Stack 顿悟三部曲(3):溯源 goroutine 堆栈
通过 从CPU的视角说起 和 穿越虚拟内存的迷雾 两篇文章我们知道,所谓进程堆栈不过是应用程序向内核申请了一块连续内存后,设定相应的寄存器,从而将这块内存当做堆栈来使用,典型的用法就是用于函数调用。
我们在上一篇讨论了进线程的堆栈,现在继续探索 go 中的协程栈。如果吊一下书袋的话,口称 go 协程是不严谨的,go 的协程不同于其他语言的协程,go 的协程是一种有栈协程,每一个协程都有自己的协程堆栈,因此 go 官网发明了一个新词 goroutine,以区别于普通的 coroutine。我们接下来就聊聊 goroutine 的堆栈。在此之前,先来回顾一下上一篇中对进线程堆栈位置的总结。
本文基于 Linux 平台 x64 架构,使用 go 1.18 源码,禁用 cgo
1· 进线程堆栈

图 3.1 为 64 位虚拟地址空间布局图,粉色标识说明了线程堆栈可能存在的位置,总结下来,不外乎以下三种情况:
- 主线程堆栈位于用户空间顶部,但 clone 时,子进程的主线程实际使用的堆栈未必如此。
- 有可能分配在 mmap 区域。
- 有可能通过 C 库 malloc 分配在 heap 区域。
2. goroutine 的堆栈
或许你已经知道 goroutine 的堆栈是从 heap 上分配的,但如果你足够好奇,你就会为 heap 在虚拟地址空间中的位置而发狂。
go 重写了运行时,如果不使用 cgo 的话,编译完成的 go 程序是静态链接的,不依赖任何C库,这使它拥有不错的可移植性,在较新内核上编译好的程序,拉到旧版本内核的操作系统上依然能够运行。在这一点上,rust 并没有多少优势,反而新生语言 hare 表现足够强劲。
不依赖 C 库,意味着 go 对 heap 的管理有自己的方式。 那么, go 管理的 heap 是否与之前内存空间布局图中的 heap 位置相同就要打一个大大的问号了。要搞清楚这个问题,我们需要到 runtime 的源码中一探究竟,且要挖到 go 与内核的接口处,找出其申请内存的方式方可。
本文并不打算分析 go 的内存分配器,也不打算介绍堆栈的分配算法,仅仅为了解决 goroutine 堆栈在虚拟地址空间中位置的疑惑。想了解内存管理和堆栈分配算法的读者可以参考详解Go中内存分配源码实现与一文教你搞懂 Go 中栈操作。
先从普通 goroutine 的创建开始吧!
在 go 中,每通过go func(){}的方式开启一个 goroutine 时,编译器都会将其转换成对 runtime.newproc的调用:
1 | // Create a new g running fn. |
newproc 仅仅是对 newproc1 的包装,创建新 g 的动作不能在用户堆栈上进行,所以这里切换到底层线程的堆栈来执行。
1 | // Create a new g in state _Grunnable, starting at fn. callerpc is the |
newproc1 方法很长,里面主要是获取 G ,然后对获取到的 G 做一些初始化的工作。当创建 G 时,会先从缓存的空闲链表中获取,如果没有空闲的 G ,再进行创建。所以,我们这里只看 malg 函数的调用。
在调用 malg 函数的时候会传入一个最小堆栈大小值:**_StackMin**(linux 平台下为 2048)。
1 | // Allocate a new g, with a stack big enough for stacksize bytes. |
malg 会创建新的 G 并为其设置好堆栈,以及堆栈的边界,以供日后扩容使用。这里重点看 stackalloc 函数,堆栈的内存的分配就是由它来完成的,函数的返回值赋给新 G 的 stack 字段。
G 的 stack 字段是一个 stack 结构体类型,里面标记了堆栈的高地址和低地址:
1 | // Stack describes a Go execution stack. |
我们接着看这个 stack 是怎么创建出来的。
stackalloc 的函数比较长,里面涉及到大堆栈和小堆栈的分配逻辑,这里就不贴大段的代码了。这个函数不管是从 cache 还是 pool 中获取内存,最终都会在内存不够时调用 mheap 的allocManual函数去分配新的内存:
1 | mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack) |
到这里就遇见 go 管理的 heap 了,关于 heap 的位置我们稍后再讨论,现在继续挖 allocManual 直到我们找到系统调用为止。
1 | func (h *mheap) allocManual(npages uintptr, typ spanAllocType) *mspan { |
allocManual 只是对 allocSpan 的简单封装,这里简单提一下 go 对内存管理的最小单位是 mspan,它包含若干连续的页。
allocSpan 的逻辑较多,主要是从 heap 中分配 npages 个页来填充 span。一般随着程序的运行,内存的不断申请,heap 中会有很多空闲的页用来供给后续的内存申请。现在我们需要查看 cache 不足的情况,当 heap 中的 page 不够的时候,就需要推动 heap 增长了,allocSpan 通过调用 mheap.grow 来达成这一点。
1 | // Try to add at least npage pages of memory to the heap, |
当curArena的空闲内存(内核返回的内存空间往往会比请求的多一些)不足以满足分配时,调用mheap.sysAlloc来申请更多的空间。
1 | func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) { |
这里真正申请内存的操作是 sysReserve,让我们来一睹究竟:
1 | func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer { |
熟悉的 mmap 映入眼帘!我们已经抵达了内核的大门,查看其定义发现,它包裹了一个sysMmap函数,该函数就是发起mmap系统调用的所在,它是由汇编语言写成,Linux 下函数体位于 sys_linux_amd64.s 中:
1 | // sysMmap calls the mmap system call. It is implemented in assembly. |
mmap调用中的 flag _PROT_NONE, _MAP_ANON|_MAP_PRIVATE表示申请的内存块是无文件背景的匿名映射,这里在调用时传入了一个提示地址,用于告知内核尽量从要求的地址开始分配。
内核当然不能保证这一点,但 go 也足够倔强,如果不能保证连续增长,就另找一段空间开始:
1 | // 如果不相等,则说明 mmap 在建议的地址上没能分配成功 |
从 sysAlloc 返回之后,就意味着已经从内核申请到了一块空间。回到 mheap.grow的代码,会看到调用了 sysMap 再次向内核申请内存,sysMap 代码如下:
1 | func sysMap(v unsafe.Pointer, n uintptr, sysStat *sysMemStat) { |
可见,也是一个mmap系统调用,但传入的 flag 不同,多了一个 _MAP_FIXED 。
查看 mmap 的手册便会明白,在不提供_MAP_FIXED 的情况下,内核会尽量从给出的地址分配空间,但避免冲突是第一位的,所以结果并不总能如意。而_MAP_FIXED保证了这一点,即使在请求的地址处已有其它映射的情况下也会覆盖之前的映射。
mmap 文档中也对 _MAP_FIXED 使用提出了警示,而 go 在这里使用是完全没有问题的,因为事先已经向内核申请了该块内存了,在里面隔上一刀根本不需要睁眼。
我们拿到了一块连续的内存,是时候从 allocSpan 返回了,如此 stackalloc 就为新 G 申请到了一块连续内存用作堆栈。
从 goroutine 的新建一直到内核的大门,我们发现了用于申请内存的方式是 mmap,但mmap从进程虚拟地址空间的哪个位置分配内存呢?runtime 源码中给与的提示地址又是从何而来呢?
3. mmap 申请内存的位置
mmap 既是一个系统调用,也是进程虚拟地址空间中的一个区域,让我再次援引《深入 Linux 内核架构》中的一幅图:
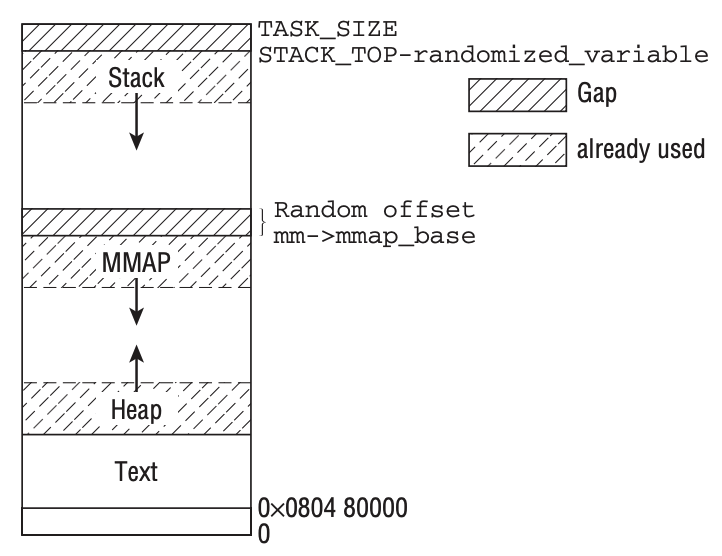
书中介绍了 2.6 版本的内核内存布局,其中 mmap 区域是和 heap 相对增长的,内核会留出足够的空间给主线程 stack,这样便可最大化的利用内存空间,好在 stack 通常不会很大。
但是 mmap 并非只能在概念上划出的区域进行分配,它甚至可以在用户空间内任意地方分配内存,这当然也包括传统的 heap 区域!还记得 _MAP_FIXED 吧?我打赌它绝对能让你的程序 crash 掉!
heap 是用来为进程动态分配内存的,传统的定义是:堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段的末尾,随着内存的分配和释放而增减:
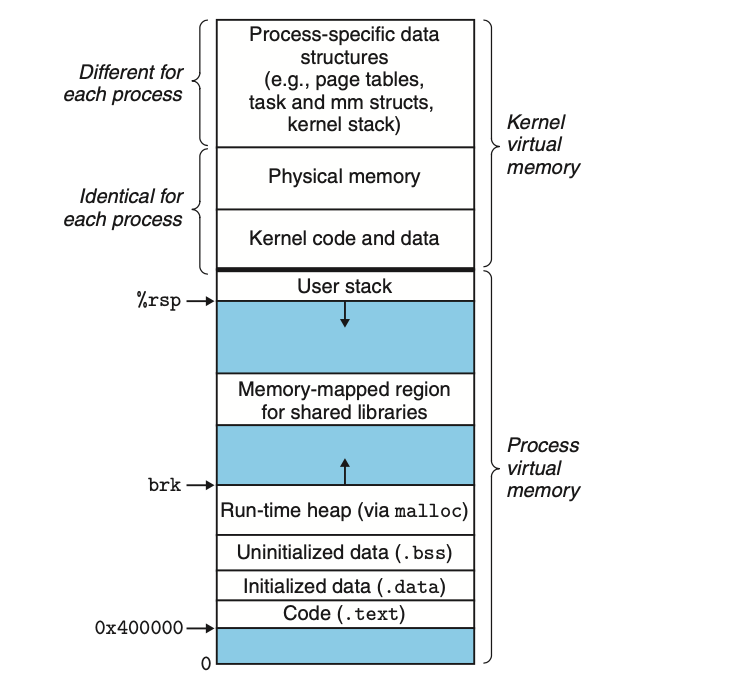
改变 heap 大小的系统调用是 brk 和 sbrk ,而 go 主要使用 mmap 来维护堆,这就说明 go 堆和传统的堆位置是不同的。位置虽然不同,但使命毫无二致,让我们来看一个 go 程序的内存布局:
00400000-004bd000 r-xp 00000000 103:02 8916313 playground/helloworld/hello/hello
004bd000-00574000 r--p 000bd000 103:02 8916313 playground/helloworld/hello/hello
00574000-0058f000 rw-p 00174000 103:02 8916313 playground/helloworld/hello/hello
0058f000-005c4000 rw-p 00000000 00:00 0
c000000000-c000200000 rw-p 00000000 00:00 0
c000200000-c017e00000 rw-p 00000000 00:00 0
c017e00000-c018000000 rw-p 00000000 00:00 0
c018000000-c018400000 rw-p 00000000 00:00 0
c018400000-c01c000000 ---p 00000000 00:00 0
7fef44906000-7fef449ba000 rw-p 00000000 00:00 0
7fef449d2000-7fef47c19000 rw-p 00000000 00:00 0
7fef47c19000-7fef57d99000 ---p 00000000 00:00 0
7fef57d99000-7fef57d9a000 rw-p 00000000 00:00 0
7fef57d9a000-7fef69c49000 ---p 00000000 00:00 0
7fef69c49000-7fef69c4a000 rw-p 00000000 00:00 0
7fef69c4a000-7fef6c01f000 ---p 00000000 00:00 0
7fef6c01f000-7fef6c020000 rw-p 00000000 00:00 0
7fef6c020000-7fef6c499000 ---p 00000000 00:00 0
7fef6c499000-7fef6c49a000 rw-p 00000000 00:00 0
7fef6c49a000-7fef6c519000 ---p 00000000 00:00 0
7fef6c519000-7fef6c579000 rw-p 00000000 00:00 0
7ffc335d5000-7ffc335f7000 rw-p 00000000 00:00 0 [stack]
7ffc335f8000-7ffc335fc000 r--p 00000000 00:00 0 [vvar]
7ffc335fc000-7ffc335fe000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
表3-1 Go 进程的内存布局映射
除了代码段不足 2M 的区域之外,似乎 c000000000 最值得怀疑,而且这份映射当中没有看到 heap 身影,这直接印证了上述猜想。关于 c000000000 我们要去源码中寻找答案,且看内存分配器的初始化:
1 | func mallocinit() { |
注释部分第一条便说:从地址空间的中间开始向上增长,很容易获得连续的区域,且不会和其它映射部位发生碰撞。
因此 go 选择了从 0x00c0开始,并且用一个 for 循环生成了 128 个提示地址,组成链表初始化到 mheap_.arenaHints:
1 | 0x7fc000000000 |
这 128 个起始地址除了最后一个之外,其余皆可向上增长 1TiB 的空间,最后一个距离用户空间顶部仅剩 256 GiB。
0x00c000000000 距离用户空间的开始有 765 GiB,这也是为什么不会和其它映射部位发生碰撞的原因!
mallocinit 初始化了mheap_.arenaHints,还记得 mheap 为增加 heap 而申请内存时的方法吗?
1 | // Try to grow the heap at a hint address. |
mmap 的调用都是围绕着 arenaHints 来进行的,并且每次申请成功后都会更新 hint 的 addr,这样就实现了连续增长,直到失败。如果失败了,就从下一个 1TiB 的区间再次开始!
4. g0 堆栈
看过了普通 goroutine 堆栈的分配之后,再来简要说一下 g0 的堆栈。g0 是个比较特殊的 goroutine 它只是协助 runtime 来执行,但不承载任何执行函数,与普通的用户 goroutine 有所区别。在一定程度上,可以把它类比成操作系统上每个线程的内核栈,每当 runtime 获得控制权的时候就会将堆栈切换到 g0 代表的堆栈上。
go 的 GPM 模型此处不作介绍,建议阅读Scheduling In Go : Part II - Go Scheduler 来了解并发模型。我们只说其中的 M,每个M 都有一个 g0 堆栈,用于执行 runtime 代码,其中较为特殊的 M0 (即 go 进程的主线程,每个 go 程序仅有一个 M0)的 g0 堆栈是通过汇编语言进行初始化的。
我们先来看看 go 程序的入口地址:
richard@Richard-Manjaro:~ » readelf -h carefree
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x463f20
Start of program headers: 64 (bytes into file)
Start of section headers: 456 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 7
Size of section headers: 64 (bytes)
Number of section headers: 23
Section header string table index: 3
读取 ELF文件头可知,入口地址为0x463f20,因为禁用了 cgo,没有动态链接库,所以 Entry point 指示的地址既是程序的入口地址。继续看一下该地址指示的代码:
richard@Richard-Manjaro:~ » lldb ./carefree
(lldb) target create "./carefree"
Current executable set to '/home/richard/carefree' (x86_64).
(lldb) image lookup --address 0x463f20
Address: carefree[0x0000000000463f20] (carefree.PT_LOAD[0]..text + 405280)
Summary: carefree`_rt0_amd64_linux
(lldb)
_rt0_amd64_linux 即为程序的入口,当运行程序时,shell 会 fork 一个子进程出来,之后执行 execve() 系统调用来装载 go 的可执行文件,当内核装载完毕之后,会将 CPU 的程序计数器设置为此入口点,之后 go 程序开始执行。
_rt0_amd64_linux 是对 asm_amd64.s 中 runtime·rt0_go 的调用,看一下runtime·rt0_go 的内容:
1 | TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0 |
这段代码设置 g0 堆栈的方式是使用线程堆栈的栈顶指针减少 64KB + 104B 作为 g0 堆栈的低端,当前线程堆栈的栈顶为 g0 堆栈的高端。执行完成后,g0 的堆栈便被初始化为 64KB 了。令人惊讶的是,这居然是在系统线程的 8M 堆栈(Linux 的默认线程堆栈为 8 M)中分配的。
再来看一下其它新建 M 的 g0,go 通过 runtime.newm 来新建操作系统线程,顺藤摸瓜会发现其最终执行的系统调用为 clone:
1 | func newosproc(mp *m) { |
clone 中堆栈起始地址传入的是 mp.g0.stack.hi,即该 M 的 g0 的堆栈高端地址,看一下 g0 的初始化,相应的代码在 runtime.allocm 中:
1 | if iscgo || mStackIsSystemAllocated() { |
可见后续 g0 分配就是通过 malg 来进行的,该函数我们之前已经介绍过了,此处只要明白分配的堆栈大小为 8K 即可。由此可知,除了 m0 的 g0 在传统的主线程堆栈区域外,后续 M 的堆栈都是分配自 go 堆中,其可能的区域自不待言,我们已在上一节论述过了。
5. goroutine 的堆栈切换
当 goroutine 被 runtime 调度到 CPU 上时,不仅要将程序计数器设置为该 goroutine 的执行函数地址,而且要切换到该 goroutine 的堆栈上执行后续操作,我们这一节就来看看 goroutine 的堆栈是如何切换的。堆栈的切换和调度密切相关,但此处只讨论和堆栈有关的内容,不再深入调度相关的细节。
m0 在初始化好一系列条件之后,会调用 runtime·mstart 从而真正的让 M0 跑起来,后续新建 M 时向 clone 传入的运行函数也是 runtime·mstart,而 runtime·mstart 最终会进入调度函数 runtime.schedule, 而 schedule 的工作就是千方百计的寻找空闲的 G 将它送到 CPU 上运行。当最终找到这个 G 的时候,会调用一段用汇编代码写成的函数 runtime·gogo(buf *gobuf):
1 | // func gogo(buf *gobuf) |
runtime·gogo 会调用 gogo,传入的参数是 g 结构体中和调度相关的一个字段 gobuf:
1 | type gobuf struct { |
其中有程序计数器和堆栈栈顶指针等重要的值,这些值都是该 goroutine 被调度出 CPU 的时候保存进来的,是 goroutine 的执行现场。gogo 会将现场恢复,这包括程序计数器和栈顶,之后这个 goroutine 就又从上次中断的地方跑起来了。
6. 总结
本文以探求 goroutine 堆栈在进程虚拟地址空间中的位置为诉求,对源代码进行有目的的展开,并最终找到内存分配的内核接口 mmap。
mmap 的使用太过灵活,以至于非要刻板的对应到虚拟内存布局中的位置显得有些棘手,因为 go 堆 接管的是整个虚拟内存的用户空间,但我们仍然可以从其内存分配的设计思想中窥得一二。
go 堆的起始位置在用户空间的中段,确切的说是距离起始端 768 GiB 的地方开始,而从用户空间 128 TiB 的角度来看,这远远算不上中间,仅仅是相对于传统 heap 来说的。我想这也是 go 对于历史的一种尊重,好在 64 位模式下虚拟地址空间的跨度足够大,可以做出很灵活的设计。
go 堆把后续的空间划分成了 128 份,几乎每份都有 1TiB 的大小,然后默默地从地址 0x00c000000000 处向上增长,因为00 c0 既不是有效的 UTF8 编码,又有足够的辨识度。
参考文献
- 深入理解计算机系统
- 程序员的自我修养
- Linux/UNIX系统编程手册
- 深入 Linux 内核架构
- Linux 系统编程
- mmap
- 深入golang runtime的调度
- go-scheduler
- Go 语言原本
- 一文教你搞懂 Go 中栈操作
- 详解Go中内存分配源码实现
- Scheduling In Go : Part II - Go Scheduler