在生产环境中运行 grpc 服务所面临的挑战
原文链接:Challenges of running gRPC services in production
实现服务间通信的方式有若干种,这通常涉及到 TCP/IP 协议族中的传输层。我们的应用程序经常依靠它来提供若干抽象和功能,例如负载均衡、重试和高可用性等。
然而,当我们在生产环境中运行服务时,我们会遇到更多网络相关的错误,这无疑超乎我们的想象。本文旨在阐释在使用 gRPC 进行服务间通信时,如何来缓解这些错误。
Why gRPC?
回溯至 2016 年 ,彼时 Incognia 的服务几乎都在使用 HTTP1.1 / JSON 技术栈进行通信。它在很长一段时间内运行良好,但随着公司的发展,一些高流量服务开始需要一种更高效的方式与内部客户端通信。
JSON API 的文档维护也很麻烦,因为它们没有与代码本身绑定,这意味着某人可以部署更改 API 的代码,却没有修改对应的文档。
为了寻找一个足够优秀的替代方案,我们调研了 grpc,它通过以下特性完美解决了性能问题以及上述模式定义问题:
- API 平面直接在 protobuf 文件中定义,其中每个方法都描述了自己的请求/响应类型
- 自动生成多语言的客户端和服务端代码
- 与 Protobuf 结合,使用 HTTP/2 协议,HTTP/2 和 Protobuf 都是二进制协议,这意味着请求/响应的有效载荷更加紧凑
- 而且,HTTP/2 使用持久化连接,无需像 HTTP/1.1 那样频繁地创建和销毁连接
但是,运行 grpc 服务也给我们带来很多挑战,主要归因于 HTTP/2 使用持久化连接这一事实。
生产环境使用 gRPC 的挑战
我们是 Kubernetes 的重度用户,因此我们的 grpc 服务全部运行在由 Amazon EKS 提供的 Kubernetes 集群之上。
确保在 server 上负载均衡是面临的挑战之一。因为服务的数量是动态变化的,这是由(k8s的)自动伸缩功能决定的,所以客户端必须有能力识别新的 server,并剔除不可用的连接。与此同时还要保证所有的请求以某种负载均衡策略均衡地分布到这些 server 上。
负载均衡
对此, The gRPC blog 阐述了几种解决方案,大致可分为代理负载均衡(或服务端负载均衡)和客户端负载均衡。在下面的章节中,我将按时间线来讲述我们的实现方式。
方式 1: 使用 Linkerd 1.x 作为负载均衡代理
如图1所示,我们实现的第一种方式是使用一个名为 Linkerd 1.x 的代理负载均衡器。这种方式在一段时间内工作的很好,它在服务端解决了负载均衡问题,但没解决从客户端到代理的负载均衡问题,这意味某些 Linkerd 实例要处理比其它实例更多的请求。
这种不均衡后来被证实是有问题的,过载的实例可能会增加太多延迟,甚至有时会耗尽内存,变的越来越难以维护。
除此之外,我们在 Kubernetes 集群中将 Linkerd 部署为守护进程,这意味着 Linkerd pod 在集群中的每个工作节点上运行。因此,这种解决方案被证明会增加相当大的开销(因为它需要额外的网络跳跃),并且还会消耗大量资源。
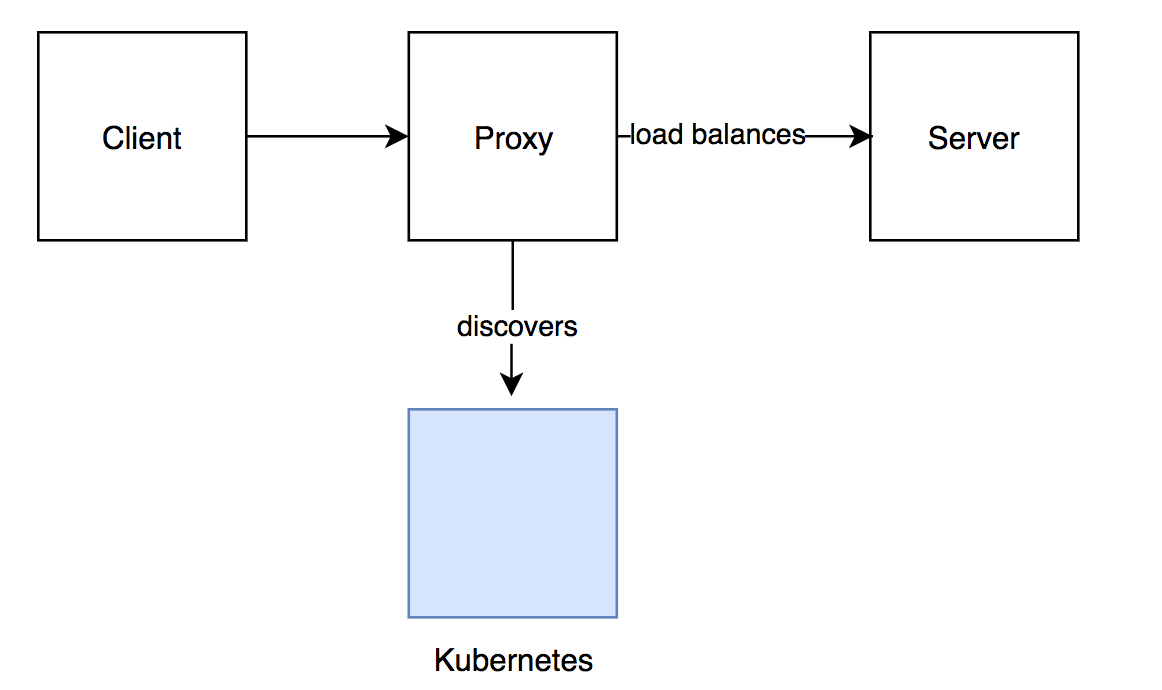
Figure 1: Proxy load balancer approach
方式 2: 胖 gRPC 客户端
将处理负载均衡的职责放到客户端代码,我们试图淘汰代理层,以此来尝试解决第一种方式带来的问题。
通过结合使用 grpc-go 的naming.NewDNSResolverWithFreq(time.Duration) 和 Kubernetes 的 headless services(处理 server pod的发现),我们在客户端处理负载均衡。使用这种方式,客户端需要每隔几秒钟轮询目标 service 的 DNS,以此来刷新可供连接的主机池。
与使用代理层相比,此处客户端与服务的pod直连,降低了调用延迟。下图展示了该方式所涉及到的组件。
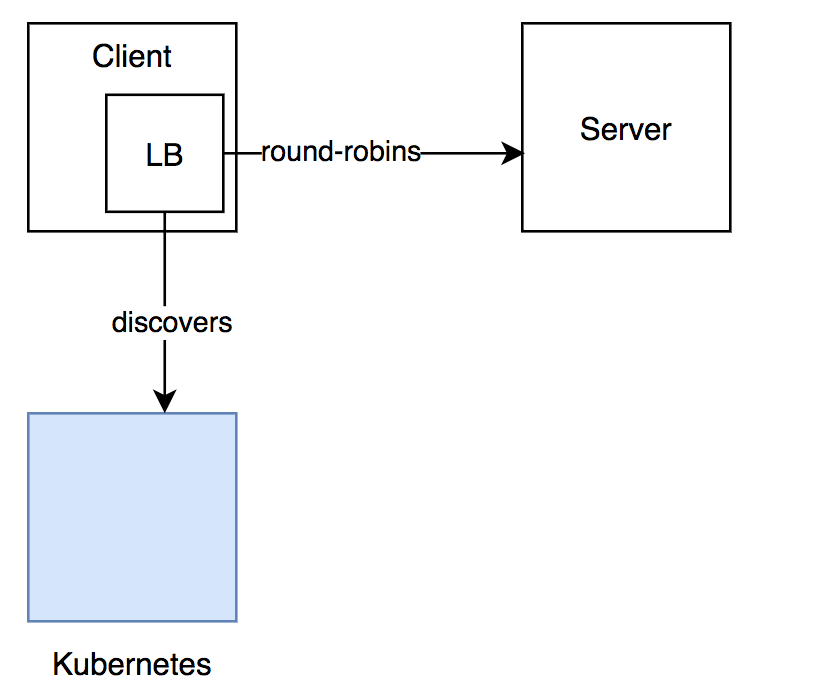
Figure 2: Thick client approach
然而,Go gRPC 实现不再支持使用 DNS 进行动态服务发现,而是推荐使用 xDS 等其他协议。而且,在其他语言中,DNS 动态服务发现从未被实现过。
我们知道,尽管这种方式带来了稳定和高性能的通信,但是由于 gRPC 实现的多样化,依赖客户端实现负载均衡终归是脆弱和难以维护的。这一点也同样适用于其它功能,比如限流和认证。
当尝试过这些不同的方法之后,我们清楚的认识到,我们需要一种通用、低成本、语言无关的方式来实现服务发现和负载均衡。
方式 3: 使用 Envoy 边车代理
经过一番调研,我们选择使用边车模式——在客户端 pod 中增加一个容器,由它来负责服务发现,负载均衡,以及一些针对连接的监测功能。从性能和部署简便性出发,我们选择了 Envoy。
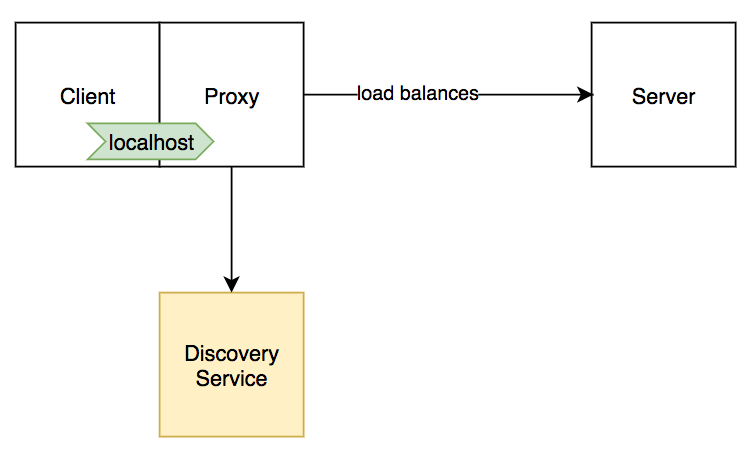
Figure 3: Sidecar proxy approach
在这种方式下,客户端容器与 Envoy 边车连接,由边车负责维护和目标 service 的连接。
采用这种方式,我们终于得偿所愿:
- 与Linkerd 1.x相比,Envoy的开销很小,延迟低。
- 对客户端代码没有侵入性
- 可观测性,因为 Envoy 暴露了兼容 Prometheus 格式的 metrics
- 丰富了网络层,支持认证和限流等特性
服务发现与优雅关闭
正确配置了负载均衡之后,我们仍然需要一种方法来让 Envoy 发现新的目标并更新其主机池。
Envoy 中的服务发现有几个选项,如 DNS、EDS(基于 xDS )。因为简单和熟悉的缘故,我们选择了 DNS。
使用 DNS 作为服务发现机制有个潜在的复杂性,即传播需要一定的时间,因此,在一个正在终止的后端服务真正停止接受连接之前,我们需要为 gRPC 客户端留有更新主机列表的余地。因为有一个 TLL 时间与 DNS 记录相关联,也就是说 Envoy 会在这段时间内缓存主机列表,所以使用 DNS 时,优雅关闭流程需要一点技巧
下图展示了一个基本流程,它以一个失败的请求结束:
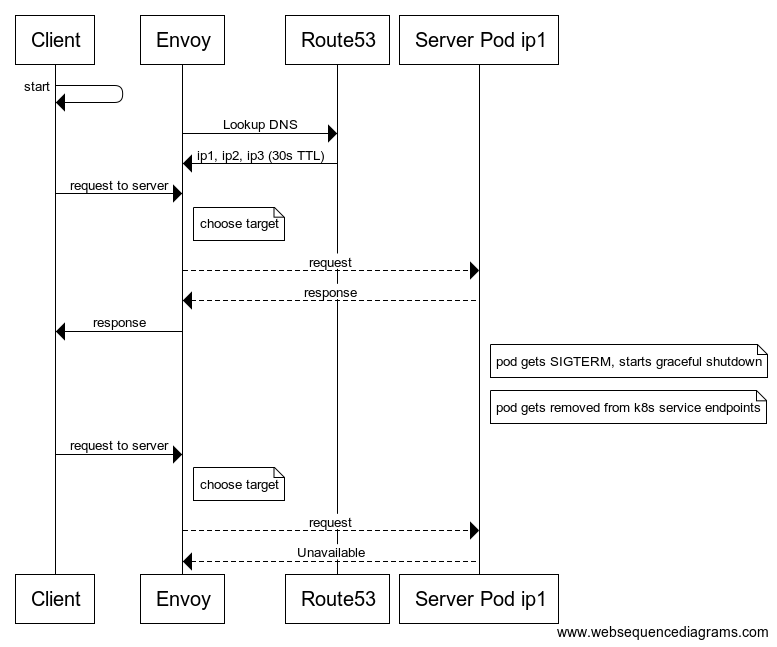
Figure 4: Terminating host makes request fail due to DNS caching
在这个场景中,因为服务端 pod 不再可用,但 Envoy 缓存依然持有其 IP,所以第二次客户端请求以失败告终。
要解决这个问题,我们有必要看一下 Kubernetes 是如何销毁 pod 的,这篇文章对此有详细的论述。它包含两个同时进行的步骤:在 Kubernetes service endpoints 中移除 pod(在我们的案例中,同时也会移除 DNS 记录列表中该 pod 的 IP) 和 向容器发送 TERM 信号,启动优雅关闭。
有鉴于此,我们使用 Kubernetes 的 pre-stop 钩子来阻止 TERM 信号的立即发送:
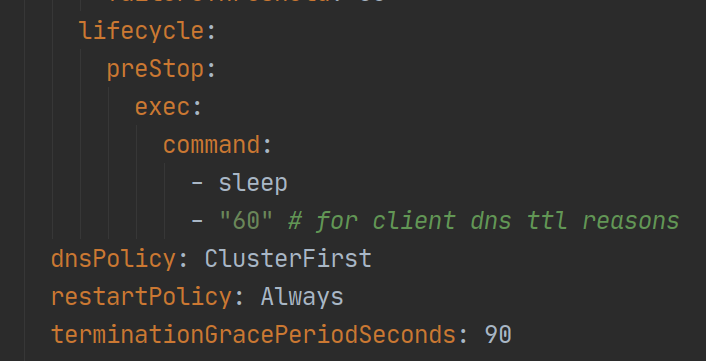
Figure 5: preStop hook
配置好 preStop 钩子之后,我们的流程就变成下面这样:

Figure 6: successful server pod shutdown flow
通过这种解决方式,我们为 Envoy 的 DNS 缓存留出足够的时间,使其过期并且重新刷新,从而剔除已经死亡的 pod IP。
未来改进
尽管 Envoy 为我们带来了性能提升和整体的简洁,但是基于 DNS 的服务发现依旧不是很理想。因为它是基于轮询的,在 TTL 过期之后,由客户端负责刷新主机池,所以不够健壮。
一种更加稳健的方式是使用 Envoy 的 EDS,它拓展了一些功能,诸如金丝雀发布和更加精密的负载均衡策略等,因此是一种更加灵活的方案,不过我们仍然需要一些时间来评估这种方案并在生产环境上进行验证。