Option to add Kafka metadata like topic, message size to the event. This will add a field named kafka to the logstash event containing the following attributes: topic: The topic this message is associated with consumer_group: The consumer group used to read in this event partition: The partition this message is associated with offset: The offset from the partition this message is associated with key: A ByteBuffer containing the message key
The following metadata from Kafka broker are added under the [@metadata] field:
[@metadata][kafka][topic]: Original Kafka topic from where the message was consumed.
[@metadata][kafka][consumer_group]: Consumer group
[@metadata][kafka][partition]: Partition info for this message.
[@metadata][kafka][offset]: Original record offset for this message.
[@metadata][kafka][key]: Record key, if any.
[@metadata][kafka][timestamp]: Timestamp when this message was received by the Kafka broker.
Please note that @metadata fields are not part of any of your events at output time. If you need these information to be inserted into your original event, you’ll have to use the mutate filter to manually copy the required fields into your event.
}else if [@metadata][kafka][topic] == "clearing" {
mutate { add_field => {"[@metadata][index]" => "clearing-%{+YYYY.MM.dd}"} } }else{ mutate { add_field => {"[@metadata][index]" => "trademgt-%{+YYYY.MM.dd}"} } } # remove the field containing the decorations, unless you want them to land into ES mutate { remove_field => ["kafka"] } }
In Logstash 1.5 and later, there is a special field called @metadata. The contents of @metadata will not be part of any of your events at output time, which makes it great to use for conditionals, or extending and building event fields with field reference and sprintf formatting.
The following configuration file will yield events from STDIN. Whatever is typed will become the message field in the event. The mutate events in the filter block will add a few fields, some nested in the @metadata field.
1 2 3 4 5 6 7 8 9 10 11 12 13
input { stdin { } }
filter { mutate { add_field => { "show" => "This data will be in the output" } } mutate { add_field => { "[@metadata][test]" => "Hello" } } mutate { add_field => { "[@metadata][no_show]" => "This data will not be in the output" } } }
$ bin/logstash -f ../test.conf Pipeline main started asdf { "@timestamp" => 2016-06-30T02:42:51.496Z, "@version" => "1", "host" => "example.com", "show" => "This data will be in the output", "message" => "asdf" }
The "asdf" typed in became the message field contents, and the conditional successfully evaluated the contents of the test field nested within the @metadata field. But the output did not show a field called @metadata, or its contents.
The rubydebug codec allows you to reveal the contents of the @metadata field if you add a config flag, metadata => true:
Let’s see what the output looks like with this change:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
$ bin/logstash -f ../test.conf Pipeline main started asdf { "@timestamp" => 2016-06-30T02:46:48.565Z, "@metadata" => { "test" => "Hello", "no_show" => "This data will not be in the output" }, "@version" => "1", "host" => "example.com", "show" => "This data will be in the output", "message" => "asdf" }
Now you can see the @metadata field and its sub-fields.
Only the rubydebug codec allows you to show the contents of the @metadata field.
Make use of the @metadata field any time you need a temporary field but do not want it to be in the final output.
Perhaps one of the most common use cases for this new field is with the date filter and having a temporary timestamp.
This configuration file has been simplified, but uses the timestamp format common to Apache and Nginx web servers. In the past, you’d have to delete the timestamp field yourself, after using it to overwrite the @timestamp field. With the @metadata field, this is no longer necessary:
1 2 3 4 5 6 7 8 9 10
input { stdin { } }
filter { grok { match => [ "message", "%{HTTPDATE:[@metadata][timestamp]}" ] } date { match => [ "[@metadata][timestamp]", "dd/MMM/yyyy:HH:mm:ss Z" ] } }
output { stdout { codec => rubydebug } }
Notice that this configuration puts the extracted date into the [@metadata][timestamp] field in the grok filter. Let’s feed this configuration a sample date string and see what comes out:
That’s it! No extra fields in the output, and a cleaner config file because you do not have to delete a "timestamp" field after conversion in the date filter.
Another use case is the CouchDB Changes input plugin (See https://github.com/logstash-plugins/logstash-input-couchdb_changes). This plugin automatically captures CouchDB document field metadata into the @metadata field within the input plugin itself. When the events pass through to be indexed by Elasticsearch, the Elasticsearch output plugin allows you to specify the action(delete, update, insert, etc.) and the document_id, like this:
RMAN backup in Oracle 11gR2 RAC is exactly same like RMAN backup in Oracle 11gR2 single node. The only difference is: Typically, in case of Oracle single node database, we will schedule RMAN scripts with the help of CRON job and it will run according to our convenience, but in case of Oracle RAC if we schedule RMAN script and if unfortunately that RAC node goes down ( where we configured RMAN scripts ), then RMAN backup won’t run obviously.
So, Same strategy will not be work in Oracle RAC node. For RMAN consistent backups use dbms_scheduler & we need to place RMAN scripts in shared directory. ( Or in my case, I have created identical scripts on both cluster node’s )
################################################################ # rman_backup_rac.sh FOR RAC # # created by lp # # 2017/03/22 # # usage: rman_backup_rac.sh <$BACKUP_LEVEL> # # BACKUP_LEVEL: # # F: full backup # # 0: level 0 # # 1: level 1 # ################################################################ #!/bin/bash # User specific environment and startup programs export ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 export RMAN_BAK_LOG_BASE=/home/oracle/DbBackup export RMAN_BAK_DATA_BASE=+data/NXRAC/backup export ORACLE_SID=`ps -ef|grep pmon|grep -v ASM|grep -v grep|awk -F'_' '{print $NF}'` export TIMESTAMP=`date +%Y%m%d%H%M`; #the destination of rman backuppiece export RMAN_DATA=${RMAN_BAK_DATA_BASE}/rman #the destination of rman backup logs export RMAN_LOG=${RMAN_BAK_LOG_BASE}/logs
if [[ ! -z $1 ]] && echo $1 |grep -Ew "[01F]" >/dev/null 2>&1 then export RMAN_LEVEL=${1}
# Check rman level if [ "$RMAN_LEVEL" == "F" ]; then unset INCR_LVL BACKUP_TYPE=full else INCR_LVL="INCREMENTAL LEVEL ${RMAN_LEVEL}" BACKUP_TYPE=lev${RMAN_LEVEL} fi else echo "${1} wrong argument!" >${RMAN_LOG}/wrong_argument_${TIMESTAMP}.log exit 1 fi
#the prefix of rman backuppiece export RMAN_FILE=${RMAN_DATA}/${BACKUP_TYPE}_${TIMESTAMP} #the logfile of shell script including the rman logs contents export SSH_LOG=${RMAN_LOG}/${BACKUP_TYPE}_${TIMESTAMP}.log #the size of backuppiece export MAXPIECESIZE=4G #################################################################### # # # the name of rman logs excluding the file expanded-name, # # when the shell is complete,the content of this file will be # # appended to the $SSH_LOG and the rman logfile will be deleted. # # # #################################################################### export RMAN_LOG_FILE=${RMAN_LOG}/${BACKUP_TYPE}_${TIMESTAMP}_1 #Check RMAN Backup Path
if ! test -d ${RMAN_LOG} then mkdir -p ${RMAN_LOG} fi
echo "---------------------------------" >>${SSH_LOG} echo " " >>${SSH_LOG} echo "Rman Begin to Working ........." >>${SSH_LOG} echo "Begin time at:" `date` --`date +%Y%m%d%H%M` >>${SSH_LOG} #Startup rman to backup $ORACLE_HOME/bin/rman log=${RMAN_LOG_FILE}.log <<EOF connect target / run { CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS; CONFIGURE BACKUP OPTIMIZATION ON; CONFIGURE CONTROLFILE AUTOBACKUP ON; CONFIGURE DEVICE TYPE DISK PARALLELISM 4 BACKUP TYPE TO BACKUPSET; CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '${RMAN_DATA}/control_auto_%F'; ALLOCATE CHANNEL 'ch1' TYPE DISK maxpiecesize=${MAXPIECESIZE} CONNECT 'SYS/passwd@node1'; ALLOCATE CHANNEL 'ch2' TYPE DISK maxpiecesize=${MAXPIECESIZE} CONNECT 'SYS/passwd@node1'; ALLOCATE CHANNEL 'ch3' TYPE DISK maxpiecesize=${MAXPIECESIZE} CONNECT 'SYS/passwd@mode2'; ALLOCATE CHANNEL 'ch4' TYPE DISK maxpiecesize=${MAXPIECESIZE} CONNECT 'SYS/passwd@node2'; CROSSCHECK ARCHIVELOG ALL; DELETE NOPROMPT OBSOLETE; DELETE NOPROMPT EXPIRED BACKUP; BACKUP AS COMPRESSED BACKUPSET ${INCR_LVL} DATABASE FORMAT '${RMAN_FILE}_db_%U' TAG '${BACKUP_TYPE}_${TIMESTAMP}'; SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT'; BACKUP FILESPERSET 20 ARCHIVELOG ALL FORMAT '${RMAN_FILE}_arc_%U' TAG '${ORACLE_SID}_arc_${TIMESTAMP}' DELETE INPUT; RELEASE CHANNEL ch1; RELEASE CHANNEL ch2; RELEASE CHANNEL ch3; RELEASE CHANNEL ch4; ALLOCATE CHANNEL ch00 TYPE DISK; BACKUP FORMAT '${RMAN_DATA}/cntrl_%U' CURRENT CONTROLFILE; RELEASE CHANNEL ch00; } exit; EOF
SQL>selectvaluefrom dba_scheduler_global_attribute where attribute_name ='DEFAULT_TIMEZONE';
VALUE -------------------------------------------------------------------------------- Asia/Shanghai
Now we need to create credential so that are assigned to DBMS_SCHEDULER jobs so that they can authenticate with a local/remote host operating system or a remote Oracle database.
Now its time to create DBMS_SCHEDULER job for RMAN incremental level 0 backup, Here in this procedure I am going to create RMAN_INC0_BACKUP job with required attributes.
Set argument_position & argument_value ( i.e. Path of the RMAN script ) for the same job:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
begin dbms_scheduler.set_job_argument_value( job_name =>'RMAN_INC0_BACKUP', argument_position =>1, argument_value =>'/home/oracle/rman.sh'); end; /
begin dbms_scheduler.set_job_argument_value( job_name =>'RMAN_INC0_BACKUP', argument_position =>2, argument_value =>0); end; /
Set start_date for the same job, In my case RMAN_INC0_BACKUP job will execute every week on sunday @03am, so job start date and its first run timing would according to my convenience.
1 2 3 4 5 6 7
begin dbms_scheduler.set_attribute( name =>'RMAN_INC0_BACKUP', attribute =>'start_date', value=> trunc(sysdate)+3/24); end; /
Test your backup job manually in SQL prompt by instantiating RMAN_INC0_BACKUP job.
In case of any error while test run, you can make sure details of error by issuing the following query, OR You can also query to dba_scheduler_job_run_details dictionary view for more details.
1
select JOB_NAME,STATUS,STATE,ERROR#,CREDENTIAL_NAME from dba_scheduler_job_run_details where CREDENTIAL_NAME like'RMAN%';
After successfully completion of test run, Enable & schedule it by following procedure by setting value to repeat_interval parameter, In my case RMAN_INC0_BACKUP job will execute every week on Sunday @03pm.
1 2 3 4 5 6 7 8
begin dbms_scheduler.set_attribute( name =>'RMAN_INC0_BACKUP', attribute =>'repeat_interval', value=>'freq=daily;byday=sun;byhour=03'); dbms_scheduler.enable( 'RMAN_INC0_BACKUP' ); end; /
Ensure dbms_scheduler job details by issuing the following query OR you can also query to dba_scheduler_jobs and dba_scheduler_job_args.
1
SQL>select job_name,enabled,owner, state from dba_scheduler_jobs where job_name in ('RMAN_INC0_BACKUP');
Keep your eye on behavior of dbms_scheduler job by issuing the following query:
1 2
SQL>select job_name,RUN_COUNT,LAST_START_DATE,NEXT_RUN_DATE from dba_scheduler_jobs where job_name in ('RMAN_INC0_BACKUP'); SQL>select*from dba_scheduler_job_args where job_name like'RMAN%';
In accordance with the above method to create a level 1 backup job RMAN_INC1_BACKUP,The only difference is the repeat_interval:
1 2 3 4 5 6 7 8
begin dbms_scheduler.set_attribute( name =>'RMAN_INC1_BACKUP', attribute =>'repeat_interval', value=>'freq=daily;byday=mon,tue,wed,thu,fri,sat;byhour=03'); dbms_scheduler.enable( 'RMAN_INC1_BACKUP' ); end; /
Important Note: DBMS_SCHEDULER is smart enough to start backup on the node where the last backup was successfully executed.
Oracle 11g: sql plan manangement 、adaptive cursor sharing
Oracle 12c: sql plan manangement 、adaptive cursor sharing、Adaptive Execution Plans
SQL Plan Management
SPM组成
SQL Plan Management(以下简称SPM)是一种优化器自动管理执行计划的预防机制,它确保数据库仅使用已知的、经过验证的执行计划。在Oracle 11g之前,执行计划一直是作为“运行时”生成的对象存在。虽然oracle提供了一些方法去指导它的生成,但Oracle一直没有试图去保存完整的执行计划。 从11g开始,执行计划就可以作为一类资源被保存下来,允许特定SQL语句只能选择“已知”的执行计划。
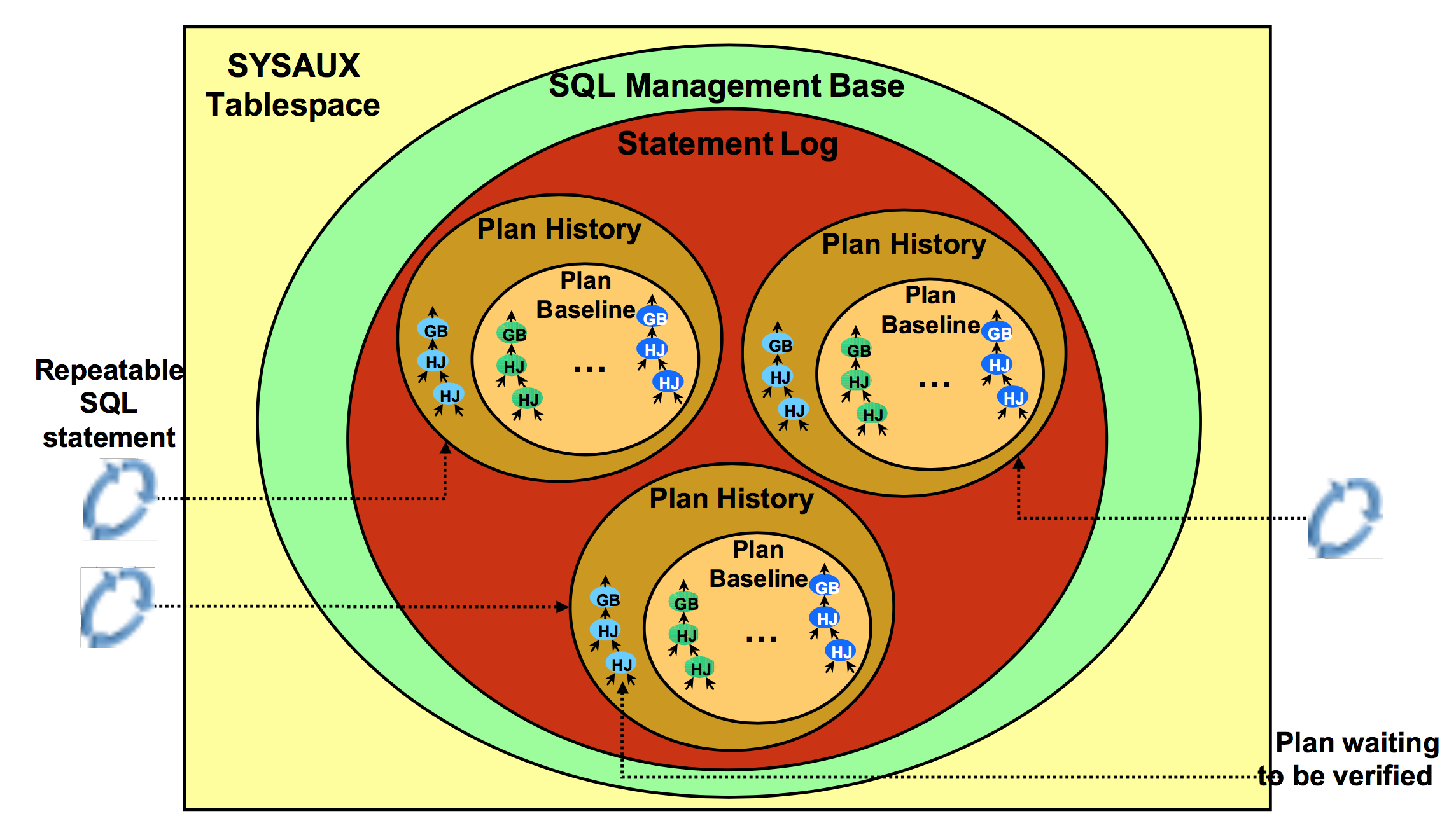
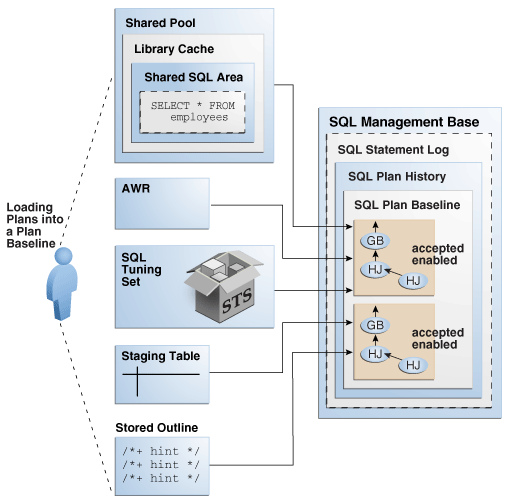
SMB是数据字典的一部分,位于SYSAUX表空间,其中存储着statement logs, plan histories, SQL plan baselines, and SQL profiles等内容。
Plan History是优化器生成的所有执行计划的总称;SQL Plan Baseline是Plan History里那些被标记为“ACCEPTED”的执行计划的总称,称为SQL执行计划基线;SQL Statement Log是一系列的查询签名(signatures),用于在自动捕获执行计划时辨别重复执行的sql;关系如下图所示:
Plan capture(执行计划的捕获)
Automatic Initial Plan Capture(自动捕获)
开启自动捕获只需在初始化参数中将OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES设置为TRUE(默认为FALSE),开启之后数据库就会为每个重复执行的sql创建SQL Plan Baseline,甄别是否是重复执行的SQL就是利用的上文提到的SQL Statement Log,基线包括供优化器重新生成该执行计划的所有信息,例如SQL text, outline, bind variable values, and compilation environment,这个初始的执行计划会被自动标记为“accepted”,如果之后又有新的执行计划生成,那么该执行计划会被加入到Plan History但是会被标记为“unaccepted”。
具体的load过程,本文暂不做讨论,详情请参阅官方文档 Managing SQL Plan Baselines,这里需要说明的一点是从AWR导入执行计划是oracle 12.2才开始加入的,12.2以前要想实现从AWR中导入执行计划,需要先创建SQL Tuning set,并从AWR中将plan load进STS,再使用DBMS_SPM.LOAD_PLANS_FROM_SQLSET将计划加载到SPM中。
下面再谈一下,对于已存在SQL Plan Baseline的SQL,其后续的新的执行计划的捕获情况;
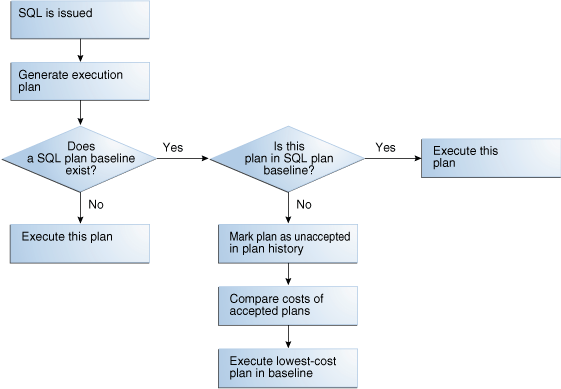
不论使用哪种方式创建了SQL Plan Baseline,后续新的plan都会被加入到Plan History并被标记为”unaccepted“,此行为不依赖于OPTIMIZER_CAPTURE_SQL_PLAN_ BASELINES的设置,新加入的plan不会被使用,直到其经过验证比已accepted的plan性能更好,并演化为accepted加入SQL Plan Baseline。
当数据库为一条sql执行硬解析的时候,优化器会生成一个best-cost plan,如果初始化参数OPTIMIZER_USE_SQL_PLAN_BASELINES被设置成为TRUE(默认为TRUE),那么在执行best-cost plan之前会先检查是否存在对应的SQL Plan Baseline,匹配的时候使用SQL语句的signature,signature是一个由SQL文本规范化后的SQL标识符(case insensitivity and with whitespaces removed)(由此可见只要一条sql生成了baseline之后,那么无论大小写改变、空格多少都会被认为是一条sql),这个比较是内存操作,因此开销很小。
* 注意,当sql plan baseline中有Fixed的时候,新生成的执行计划是不会被加入到plan history中的。
Plan Evolution(执行计划演化)
当优化器生成一个新的执行计划后,将其加入到plan history中作为一个unaccepted的plan,它需要被verified之后才可以使用,Verification是一个比较unaccepted和accepted(所有accepted中最小cost的)plan的执行性能的过程,verify的过程是实际执行该plan的过程,通过与accepted的plan比较elapse time, CPU time and buffer gets等性能统计信息来判断新plan的性能,如果新的plan的性能优于原plan或者相差无几,那么该plan会被标记为accepted加入SQL Plan Baseline,否则它仍然是一个unaccepted的plan,但是LAST_VERIFIED属性会被更新为当前时刻,12c之后的Automatic plan evolution过程还会考虑自上次被verify之后超过30天的plan,oracle认为如果系统有所改变,也许之前的plan会有更好的性能,当然这个功能可以通过dbms_spm.alter_sql_plan_baseline来禁止。
12c之前没有自动Evolve的机制,从12.1开始automatic plan evolution由SPM Evolve Advisor来完成,11g时代的DBMS_SPM.EVOLVE_SQL_PLAN_BASELINE被废弃,下面将分别针对11g和12c来介绍Plan Evolution的过程:
COL PARAMETER_NAME FORMAT a25 COL VALUE FORMAT a42 SELECT PARAMETER_NAME, PARAMETER_VALUE AS "VALUE" FROM DBA_ADVISOR_PARAMETERS WHERE ( (TASK_NAME ='SYS_AUTO_SPM_EVOLVE_TASK') AND ( (PARAMETER_NAME ='ACCEPT_PLANS') OR (PARAMETER_NAME LIKE'%ALT%') OR (PARAMETER_NAME ='TIME_LIMIT') ) );
SQL> SET LONG 1000000 PAGESIZE 1000 LONGCHUNKSIZE 100 LINESIZE 100 SQL> SELECT DBMS_SPM.report_auto_evolve_task FROM dual;
REPORT_AUTO_EVOLVE_TASK ---------------------------------------------------------------------------------------------------- GENERAL INFORMATION SECTION ---------------------------------------------------------------------------------------------
Task Information: --------------------------------------------- Task Name : SYS_AUTO_SPM_EVOLVE_TASK Task Owner : SYS Description : Automatic SPM Evolve Task Execution Name : EXEC_1173 Execution Type : SPM EVOLVE Scope : COMPREHENSIVE Status : COMPLETED Started : 04/20/2017 22:00:05 Finished : 04/20/2017 22:00:09 Last Updated : 04/20/2017 22:00:09 Global Time Limit : 3600 Per-Plan Time Limit : UNUSED Number of Errors : 0 ---------------------------------------------------------------------------------------------
SUMMARY SECTION --------------------------------------------------------------------------------------------- Number of plans processed : 0 Number of findings : 0 Number of recommendations : 0 Number of errors : 0 ---------------------------------------------------------------------------------------------
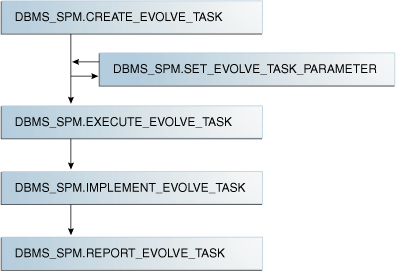
Manually Evolve Task
手动演化的过程大致如下图:
Create an evolve task
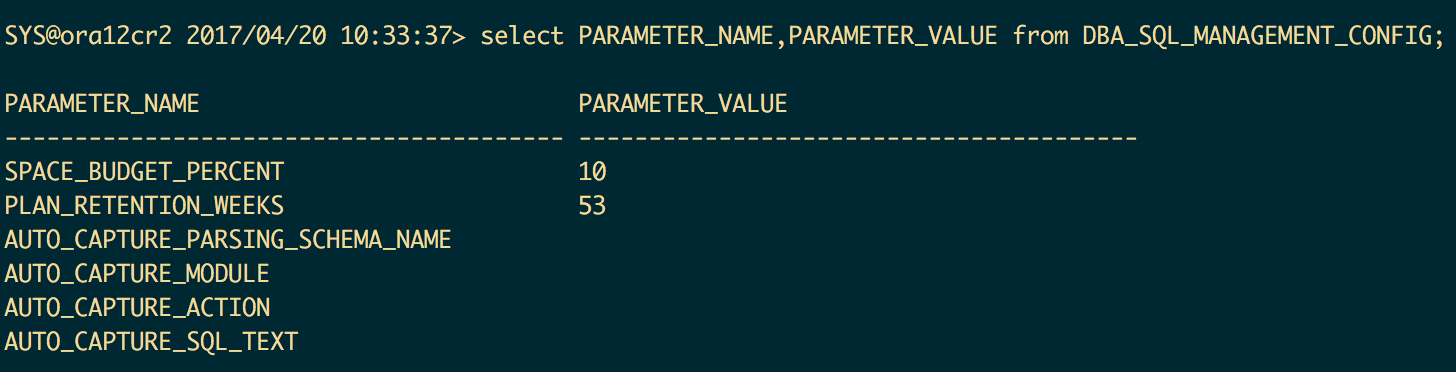
Optionally, set evolve task parameters(在12.2.0.1中仅TIME_LIMIT有效)
SELECT PARAMETER_NAME, PARAMETER_VALUE AS "%_LIMIT", ( SELECTsum(bytes/1024/1024) FROM DBA_DATA_FILES WHERE TABLESPACE_NAME ='SYSAUX' ) AS SYSAUX_SIZE_IN_MB, PARAMETER_VALUE/100* ( SELECTsum(bytes/1024/1024) FROM DBA_DATA_FILES WHERE TABLESPACE_NAME ='SYSAUX' ) AS "CURRENT_LIMIT_IN_MB" FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME ='SPACE_BUDGET_PERCENT';
SELECT PARAMETER_NAME, PARAMETER_VALUE AS "%_LIMIT", ( SELECTsum(bytes/1024/1024) FROM DBA_DATA_FILES WHERE TABLESPACE_NAME ='SYSAUX' ) AS SYSAUX_SIZE_IN_MB, PARAMETER_VALUE/100* ( SELECTsum(bytes/1024/1024) FROM DBA_DATA_FILES WHERE TABLESPACE_NAME ='SYSAUX' ) AS "CURRENT_LIMIT_IN_MB" FROM DBA_SQL_MANAGEMENT_CONFIG WHERE PARAMETER_NAME ='SPACE_BUDGET_PERCENT';
1962643652257108320 SQL_1b3cb600d175d160 select/*liu*/*from test wh SQL_PLAN_1qg5q038rbnb025a3834b SCOTT 13-APR-1702.23.12.000000 PM YES YES YES 0 ere id=1
1962643652257108320 SQL_1b3cb600d175d160 select/*liu*/*from test wh SQL_PLAN_1qg5q038rbnb097bbe3d0 HR 13-APR-1702.35.09.000000 PM YES YES YES 0 ere id=1
DBMS_XPLAN.DISPLAY_SQL_PLAN_BASELINE ( sql_handle IN VARCHAR2 :=NULL, plan_name IN VARCHAR2 :=NULL, format IN VARCHAR2 :='TYPICAL') RETURN dbms_xplan_type_table;
也可以通过V$SQL视图查看一条SQL是否使用SQL Base Line,如果使用了baseline,那么它的sql_plan_baseline列将会显示plan_name,因此可以连接DBA_SQL_PLAN_BASELINES和V$SQL视图:
1 2 3 4
select s.SQL_ID, s.SQL_TEXT, b.plan_name, b.origin, b.accepted from dba_sql_plan_baselines b, v$sql s where s.EXACT_MATCHING_SIGNATURE = b.signature and s.SQL_PLAN_BASELINE = b.plan_name;
查看v$sql中的sql是否有baseline:
1 2 3 4 5 6
SELECT sql_handle, plan_name FROM dba_sql_plan_baselines WHERE signature IN ( SELECT exact_matching_signature FROM v$sqlWHERE sql_id='1s6a8wn4p6rym' );
DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE ( sql_id IN VARCHAR2, plan_hash_value IN NUMBER :=NULL, sql_handle IN VARCHAR2, --注意这里 fixed IN VARCHAR2 :='NO', enabled IN VARCHAR2 :='YES') RETURN PLS_INTEGER;
Oracle对其中sql_handle的解释为:
SQL handle to use in identifying the SQL plan baseline into which the plans are loaded. The sql_handle must denote an existing SQL plan baseline. The use of handle is crucial when the user tunes a SQL statement by adding hints to its text and then wants to load the resulting plan(s) into the SQL plan baseline of the original SQL statement.
意思是说,使用sql_handle可以将cursor cache中的执行计划load进一个已存在的SQL Plan Baseline,这就意味着你可以不需要更改应用的代码,就可以让SQL跑出你期望的执行计划,前提是你有一个已经tuning好的plan在cacahe里,你就可以将这个plan load进原SQL的Baseline,下面将针对此调优方法展开详细论述:
SELECT description FROM spm_test_tab WHERE id =1113; SELECT*FROMTABLE (SELECT DBMS_XPLAN.DISPLAY_CURSOR(null,null,'advanced') from dual); SQL_ID gsttbra9z0ddw, child number 0 ------------------------------------- SELECT description FROM spm_test_tab WHERE id =1113
Plan hash value: 3121206333
------------------------------------------------------------------------------------------------ | Id | Operation | Name |Rows| Bytes | Cost (%CPU)|Time| ------------------------------------------------------------------------------------------------ |0|SELECT STATEMENT ||||2 (100)|| |1|TABLE ACCESS BY INDEX ROWID| SPM_TEST_TAB |1|25|2 (0)|00:00:01| |*2| INDEX RANGE SCAN | SPM_TEST_TAB_IDX |1||1 (0)|00:00:01| ------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id): -------------------------------------------------------------
SYS@DB412017/04/2614:57:55>SELECT SQL_ID,SQL_FULLTEXT FROM V$SQLWHERE SQL_FULLTEXT LIKE'%1113%';
SQL_ID SQL_FULLTEXT ------------- -------------------------------------------------------------------------------- gsttbra9z0ddw SELECT description FROM spm_test_tab WHERE id =1113
declare v_sql_plan_id pls_integer; begin v_sql_plan_id := dbms_spm.load_plans_from_cursor_cache(sql_id =>'gsttbra9z0ddw'); end; /
SELECT SQL_HANDLE,PLAN_NAME,ENABLED,ACCEPTED FROM dba_sql_plan_baselines WHERE signature IN ( SELECT exact_matching_signature FROM v$sqlWHERE sql_id='gsttbra9z0ddw' );
SELECT description FROM spm_test_tab WHERE id =99;
SELECT*FROMTABLE (SELECT DBMS_XPLAN.DISPLAY_CURSOR(null,null,'advanced') from dual);
PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID gat6z1bc6nc2d, child number 0 ------------------------------------- SELECT description FROM spm_test_tab WHERE id =99
select * fromtable( dbms_xplan.display_sql_plan_baseline( sql_handle=>'SQL_7b76323ad90440b9', plan_name=>'SQL_PLAN_7qxjk7bch8h5t3652c362', format=>'basic +NOTE')); -------------------------------------------------------------------------------- SQL handle: SQL_7b76323ad90440b9 SQL text: SELECT description FROM spm_test_tab WHERE id =99 --------------------------------------------------------------------------------
-------------------------------------------------------------------------------- Plan name: SQL_PLAN_7qxjk7bch8h5t3652c362 Plan id: 911393634 Enabled: YES Fixed: NO Accepted: NO Origin: AUTO-CAPTURE Plan rows: From dictionary --------------------------------------------------------------------------------
Plan hash value: 2338891031
---------------------------------------------------------------- | Id | Operation | Name | ---------------------------------------------------------------- |0|SELECT STATEMENT || |1|TABLE ACCESS BY INDEX ROWID BATCHED| SPM_TEST_TAB | |2| INDEX RANGE SCAN | SPM_TEST_TAB_IDX | ----------------------------------------------------------------
SET LONG 1000000 PAGESIZE 1000 LONGCHUNKSIZE 100 LINESIZE 100 SELECT DBMS_SPM.report_evolve_task(task_name =>'TASK_1169', execution_name =>'EXEC_1281') AS output FROM dual;
OUTPUT ---------------------------------------------------------------------------------------------------- GENERAL INFORMATION SECTION ---------------------------------------------------------------------------------------------
Task Information: --------------------------------------------- Task Name : TASK_1169 Task Owner : SYS Execution Name : EXEC_1281 Execution Type : SPM EVOLVE Scope : COMPREHENSIVE Status : COMPLETED Started : 04/24/201715:04:17 Finished : 04/24/201715:04:25 Last Updated : 04/24/201715:04:25 GlobalTime Limit : 2147483646 Per-Plan Time Limit : UNUSED Number of Errors : 0 ---------------------------------------------------------------------------------------------
SUMMARY SECTION --------------------------------------------------------------------------------------------- Number of plans processed : 1 Number of findings : 1 Number of recommendations : 1 Number of errors : 0 ---------------------------------------------------------------------------------------------
DETAILS SECTION --------------------------------------------------------------------------------------------- Object ID : 2 Test Plan Name : SQL_PLAN_7qxjk7bch8h5t3652c362 Base Plan Name : SQL_PLAN_7qxjk7bch8h5tb65c37c8 SQL Handle : SQL_7b76323ad90440b9 Parsing Schema : SYS Test Plan Creator : SYS SQL Text : SELECT description FROM spm_test_tab WHERE id =99
Execution Statistics: ----------------------------- Base Plan Test Plan ---------------------------- ---------------------------- Elapsed Time (s): .000037.000005 CPU Time (s): .0000440 Buffer Gets: 50 Optimizer Cost: 132 Disk Reads: 00 Direct Writes: 00 Rows Processed: 00 Executions: 1010
Findings (1): ----------------------------- 1. The plan was verified in0.03200 seconds. It passed the benefit criterion because its verified performance was 18.01480 times better than that of the baseline plan.
If you are concerned about the length of time it could take to drop column data from all of the rows in a large table, you can use the ALTER TABLE...SET UNUSED statement. This statement marks one or more columns as unused, but does not actually remove the target column data or restore the disk space occupied by these columns. However, a column that is marked as unused is not displayed in queries or data dictionary views, and its name is removed so that a new column can reuse that name. All constraints, indexes, and statistics defined on the column are also removed.
To mark the hiredate and mgr columns as unused, execute the following statement:
1
ALTERTABLE hr.admin_emp SET UNUSED (hiredate, mgr);
You can later remove columns that are marked as unused by issuing an ALTER TABLE...DROP UNUSED COLUMNS statement. Unused columns are also removed from the target table whenever an explicit drop of any particular column or columns of the table is issued.
The data dictionary views USER_UNUSED_COL_TABS, ALL_UNUSED_COL_TABS, or DBA_UNUSED_COL_TABS can be used to list all tables containing unused columns. The COUNT field shows the number of unused columns in the table.
For external tables, the SET UNUSED statement is transparently converted into an ALTER TABLE DROP COLUMN statement. Because external tables consist of metadata only in the database, the DROP COLUMN statement performs equivalently to the SET UNUSED statement. ##2. Removing Unused Columns
The ALTER TABLE...DROP UNUSED COLUMNS statement is the only action allowed on unused columns. It physically removes unused columns from the table and reclaims disk space.
In the ALTER TABLE statement that follows, the optional clause CHECKPOINT is specified. This clause causes a checkpoint to be applied after processing the specified number of rows, in this case 250. Checkpointing cuts down on the amount of undo logs accumulated during the drop column operation to avoid a potential exhaustion of undo space.
1
ALTERTABLE hr.admin_emp DROP UNUSED COLUMNS CHECKPOINT 250;
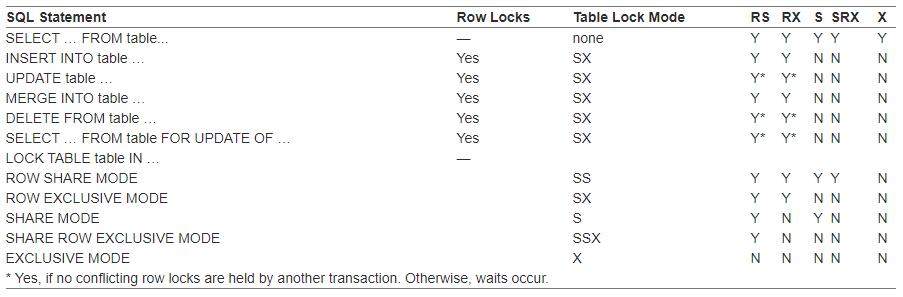
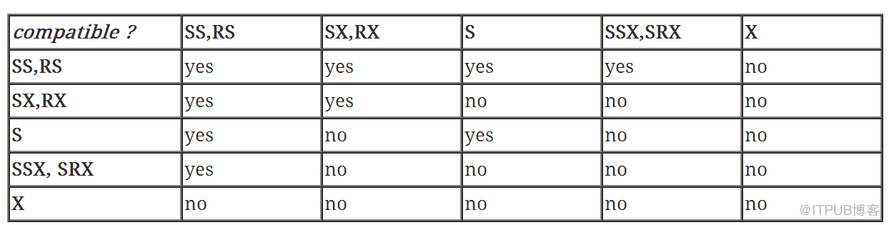
Value Name(s) Table method (TM lock) 0 No lock n/a
1 Null lock (NL) Used during some parallel DML operations (e.g. update) by the pX slaves while the QC is holding an exclusive lock.
2 Sub-share (SS) Until 9.2.0.5/6 "select for update" Row-share (RS) Since 9.2.0.1/2 used at opposite end of RI during DML Lock table in row share mode Lock table in share update mode
3 Sub-exclusive(SX) Update (also "select for update" from 9.2.0.5/6) Row-exclusive(RX) Lock table in row exclusive mode Since 11.1 used at opposite end of RI during DML
4 Share (S) Lock table in share mode Can appear during parallel DML with id2 = 1, in the PX slave sessions Common symptom of "foreign key locking" (missing index) problem
5 share sub exclusive (SSX) Lock table in share row exclusive mode share row exclusive (SRX) Less common symptom of "foreign key locking" but likely to be more frequent if the FK constraint is defined with "on delete cascade."
========= Dump for incident 14804 (ORA 600 [13011]) ========
*** 2016-07-20 18:21:04.186 dbkedDefDump(): Starting incident default dumps (flags=0x2, level=3, mask=0x0) ----- Current SQL Statement for this session (sql_id=c8taax4bfzsjc) ----- delete from WRH$_RSRC_PLAN tab where (:beg_snap <= tab.snap_id and tab.snap_id <= :end_snap and dbid = :dbid) and not exists (select 1 from WRM$_BASELINE b wh ere (tab.dbid = b.dbid) and (tab.snap_id >= b.start_snap_id) and (tab.snap_id <= b.end_snap_id))
MOS中关于ORA-600 [13013]描述
1 2 3 4 5 6 7
Format: ORA-600 [13013] [a] [b] {c} [d] [e] [f] Arg [a] Passcount Arg [b] Data Object number Arg {c} Tablespace Decimal Relative DBA (RDBA) of block containing the row to be updated Arg [d] Row Slot number Arg [e] Decimal RDBA of block being updated (Typically same as {c}) Arg [f] Code
确定object
1 2 3 4 5
SQL>select owner,object_name,object_type from dba_objects where object_id=6665;
1.The most common cause of this error is an index corruption. The first step is to check the indexes for corruption, i.e. run
1 2 3
SQL> ANALYZE INDEX WRH$_RSRC_PLAN_PK VALIDATE STRUCTURE;
Index analyzed.
2.If the indexes do not report corruption, further test for corruption the base tables referenced in the execution plan or the statement producing the error:
1 2 3 4 5
SQL> ANALYZE TABLE WRH$_RSRC_PLAN VALIDATE STRUCTURE CASCADE; ANALYZE TABLE WRH$_RSRC_PLAN VALIDATE STRUCTURE CASCADE * ERROR at line 1: ORA-01499: table/index cross reference failure - see trace file
"row not found in index" "Table/Index row count mismatch" "row mismatch in index dba" "Table row count/Bitmap index bit count mismatch" "kdavls: kdcchk returns %d when checking cluster dba 0x%08lx objn %d\n"
SELECT dbms_utility.data_block_address_file( to_number(trim(leading'0'from replace('&&rdba','0x','')),'XXXXXXXX') ) AS rfile#, dbms_utility.data_block_address_block( to_number(trim(leading'0'from replace('&&rdba','0x','')),'XXXXXXXX') ) AS block# FROM dual;
The Oracle10g dynamic performance tables constitute the foundation of sophisticated automations such as Automatic Memory Management (AMM ) as well as intelligent advisory tools such as ADDM and the SQL Tuning Advisor.
Remember, the AWR is a core feature of the 10g database kernel and automatically collects and stores important run-time performance information for our historical analysis.
The tables that store this information are prefixed with wrh$ and are very similar in function to the STATSPACK tables. This could make STATSPACK appear somewhat obsolete, although it is still available in the $ORACLE_HOME/rdbms/admin directory.
Unlike the more cumbersome STATSPACK utility, which requires knowledge of the table structure and creation of complex query scripts, the 10g Enterprise Manager (OEM) automatically displays and interprets this valuable time-series performance data.
The wrh$ AWR tables store important historical statistical information about the database in the form of periodic snapshots. Each snapshot is a capture of the in–memory x$ fixed view and other control structures at a certain point in time. Each of the AWR table names is prefixed with wrm$ (Metadata tables), wrh$ (History tables), or wri$ (Advisory tables).
1. The wrm$ tables store metadata information for the Workload Repository.
2. The wrh$ tables store historical data or snapshots.
3. The wri$ tables: These 49 tables store data related to advisory functions.