reasonable time then the server aborts the connection.
On the client things are slightly more complicated, after all, someone has to initiate an active close to terminate a TCP connection cleanly, and if it's the client then that's where the TIME_WAIT will end up. However, having the TIME_WAIT end up on the client has several advantages. Firstly if, for some reason, the client ends up with connectivity issues due to the accumulation of sockets in TIME_WAIT it's just one client. Other clients will not be affected. Secondly, it's inefficient to rapidly open and close TCP connections to the same server so it makes sense beyond the issue of TIME_WAIT to try and maintain connections for longer periods of time rather than shorter periods of time. Don't design a protocol whereby a client connects to the server every minute and does so by opening a new connection. Instead use a persistent connection design and only reconnect when the connection fails, if intermediary routers refuse to keep the connection open without data flow then you could either implement an application level ping, use TCP keep alive or just accept that the router is resetting your connection; the good thing being that you're not accumulating TIME_WAIT sockets. If the work that you do on a connection is naturally short lived then consider some form of "connection pooling" design whereby the connection is kept open and reused. Finally, if you absolutely must open and close connections rapidly from a client to the same server then perhaps you could design an application level shutdown sequence that you can use and then follow this with an abortive close. Your client could send an "I'm done" message, your server could then send a "goodbye" message and the client could then abort the connection.
TIME_WAIT exists for a reason and working around it by shortening the 2MSL period or allowing address reuse using SO_REUSEADDR are not always a good idea. If you're able to design your protocol with TIME_WAIT avoidance in mind then you can often avoid the problem entirely.
有一次,我在编写一个 Go 程序,这个程序要做的一件事是在操作系统上执行一个命令(可执行文件或者可执行脚本),程序大概像下面这样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
cmdSlice := strings.Fields(strings.TrimSpace(cmdString)) iflen(cmdSlice) == 0 { return errors.New("index out of range [0] with length 0") } // search for an executable named file in the // directories named by the PATH environment variable. // If file contains a slash, it is tried directly and the PATH is not consulted. // The result may be an absolute path or a path relative to the current directory. executableFile, err := exec.LookPath(cmdSlice[0]) if err != nil { return errors.WithStack(NewPathError(cmdSlice[0], err.Error())) }
可以想见,当 rc.d 中有大量的脚本,且脚本中又有成百上千个类似于 awk、sed、grep 这样的命令时,系统的启动过程就会变得漫长。当然对于启停不那么频繁的服务器来说,这依然可以接受,而且这样的系统设计也很符合 Unix 设计哲学:Do one thing and Do it well,所以 sysvinit 可以一统江湖几十年。直到 2006年 Linux 内核进入 2.6 时代,Linux 开始进入桌面系统,而桌面系统和服务器系统不一样的是,桌面系统面临频繁重启,而且,用户会非常频繁的使用硬件的热插拔技术。于是,在这些新的使用场景下,sysvint 开始变得不合时宜了。
更详细的 sysvint 介绍可以参考 浅析 Linux 初始化 init 系统-sysvinit
步行夺猛马的 Systemd
历史上总是会有人站出来对现状说不,2010 年 Lennart Poettering 和他的小伙伴们开源并发布了一个新的 init 系统——Systemd。
要讲清楚shell是一个十分艰巨的任务,对于只查过几天资料的我来说自然无法胜任,但是择其一两点来讲,以多少理清一些 Linux 下程序启动与运行的原理为目的,或可一试。
文中涉及到关于 shell 的实验或者结论皆以 Bash 作为参考依据。
What is a shell?
Bash 主页上有关于 shell 的定义:
At its base, a shell is simply a macro processor that executes commands. The term macro processor means functionality where text and symbols are expanded to create larger expressions.
对于 Unix shell 来说,它既是一个命令行解释器也是一个编程语言。shell 作为命令行解释器为丰富的 GNU 工具集提供了用户接口,而作为编程语言它成功的将这些工具集结合在一起,之后就可以将命令编写进文件,去完成各种各样的任务。
很多人可能傻傻分不清 terminal、tty、console 和 shell,这里第一个高票回答对这些概念做了详细的解释:What is the exact difference between a 'terminal', a 'shell', a 'tty' and a 'console'?。如果英文阅读不畅,知乎上有人将其翻译了一下:终端、Shell、tty 和控制台(console)有什么区别?,我不再做额外的阐述了,接下来只需要记住 shell 是一个命令行解释器就好,它可以运行在交互模式和非交互模式。
this execution fails because the file is not in executable format, and the file is not a directory, it is assumed to be a shell script and the shell executes it as described in Shell Scripts.
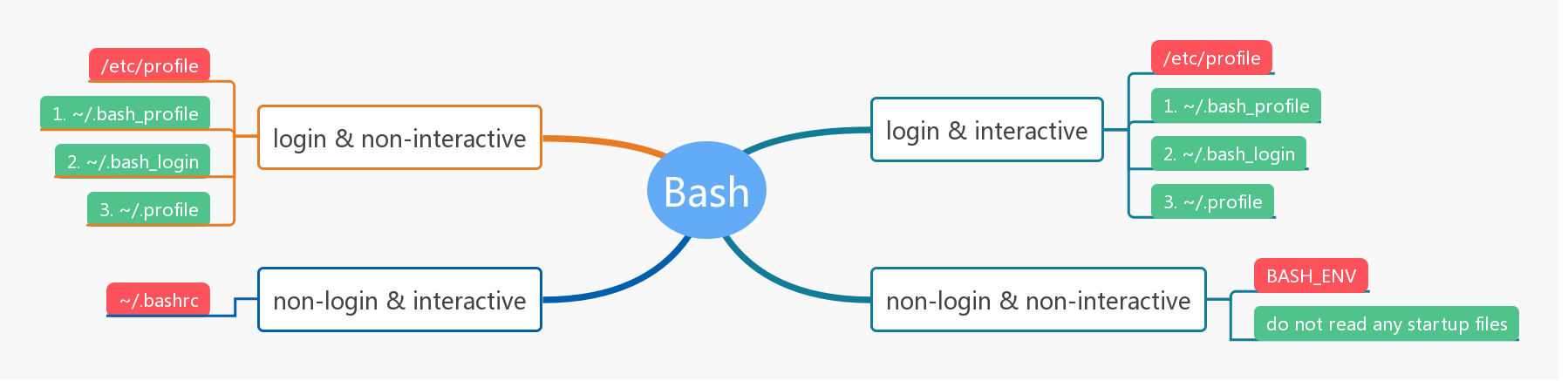
来做个实验吧,我事先在 /etc/profile、/etc/bashrc、~/.bash_profile、~/.bashrc 中增加了 echo “Hello from xxxx” 的语句,让我们来看看各种情况下我们得到的 shell 到底执行了哪些文件:
sshd
1 2 3 4 5 6
{11:07}~ ➭ ssh root@192.168.1.41 Last login: Wed Dec 4 10:44:06 2019 from 192.168.1.183 Hello from /etc/profile Hello from /etc/bashrc Hello from ~/.bashrc Hello from ~/.bash_profile
[root@afis-db ~]# bash Hello from /etc/bashrc Hello from ~/.bashrc [root@afis-db ~]# exit exit [root@afis-db ~]# bash -l Hello from /etc/profile Hello from /etc/bashrc Hello from ~/.bashrc Hello from ~/.bash_profile
[root@afis-db ~]# ./script.sh I am script! [root@afis-db ~]# bash script.sh I am script! [root@afis-db ~]# bash -l script.sh Hello from /etc/profile Hello from /etc/bashrc Hello from ~/.bashrc Hello from ~/.bash_profile I am script!
可见在非交互模式下不会读取任何文件,增加了登录选项则会依次读取 Startup Files。
我们很少以 bash script.sh 这种方式执行脚本,更多的是以 ./script.sh运行,当以后一种方式执行时,真正执行脚本的解释器依赖于具体的 Shebang。而我们经常看到使用 sh script.sh 这样的方式执行,那 sh 究竟是什么呢?
在大多数 Linux 发行版中,sh 通常是 bash 的软连接,但是 bash 文章中有如下描述:
If Bash is invoked with the name sh, it tries to mimic the startup behavior of historical versions of sh as closely as possible, while conforming to the POSIX standard as well.
When invoked as sh, Bash enters POSIX mode after the startup files are read.
[root@afis-db ~]# sh sh-4.1# exit exit [root@afis-db ~]# sh -l Hello from /etc/profile Hello from ~/.profile.(this file is touched by me)
执行脚本
1 2 3 4 5 6
[root@afis-db ~]# sh script.sh I am script! [root@afis-db ~]# sh -l script.sh Hello from /etc/profile Hello from ~/.profile.(this file is touched by me) I am script!
2004年,Solaris Containers 发布,它也是秉承了 jail 的思想,为进程提供一个隔离的沙盒,进程在其中独立运行。它也被称为“吃了类固醇的 chroot ”(chroot on steroids)。
不过,无论是 FreeBSD Jails ,还是紧接着出现的 Solaris Containers ,都没有能在更广泛的软件开发和交付场景中扮演到更重要的角色。在这段属于 Jails 们的时代,进程沙箱技术因为“云”的概念尚未普及,始终被局限在了小众而有限的世界里。就如同集装箱刚刚出现的那十年,所有和集装箱配套的设施都还没有,整个社会都还没有为集装箱做好准备。你看,他们两者不仅意义上相近,就连命运也如出一辙。
可见,任何一种新技术,即便问世很早,可要整个社会系统去适应它,却需要一个无比漫长的过程。
让我们回到容器技术上来,事实上,在 Jails 大行其道的这几年间,同样在迅速发展的 Linux 阵营上也陆续出现多个类似的沙箱技术比如 Linux VServer 和 Open VZ (未进入内核主干)。但如同那些 jail 的前辈一样,受当时计算机环境的制约,被局限在一个小众的圈子里。
早在 2002 年,Plan 9 from Bell Labs(Go语言的运行时就是使用的该操作系统的汇编器语法)操作系统对 Namespace 的广泛运用为 Linux 带来了灵感, Linux 在其内核 2.4.19 版本上加入了 Namesapce 功能(可以实现对应资源的隔离)。最初只有mount namespace,后续的pid、net、ipc、UTS、user等一直到内核3.8版本才实现完成。内核4.6中又添加了Cgroup namespace。
2007年,一种名叫 Process Container 技术的发布。它是由 Google 的工程师 Paul Menage 和 Rohit Seth 发起并实现的,旨在对一组进程进行资源上的隔离、限制。在合并入 Linux 内核的时候,由于 Linux 中存在 Container 的概念,故被重命名为 Cgroups 。
Kubernetes 源于 Google 内部的 Borg 项目,经 Google 使用 Go 语言重写后,被命名为 Kubernetes,并于 2014 年 6 月开源。Kubernetes 希腊语意思是“舵手”,致力于管理数以万计的容器集群。你看舵手不正是隐喻了方向和流动么。因其开头字母和结尾字母之间共有 8 个字,所以简短的称其为k8s。