重学C语言:编译和链接那些事儿(一)—— 编译过程
大学时用 Turbo C 2.0 学 C 语言,只记得是蓝底黄字的丑陋界面,不清楚编译完的程序有何用处,也不知道编译和链接这些基本概念。现在想来只学到了 C 的语法,几年下来也忘得精光。本篇以 Linux 下 GCC 为例,简单描述编译链接的过程。
GCC 隐藏的细节
我们首先使用 GCC 来编译并运行一个经典的hello world程序:
1 |
|
使用 GCC 来编译:
1 | {14:59}~/Learing/c/src:master ✗ ➭ gcc hello.c |
可以看到在不指定 -o选项的时候,默认生成了一个 a.out文件,这就是最后的可执行程序,我们来执行它:
1 | {14:59}~/Learing/c/src:master ✗ ➭ ./a.out |
程序向标准输出打印了 hello world!,我们的程序执行成功。但是 GCC 期间做了哪些工作?a.out 是一步生成的么?
事实上,这个默认过程至少经历了四个阶段,分别是预处理、编译、汇编和链接,如下图所示:
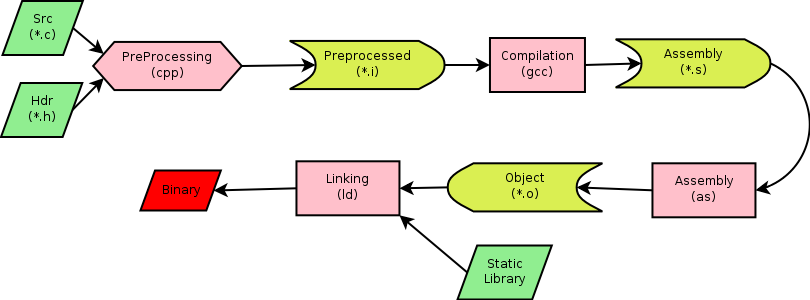
预编译
第一阶段的工作就是预处理,由预处理器完成,处理和源代码相关的头文件,生成一个 .i 后缀的中间文件。C 预处理器(C Pre-Processor)也常简写为 CPP,是一个与 C 编译器独立的小程序,预编译器并不理解 C 语言语法,它仅是在程序源文件被编译之前,实现文本替换的功能。可以使用 GCC 的 -E 选项来控制只进行预编译:
1 | gcc -E hello.c -o hello.i |
预编译阶段主要是处理源文件中以 #开头的预编译指令。比如 #include 、#define 等,主要的规则如下:
- 将所有的
#define删除,并展开所有的宏定义。 - 处理所有的条件预编译指令,比如
#if、#ifdef、#elif、#else、#endif。 - 处理
#include预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其它文件。 - 删除所有的注释
//和/* */。
编译
接下来就是整个程序构建最核心的阶段—编译,通过对预处理阶段产生的结果文件进行一些列的词法分析、语法分析、语义分析以及某些编译器优化之后生成汇编代码文件。编译的过程可以使用如下命令单独进行:
1 | gcc -S hello.i -o hello.s |
其实目前的 GCC 已经将预编译和编译两个阶段合而为一了,使用一个叫 ccl 的程序来完成这两个步骤,我的机器上这个程序在 /usr/lib/gcc/x86_64-pc-linux-gnu/9.3.0/cc1 ,我们可以直接调用它来完成预编译和编译:
1 | {16:12}~/Learing/c/src:master ✗ ➭ /usr/lib/gcc/x86_64-pc-linux-gnu/9.3.0/cc1 hello.c |
或者,可以直接通过 gcc 和源文件来编译成汇编代码:
1 | gcc -S hello.c -o hello.s |
通过这些方式都可以得到 hello.s 的汇编文件。事实上 GCC 是个编译工具集,会根据不同的情况调用不同的工具处理每阶段的工作,比如编译时调用 ccl,汇编时调用 as,链接时调用 ld。
汇编
正如前文所言,当编译完成得到汇编文件之后,接下来的工作就交给汇编器来执行了,汇编器是将汇编代码转变成机器指令的工具,每一条汇编语句几乎都对应一条机器指令。所以汇编器的活儿相对来说比较简单,只是把汇编指令跟机器指令对照翻译一下,当然翻译完文件就由可读的汇编代码变为只有机器才可以看懂的二进制文件了。对于上面得汇编文件我们可以使用 as 来完成汇编:
1 | as hello.s -o hello.o |
或者使用 GCC 的 -c 选项,它的意思是编译或者汇编源文件,但不进行链接:
1 | gcc -c hello.s -o hello.o |
或者直接从 C 文件到目标文件(Object File 的概念非常重要,但此处不展开,留待以后单独讨论):
1 | gcc -c hello.c -o hello.o |
链接
到这里,我们距离生成最后的可执行文件只有一步之遥,让我们来调用 ld 来生成最后的可执行文件:
1 | /usr/bin/ld -static /usr/lib/crt1.o /usr/lib/crti.o /usr/lib/gcc/x86_64-pc-linux-gnu/9.3.0/crtbeginT.o -L /usr/lib/gcc/x86_64-pc-linux-gnu/9.3.0 -L /usr/lib -L /lib hello.o --start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/x86_64-pc-linux-gnu/9.3.0/crtend.o /usr/lib/crtn.o -o hello |
执行 hello 程序:
1 | {17:00}~/Learing/c/src:master ✗ ➭ ./hello |
程序成功执行并输出了 hello world!,但是我们可以看到上面的 ld 命令链接了一大堆的文件才最后生成 hello 可执行文件。
初学者很容易产生的疑问就是:汇编完成的之后的文件不就是二进制文件么?为什么还要进行链接这个步骤呢?链接到底干了些啥?为什么不直接生成最后的可执行文件呢?要说清楚这些问题并不是一件很容易的事,可以说是一件异常困难的事,这里面涉及到静态链接、动态链接、静态库、动态库、运行时库、标准库、链接器等一系列的问题,以至于《程序员的自我修养》用了整整一部书来讲链接这件事情,所以囫囵吞枣看个大概的想法,也是何其难哉!
但这正是我想写这一系列文章的初衷,我希望我能将这些概念总结出来,略去一些细节,只保留轮廓,便于记忆,同时也给初学者以借鉴。
本篇文章先简单描述编译的过程,下一篇文章我们谈静态链接。