Go语言中的new和make-从函数阻击战到nil遭遇战
Go语言中有两个builtin函数new和make,这个两个函数经常让初学者摸不着头脑,也许使用过程中并未有什么阻碍,但回过头看细想又难以说清道明。本文将针对这两个函数进行分析,希望能抽丝剥茧,彻底搞清楚他们的区别。
函数定义
当然,我们先看Go官方对这两个函数的解释:
func new(Type) *Typel
The new built-in function allocates memory. The first argument is a type, not a value, and the value returned is a pointer to a newly allocated zero value of that type.
大意:new函数会分配内存,它唯一的一个参数是type不是value,返回值是一个指针,指向刚刚分配的那块内存,并且这块内存中存储着type的零值(zero value)。
重点:
- 分配内存
- 返回指向这块内存的指针
- 内存存储
type的零值
func make(t Type, size ...IntegerType) Type
The make built-in function allocates and initializes an object of type slice, map, or chan (only). Like new, the first argument is a type, not a value. Unlike new, make's return type is the same as the type of its argument, not a pointer to it.
大意:make仅用于分配和初始化slice、map、chanel,同new一样,第一个参数要传入一个type;不同的是,make返回的是初始化过之后的type的一个值,而不是指针。
重点:
- 分配内存并初始化
- 仅用于
slice、map、chanel - 返回的是值,不是指针
zero value
上文提到new()会分配内存,并且为相应的Type存储零值,那什么是零值呢?官方对于zero value的描述如下:
When storage is allocated for a variable, either through a declaration or a call of new, or when a new value is created, either through a composite literal or a call of make, and no explicit initialization is provided, the variable or value is given a default value. Each element of such a variable or value is set to the zero value for its type: false for booleans, 0 for numeric types, "" for strings, and nil for pointers, functions, interfaces, slices, channels, and maps. This initialization is done recursively, so for instance each element of an array of structs will have its fields zeroed if no value is specified.
大意:当通过声明或调用new为变量分配存储时,或者在创建新值时(通过复合字面值或调用make),并且没有提供显式初始化时,将为变量或值提供默认值。此类变量或值的每个元素的类型都设置为该类型的零值:布尔值为false,数值类型为0,字符串为"",指针、函数、接口、片、通道和映射为nil。这个初始化是递归完成的,因此,如果结构体中没有指定相应field的值,那么默认将是该field的零值。
下面表格中展示了Go中主要类型的零值:
| Type | Zero Value |
|---|---|
| boolean | false |
| numeric | 0 |
| string | "" |
| pointer | nil |
| function | nil |
| interface | nil |
| slice | nil |
| map | nil |
| channel | nil |
其中,array和struct两个复合类型的零值为其承载的基础类型的零值,因为array和struct都是值类型,不像slice、map是引用类型。
但是,个人感觉上面一段话中关于通过复合字面值或调用make创造值的相关描述略有不准确。因为Composite literals(复合字面值)是为structs、arrays、slices、maps构造值,而make仅用于分配并初始化slice、map、chanel。如果使用字面值构造一个值且不显示的初始化,那么该值就是一个空值(empty),和make的结果相同,而不是零值nil。看下面这段代码:
1 | var nilSlice []string |
像slice、map这样的引用类型的零值是nil,并不是“the variable or value is given a default value”,因为通过复合字面值或调用make构造变量时default value是empty。(如果有人觉得这是咬文嚼字,那我也只能承认,毕竟nil让我很痛苦,后面我会再论述default value)。
一个nil的slice和一个Empty的slice很容易让你迷惑,它们都被fmt.Println打印出[],它们拥有相同的length和capacity。
除非nil或者Empty会对你的逻辑产生影响,否则不用区别对待它们。如果你需要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断。除了和nil相等比较外,一个nil值的slice的行为和其它任意0长度的slice一样。
另一个值得注意的问题是,当你使用encoding/json时,你要特别注意:Golang的encoding/json会将Nil Slice编码为null。
what is nil?
nil的定义
nil 为预声明的标示符,定义在builtin/builtin.go,
1 | // nil is a predeclared identifier representing the zero value for a |
可见,nil没有默认类型,它是一个预定义好的变量,有多种可能的类型(pointer、map、slice、function、channel、interface)。它代表指针、通道、函数、接口、映射或切片的零值。
你必须给编译器以足够的信息,使得编译器可以推导出nil的类型,因此下面的使用方式是非法的:
1 | var n = nil // illegal, doesn't compile |
正确的做法如下:
1 | func main() { |
nil的地址
各种类型的nil的内存布局始终相同,换一句话说就是:不同类型nil的内存地址是一样的。
1 | func main() { |
可见,值为nil的变量都指向同样的内存地址0x0,这是一个无效的地址,如果对这个地址进行读写,会引发panic:
1 | func main() { |
1 | panic: runtime error: invalid memory address or nil pointer dereference |
我们来看一下这段代码的plan9汇编指令:
1 | go tool objdump -s main.main test |
从汇编指令可以看到,AX寄存器被清零,之后试图将0xa(10)写入AX指向的内存地址,然后就导致了panic。
现在我们可以作如下总结:
非引用类型一旦赋予default value(或者说zero value),那么将会实际分配内存,并且内存中数据初始化为相应类型的zero value;而零值为nil的类型都是引用类型,其背后引用了使用前必须初始化的数据结构,它们的default value为nil,尚未分配内存,相应的数据结构也未被初始化。例如,slice是一个三元描述符,包含一个指向数据(在数组中)的指针、长度、以及容量,在这些项被初始化之前,slice都是nil的。对于slice,map和channel,make初始化这些内部数据结构,并准备好可用的值(对应类型的zero value)。
不是关键字
另一个值得注意的地方:nil不是Go的关键字,你可以重写他,但是最好不要这样做:
1 | func main() { |
kinds of nil
我们知道nil的种类有pointer, channel, func, interface, map, or slice,下面分别讨论一下这几种类型的nil行为。
先说明一下这几种类型的nil含义:
| Type | meaning |
|---|---|
| pointer | 什么也不指向 |
| function | 没有初始化 |
| interface | 没有赋值,空指针 |
| slice | 没有底层数组 |
| map | 没有初始化 |
| channel | 没有初始化 |
pointer
在go中,指针指向一个内存地址,同c/c++中一样,但go中的指针没有指针运算,所以是安全的。可以有以下几种方式生成pointer:
1 | func main() { |
上述代码我故意用了slice的指针类型,因此当pNew不是nil的时候,*pNew依然是nil。
nil的指针无法解引用,如果试图对一个nil的指针解引用的话会产生panic。
但是Nil却可以作为合法的接收器:
1 |
|
slice
slice的底层是一个数组,那么一个nil的slice是没有底层数组的。一个nil的或者长度为0的非nil的slice都无法被索引,但是可以使用append去填充值。下面代码展示了各种构造slice的方式,以及nil的情况:
1 | func main() { |
Slice小结:
1. 显示声明、未初始化值时为nil
2. 使用new函数生成slice为nil
3. 字面值初始化的slice,未提供具体值的为Empty,不是nil,但长度和容量与nil相同都为0
4. 使用make初始化的slice未提供长度和容量的为Empty,提供的初始化为相应类型的零值
5. nil和Empty的slice(长度为0)无法被索引
6. 使用for...range遍历nil的slice不会迭代,也不会报错
map
map的底层是一个哈希表,通过内置的make函数可以快速构建一个map。make创建map时,实际底层调用的是makemap函数,返回值是一个结构体指针。
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
使用make可以选填capacity ,capacity 不限制map的大小,map会自适应增长,但是nil的map除外。除了不允许添加元素以外,nil的map等价于Empty的map。
1 | func main() { |
map小结:
1. 显示声明、未初始化值时为nil
2. 使用new函数生成的map为nil
3. nil的map只读,无法写入
4. map读取,如果没有要读取的key,则返回key对应类型的零值
5. delete时如果map为nil或者key不存在则什么也不做
5. map 并不是一个线程安全的数据结构。同时读写一个 map 是未定义的行为,如果被检测到,会直接 panic。
6. 使用for...range遍历nil的slice不会迭代,也不会报错
channel
一个未被make初始化的channel是nil的,channel是通过make来初始化的,make在创建channel时底层调用了makechan函数,返回值是一个结构体指针。
func makechan(t *chantype, size int64) *hchan
这里不去讨论详细的channel用法,仅仅对nil的情况做一下阐述。
读写一个nil的channel会造成永远阻塞。
1
2
3var ch chan int
<- ch // block1
2
3var ch chan int
ch <- 1 // block关闭一个nil的channel会产生panic。
1
2
3var ch chan int
close(ch) // panic: close of nil channel往一个已经关闭的channel发送数据会产生panic
1
2
3
4
5ch := make(chan int)
close(ch)
ch <- 1 // panic: send on closed channel从一个已关闭的channel接收数据会收到最后发送的数据或者对应类型的零值
1
2
3
4
5ch := make(chan int, 1)
ch <- 1
close(ch)
fmt.Println(<-ch) // Output: 1
fmt.Println(<-ch) // Output: 0for...range语句会自动感知channel的关闭,但遇到nil会永远阻塞
利用for...range优雅退出协程:
1
2
3
4
5
6
7go func(in <-chan int) {
// Using for-range to exit goroutine
// range has the ability to detect the close/end of a channel
for x := range in {
fmt.Printf("Process %d\n", x)
}
}(inCh)遍历nil的通道:
1
2
3
4
5var tc chan int
// 永远阻塞
for v := range tc {
fmt.Println(v)
}
function
function和map、channel一样底层是一个指针,如果一个函数没有被初始化,那么它就是nil的
1 | var myFun func(int) string |
interface
interface是比较有意思的一个类型,也是go能够具有面向对象特征以及多态基石,它是一个结构体,包含了动态类型和动态值。
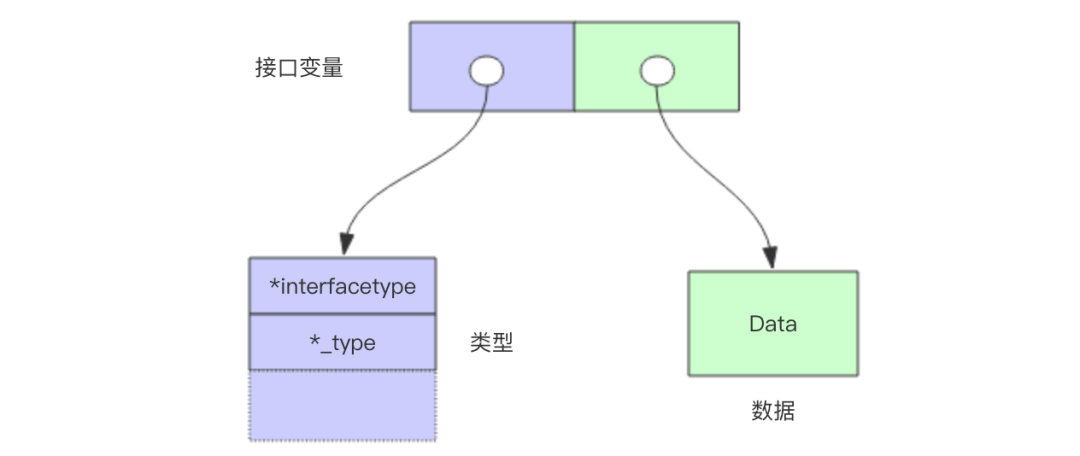
对于一个接口的零值就是它的类型和值的部分都是nil, 只有都为nil的情况下接口值 == nil才成立。
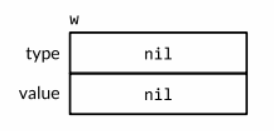
调用一个空接口值上的任意方法都会产生panic
1
2
3
4
5var w io.Writer
fmt.Println(w == nil) // Output: true
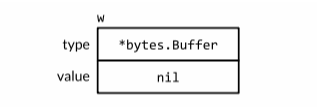
w.Write([]byte("hello")) // panic: nil pointer dereference一个不包含任何值的nil接口值和一个刚好包含nil指针的接口值是不同的(
此时nil不是nil)1
2
3
4
5
6
7
8
9
10
11
12func main() {
var buf *bytes.Buffer
f(buf) // NOTE: subtly incorrect!
}
// If out is non-nil, output will be written to it.
func f(out io.Writer) {
// ...do something...
if out != nil {
out.Write([]byte("done!\n"))
}
}上述示例,虽然我们给函数
f传入了一个nil的指针(*bytes.Buffer),但是go将out的动态类型设为了*bytes.Buffer,动态值设为nil,意思就是out变量是一个包含了nil指针值的非nil接口,所以out != nil仍然为true,nil经过一道赋值的关卡后已不再是nil。
the use of nil
nil并不总是为我们制造困难,有些时候也有其妙用。
nil的指针可以作为合理的方法接收者1
2
3
4
5
6
7
8
9
10
11
type PointerReciver int
func (a *PointerReciver) showme(){
fmt.Printf("Yeah, it works!")
}
func main() {
var ta *PointerReciver
ta.showme() // Yeah, it works!
}nil的slice可以正常的append1
2
3
4var s []int
for i:=0; i <10; i++ {
s = append(s,i)
}nil的map是只读的, 当你需要一个空map参数时可以使用nil1
2
3
4
5
6
7
8
9
10func NewGet(url string, headers map[string]string) (*http.Request, error) {
req, err := http.NewRequest(http.MethodGet, url, nil)
if err != nil {
return nil, err
}
for k, v := range headers {
req.Header.Set(k, v)
}
return req, nil
}你可能想做如下调用,传入空的map
1
2
3
4req, err := NewGet(
"http://google.com",
map[string]string{},
)你只需传入一个nil即可:
1
req, err := NewGet("http://google.com", nil)
nil的通道永远阻塞有时候我们可以利用
nil通道的阻塞特性,比如有如下代码:1
2
3
4
5
6
7
8
9
10func merge(out chan<- int, a, b <-chan int) {
for {
select {
case v := <-a:
out <- v
case v := <-b:
out <- v
}
}
}这个函数不断的从通道a和b读取数据,然后写入out通道,如果a和b其中有通道关闭,根据关闭通道的特性,我们知道会从 读取到对应类型的零值,那么如何才能跳过已经close的分支呢?
对一个nil的channel发送和接收操作会永远阻塞,在select语句中操作nil的channel永远都不会被select到。1
2
3
4
5
6
7case v, ok := <-a:
if !ok {
a = nil
fmt.Println("a is now closed")
continue
}
out <- vnil的接口
不用多说了
1
2
3if err != nil {
// do somthing
}
总结
本篇文章通过探索new和make的用法,揭示了go中初始化变量的一些规律,避免新手gopher使用过程中的困惑,对于这两个内置方法的使用时机,我个人的看法是:如果你需要初始化一个slice、map、chan类型的变量,那么优先使用make;如果你需要一个指针接收器或者明确需要一个指针的时候,new会是一个不错的选择。
在查阅new和make的过程中,我们遭遇了恼人的nil,本文也通过一些浅薄的分析,总结出了nil的一些规律,希望能给阅读本文的人带来一些帮助,同时也作为个人学习中的笔记可以随时翻阅,加强理解。
参考文章:
- The Go Programming Language Specification
- video:Understanding nil
- nils in Go
- Golang: Nil vs Empty Slice
- 深入学习golang(4)—new与make
- 深度解密Go语言之slice
- 深度解密Go语言之map
- 深度解密Go语言之channel
- 深度解密Go语言之关于interface的 10 个问题