《三体》问题
友情提醒:本文主要介绍由《三体》引发的关于计算机的某些思考,其中略有剧透,介意的朋友慎入。
旅行者1号
很多年前,我刚刚升入高中,那时候我们学校每周只有周日下午放半天假,就在一个周日的下午,我整个人都泡在学校附近的新华书店,被一本人类探索太空的书迷住了。
从书中我第一次知道了旅行者1号,那个当时已经飞了25年的人类探测器,携带着地球文明的问候在太空中不知疲倦的飞行了25年,却仍没有飞出太阳系。
我并不是一个爱读书的人,至少当时是这样,我对宇宙的所有了解也大部分来源于那个下午,而我最基本的宇宙观也正是建立于那个下午,那一天我了解了柯伊伯带和奥尔特星云。在后来的人生中,我对旅行者1号也格外的亲切。
2012年8月25日,旅行者1号成为第一个穿越太阳圈并进入星际介质的宇宙飞船,它已经飞行了35年。
截至2019年8月28日止,旅行者1号正处于离太阳146.7 AU($2.19 \times 10^{10} km$)的位置,是离地球最远的人造物体,已经飞行了42年。
那个下午出了书店,很长一段时间我都精神恍惚,若有所失,茫茫百感不知从何说起,震撼于宇宙的浩瀚与人类的渺小。
最近,我花了一周的时间读完了刘慈欣的《三体》,又一次体验到了少年时代的那种怅然若失的感觉,这也是让我想起旅行者1号的缘由。
《三体》问题
在小说《三体》中,可以通过特定的方法改变一个恒星系的光速,比如将太阳系的光速降低到第三宇宙速度,也就是光速由30万km/s降为16.7km/s,书中将此时的星系称为“黒域”,形成黒域的星系光速永远被限制,科技也永远停滞,人类永远也无法脱离该星系,这让该星系看起来安全,从而可以逃避“黑暗森林”的打击。
在大刘的假设中,当光速降为原来的万分之一,这个时候原来的电子计算机根本就无法运行了,需要特殊制造的芯片才可以,那么就引出了一个具体的问题:光速降低对我们现在的电子计算机会产生哪些影响呢?
计算机的物理限制
纵观计算机的发展历史,我们总是朝着更快的处理速度,更短的响应时间,更高的性能这条追求极致的道路上发展,我们的CPU不断的追求更多的晶体管,更先进的制程,更低的功耗,更加高性能的架构设计;我们的软件也在不断的改良,架构不断的演进,从单体到分布式,从传统数据中心到云计算,从巨石应用到微服务;在这个过程中是否存在一个我们永远无法逾越的物理限制呢?就像机械硬盘无论怎么样优化都无法打破磁头旋转这一物理动作的桎梏一样。是的,这样的物理限制存在,那就是光速。
以3GHz的CPU为例,频率是周期的倒数:
$$f={1 \over t}$$
晶振每秒钟可以振荡30亿次,每次耗时大约为0.33纳秒。光在1纳秒的时间内,可以前进30厘米。也就是说,在CPU的一个时钟周期内,光可以前进10厘米。这意味着如果要在一个时钟周期内完成一次信号的往返,并且假设组件没有延迟并且信号真的可以以光速运行,那么这个组件就要距离CPU不能超过5厘米。
这又意味着什么?我们假设数据的传输过程中,没有门延迟,电信号以光速传播,这时所需处理的数据距离CPU越远,它的传输时延越大。你看,我们一直不断优化的也不断提高的性能,居然受到一个宇宙常数的制约。
光速降为第三宇宙速度
距离CPU越远,传输的时延越大,这个结论肯定会让你想到冯诺依曼计算机的存储金字塔:
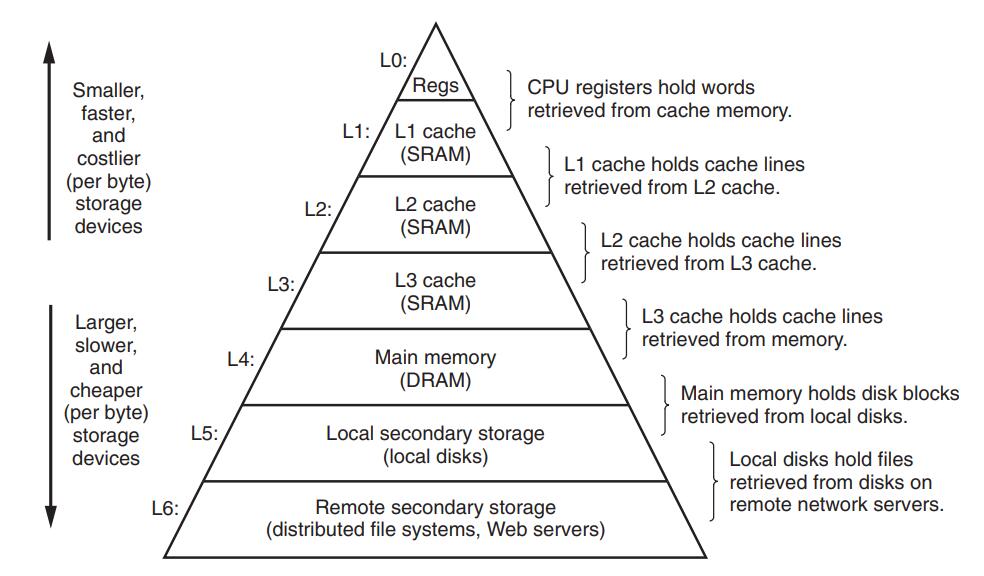
从塔尖到塔底,存储器件的时延由低到高,容量由小到大,如果将主频为3Ghz的CPU的一个时钟周期换算为人类习惯的1s的话,就会体会到CPU寄存器有多快,现代操作系统为什么要在I/O的时候进行上下文切换了:
| Computer Action | AVG Latency | Human Time |
|---|---|---|
| 3GhzCPU clock cycle | 0.3ns | 1s |
| Level 1 Cache access | 0.9ns | 3s |
| Level 2 Cache access | 2.8ns | 9s |
| Level 3 Cache access | 12.9ns | 43s |
| RAM access | 70-100ns | 3.5 to 5.5 min |
| NVMe SSD I/O | 7-150μs | 2 hrs to 2 days |
| Hard Disk I/O | 1-10ms | 11 days to 4 mos |
| Internet: SF to NYC | 40ms | 1.2 years |
| Internet: SF to Australia | 183ms | 6 years |
| OS virtualization reboot | 4s | 127 years |
| virtualization reboot | 40s | 1200 years |
| Physical system reboot | 90s | 3000 years |
如果光速降为原来的$1 \over 20000$会发生什么?我们进行一个不严谨的换算,假设所有组件本身工作延迟为0,所有的时延都是信号的传输花费,那么延时列表如下:
| Computer Action | AVG Latency | Human Time | Lower c(third cosmic velocity) |
|---|---|---|---|
| 3GhzCPU clock cycle | 0.3ns | 1s | 6μs |
| Level 1 Cache access | 0.9ns | 3s | 18μs |
| Level 2 Cache access | 2.8ns | 9s | 54μs |
| Level 3 Cache access | 12.9ns | 43s | 258μs |
| RAM access | 70-100ns | 3.5 to 5.5 min | 1.4ms to 2ms |
| NVMe SSD I/O | 7-150μs | 2 hrs to 2 days | 140ms to 3s |
| Hard Disk I/O | 1-10ms | 11 days to 4 mos | 20s to 3.4 min |
| Internet: SF to NYC | 40ms | 1.2 years | 14 min |
| Internet: SF to Australia | 183ms | 6 years | 1 hrs |
| OS virtualization reboot | 4s | 127 years | 1 days |
| virtualization reboot | 40s | 1200 years | 9 days |
| Physical system reboot | 90s | 3000 years | 21 days |
可以看到,光速降为原来的$1 \over 20000$之后,CPU访问内存要花费1~2ms,访问最快的NVMe设备要花140ms~3s,这意味着什么?从外界事件的光线到达你的视网膜,到这个事件产生的神经脉冲到达你的大脑皮层,这之间的时间大约为100ms,如果一个交互系统延迟超过140ms才对你的操作做出反应,那么你就会感知到“卡顿”,也就是说在低光速下,你可以“看到”磁盘正在读写。
再看看网络传输,从旧金山到纽约的网络延时由原来的40ms增加到了14分钟,也就是说ICMP包的往返需要14分钟,我们假设单程就是7分钟,那么一个TCP连接的建立需要三次握手,共需花费21分钟,理论上一个TCP数据包发送到接到ACK至少需要14分钟,可见在现有的计算机网络设计上,光速骤降会导致计算机根本无法工作,一次硬重启就要花费21天的时间。
《三体》中描述说没有计算机能在只有十几千米每秒的光速下运行,因此关一帆所在的银河系人类设计了可以在低光速下运行的神经元计算机,里面的所有芯片都是为低光速设计的,即便是经过专门的设计,在低光速下加载操作系统也要花12天的时间!
这个脑洞足以让你惊掉下巴,虽然它谈不上严谨,也不够科学(注:这里的不严谨仅仅指我的推导过程,并非指大刘的分析逻辑,实际上大刘仅仅描述了结果,并未作详细解释),但是如果你仅仅得出光速降低会影响电子计算机这么个简单的结论,那你就太小看了大刘的脑洞。
在《三体》的猜想中,光速也并非永恒不变,光速在宇宙创世之初是无限快的,不严谨的描述就是:光可以瞬间从宇宙的一端传输至另一端。不知道你想到了什么,反正我想到了量子纠缠,那么为什么现在的光速只有30万公里每秒呢?答案是黑暗森林法则。
读过《三体》的朋友都知道,高维打低维是非常轻松的一件事。宇宙最初是十维的,因为文明猜疑链的黑暗森林法则,不断的有不同维度的、同维度的文明互相攻击,使得宇宙不断的从高维向低维坍缩,光速也不断在下降(太阳系属于三维,光速为$3 \times 10^8 m/s$),小说中的太阳系就遭到了降维打击,从三维变到二维,太阳系成为了一副壮丽的画卷。
脑洞到此为止,我们还有个实际的问题要搞明白,那就是寄存器为什么会比内存快?除了距离上的优势之外,还有哪些内在的因素?
为什么寄存器速度要比内存快
在冯诺依曼计算机存储层次中,寄存器最快,容量最小,其次是内存,容量居中,硬盘最慢,容量最大;硬盘我们暂且不讨论,那么同样是晶体管存储设备,为什么寄存器的速度要比内存快呢?
距离
距离是一个因素,之前已经讨论过,越远离CPU,信号传输的距离越长,而电信号的传输速度受到光速的制约;而距离对于PC的影响就要比手机大,因为手机内存距离CPU更近,手机的CPU频率也通常比桌面电脑CPU低。
成本
成本是一个比较现实的原因,从register->L1->L2->L3->DRAM容量依次增大,以苹果的A7处理器为例,寄存器共有6000比特(32个64位的通用寄存器和32个128位的浮点寄存器等等)。但是目前的手机内存普遍拥有有640亿比特(8GB),因此,为这些为数不多的寄存器花费大量的成本去提高性能也是值得的,毕竟与内存比起来它太少了。
在设计上更加能突出这一点,寄存器和Cache相对于DRAM有更多更大的晶体管和更复杂的设计,且更加昂贵和耗电,并且一直有电;而DRAM的设计就相对简单,只有一个晶体管和一个很小的电容,也只有用到时才有电,所以更加便宜和省电。因此,DRAM上的cell排列非常稠密,而寄存器和SRAM就相对稀疏。这个道理同时适用于register->L1->L2->L3->DRAM这个链条,设计由复杂趋向简单,成本由高昂趋于节省,功耗由高变低。
可以想见,高性能、高成本、高耗电的设计就可以用在寄存器上,也只有低成本、低功耗的设计才可以堆出高容量的DRAM,一个简单的SRAM就需要至少6个晶体管,加上其他的元器件就有数十个晶体管,而DRAM只有一个晶体和一个电容。下面是SRAM和DRAM的cell的电路设计对比:
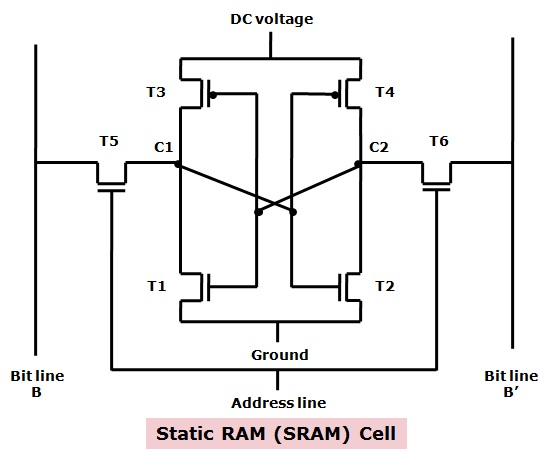
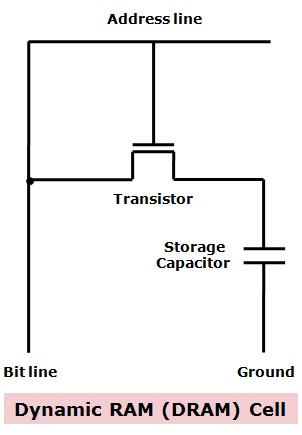
有人会问,如果我们不计成本,只做L1缓存,甚至做到跟内存一样大,不要内存了,会不会让CPU产生质的飞跃呢?
很遗憾,即便是现有的Cache层级下,也不是容量越大效果越好,命中率的增长到达一定程度时就趋于平缓,而如果真把L1做那么大容量,体积也会增大,就难以保证在一个时钟周期内访问到L1,那么cpu的频率就不能做那么高,这相当于自残,所以如何平衡缓存的层级和每个层级的大小一种trade-off艺术。这里有一篇文章有更详细的介绍:Cache为什么有那么多级?为什么一级比一级大?是不是Cache越大越好?
工作方式
寄存器的工作方式很简单,只有两步:
- 找到相关的位
- 读取这些位。
Cache的工作方式便又复杂了些,这里不讨论内存如何映射到Cache,也不考虑各种处理器架构的区别,只是简单大概的介绍一下Cache的运作流程,系统启动时,缓存内没有任何数据。之后,需要读取内存的数据便被以一定的大小(Cache Line)依次存入L3、L2、L1中,处理器读取指令或数据的过程如下:
- 将地址由高至低划分为四个部分:标签、索引、块内偏移、字节偏移。
- 用索引定位到相应的缓存块。
- 用标签尝试匹配该缓存块的对应标签值。如果存在这样的匹配,称为命中(Hit);否则称为未命中(Miss)。
- 如命中,用块内偏移将已定位缓存块内的特定数据段取出,送回处理器。
- 如未命中,先用此块地址(标签+索引)从内存读取数据并载入到当前缓存块,再用块内偏移将位于此块内的特定数据单元取出,送回处理器。
内存的工作方式就要复杂得多:
- 找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
- 将指针送往内存管理单元(MMU)。
- 由MMU将虚拟的内存地址翻译成实际的物理地址。
- 将物理地址送往内存控制器(memory controller)
- 由内存控制器找出该地址在哪一根内存插槽(bank)上。
- 确定数据在哪一个内存块(chunk)上,从该块读取数据。
- 数据先送回内存控制器
- 再送回CPU。
- 然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
以上就是为什么寄存器会比Cache和RAM快的大致原因,而缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
《三体》带来的其它思考
给岁月以文明,而不是给文明以岁月
如果说读完《三体》能让我记住些什么,那就是这句给岁月以文明,而不是给文明以岁月,这句话是出自帕斯卡的:给时光以生命,而不是给生命以时光。(To the time to life, rather than to life in time)。
两句话的都有相似的主旨,虽然表述的对象不同,看似略有深奥的话,其实阐明了一个很简单的道理:活在当下。不要被过去和未来迷惑,让活着的每一刻都有意义,不让生命虚度。如果时光蹉跎,那生命再长也不过是行尸走肉。
同样的道理,人类遭遇《三体》危机,全球都思考着如何延续我们的文明,而在这个过程中造成了太多的血与泪,不由得让人怀疑,文明若斯,当真还值得延续?
这不过就是王宝强老师的那句:有意义的事儿就是好好活,好好活就是做有意义的事儿。
所有那些有意义的事儿串联起来,就是人生。
是的,既往不恋,当下不杂,未来不迎。
参考文章:
- Why Registers Are Fast and RAM Is Slow
- Compute Performance – Distance of Data as a Measure of Latency
- Difference Between SRAM and DRAM
- 为什么寄存器比内存快?
- 为什么主流CPU的频率止步于4G?
- wiki:CPU缓存
- Cache为什么有那么多级?
- Cache是怎么组织和工作的?
- L1,L2,L3 Cache究竟在哪里?
- 为什么程序员需要关心顺序一致性(Sequential Consistency)而不是Cache一致性(Cache Coherence?)