Stack 顿悟三部曲(1):从CPU的视角说起
为什么会有这篇文章
我在啃 rust 圣经英文原版时,所有权那一章就反复看了几遍,作者简要介绍了 stack 和 heap 的使用区别,这引起了我以前从未有过的一个思考:stack 上的数据是如何被引用的?
All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change must be stored on the heap instead. The heap is less organized: when you put data on the heap, you request a certain amount of space. The memory allocator finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. This process is called allocating on the heap and is sometimes abbreviated as just allocating. Pushing values onto the stack is not considered allocating. Because the pointer is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer.
简要翻译一下:
所有存储在 stack 上的数据,其 size 必须是固定不变且在编译期已知的。如果数据的大小不能在编译期决定,亦或是在运行时其大小会发生改变,那么这样的数据就应该放在 heap 上。heap 是一个组织比较松散的区域:当你想把数据放置在 heap 上时,你必须先请求一块存储空间才行。专门的内存分配器会去寻找一块空余的、大小足够的空间,并将其标记为已用,之后返回指向这块区域的指针。这个过程就是在 heap 上分配内存,有时会简称为 allocating。将数据推入 stack(入栈)不会被叫做 allocating(因为 stack 的空间在线程创建时就已分配并初始化)。因为指针类型的大小固定且已知,因此你可以将指针入栈,但是当你想使用数据本身时,你必须追踪跟指针(解引用)。
正如我开篇所言,让我心头一震的并不是这些随处可见的关于 stack 和 heap 区别的论述,而是我从未深入思考过的一个问题:stack 上的数据是如何被引用的?
以前对堆栈的认知就是 PUSH 入栈,使用时 POP 出栈,这大概源于对数据结构课程中 stack 数据结构认知的根深蒂固。所以当我读到 stack 上的数据都是固定大小且日后不会改变、不会增长时,才后知后觉:为何以前没有去想这个细节呢?
CPU 把一块内存当做 stack 使用时,参数和局变量入栈之后仍会被使用,并不像我们数据结构课程中的 stack,只在用的时候才去 POP。CPU中的 stack 机制只有在函数结束时才释放该函数的栈帧,那栈上的数据在没有弹出时是如何被引用到的呢?
其实,这个问题很好回答,从编译之后的汇编指令上看,是使用的相对定位。大致是利用 ebp(帧指针寄存器或基指针寄存器) 和 esp(栈顶指针寄存器)中的一个或两个来达到定位的目的。
以此为由,我深入调查并思考了很多关于 stack 的内容,主要涉及有如下几点:
- CPU 的 stack 机制是如何工作的?
- 函数调用是如何利用 stack 的?
- 进、线程在创建时 stack 如何分配,虚拟内存中的 stack 区域是线程共有的么?
- 从指令级别理解 Go 语言的 goroutine 是如何调度和分配 stack 的?
因此,我将分几篇文章分别对这些内容进行叙述,虽然我是围绕着 stack 来进行思考的,但文章内容也会谈及很多 stack 之外的东西,比如虚拟内存、线程调度,上下文切换等等。
友情提醒一下,因个人能力有限,我并不会去深抠相关的源码细节,我目前所寻求的信息,意在建立计算机系统的世界观与 Go 语言的世界观,是在陷入具体细节之前为自己提供一个大致的轮廓,让自己对计算机运行的脉络有一个关键性的认识。
这是这个系列的第一篇,本篇我主要从 CPU 的视角来带大家一起复习一下理论知识,看一看 CPU 是如何执行指令,如何将一块内存当做 stack 来使用。
因 stack 一般会被翻译为堆栈,因此后续文章内容能使用英文原文 stack 的地方,我会尽量使用 stack,需要中文的地方我会使用堆栈一词,如果堆栈一词放上去比较突兀的话,我会直接使用栈这个字。所以,无论是 stack、堆栈、栈,我希望阅读文章的你能铭记我指的就是 stack!
内存和它里面的东西
众所周知,计算机内部用二进制表示一切。从应用的角度而言,内存中存放的信息大致可分为指令和数据,然而在内存看来,这些信息并没有什么区别。一段信息是指令还是数据,全看 CPU 如何使用它们。CPU 在工作的时候,把有的信息看作指令,有的信息看作数据,为同样的信息赋予了不同的意义。那这是如何做到的呢?我们以 8086 CPU 为例来简要说明。
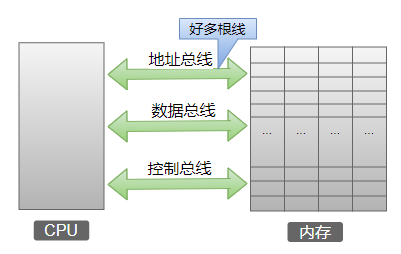
如图所示,CPU 与内存之间有三类总线,分别为地址总线、控制总线和数据总线。数据的读、写就是靠这三类总线配合完成的。我们来看一下 CPU 从内存 3 号单元中读取数据的过程。
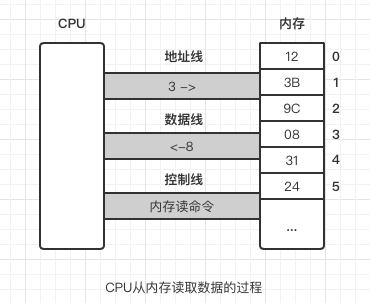
- CPU 通过地址线将地址信息 3 发出。
- CPU 通过控制线发出内存读命令,选中存储器芯片,并通知它,将要从中读取数据。
- 存储器将 3 号单元中的数据 08 通过数据线送入 CPU。
写操作与读操作的步骤相似。如向 3 号单元写入数据 26 :
- CPU 通过地址线将地址信息 3 发出。
- CPU 通过控制线发出内存写命令,选中存储器芯片,并通知它,要向其中写入数据。
- CPU 通过数据线将数据 26 送入内存的 3 号单元中。
当然,现实当中地址并不总是像 3 这样简单,我们可以把每个字节当成一个小盒子,内存就是一堆小盒子的线性排列,如果从第一个盒子开始给他们都编上号,那么每个盒子的号码就是对应内存空间的地址,也就是说在计算机主存当中,每一个字节都有它的地址。你可以把内存想象成下面这样(图中每一行代表前文论述的盒子):
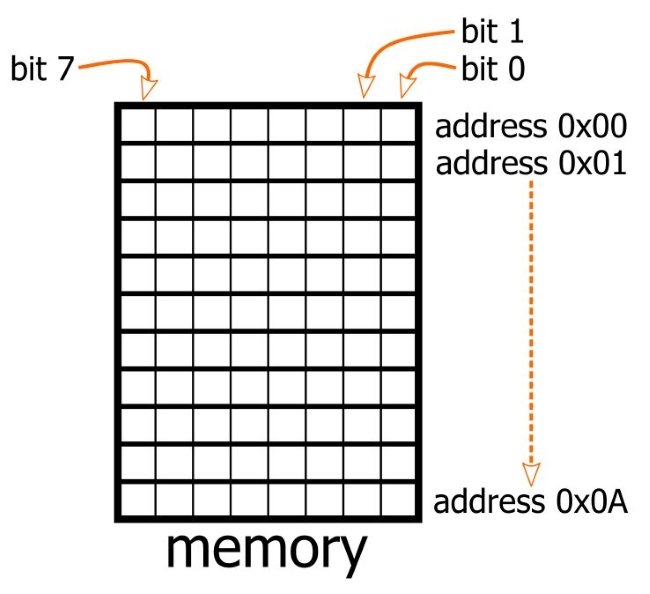
有一点很明显,就是 CPU 能寻址的空间大小是受地址总线导线数量限制的。在 8086 中,其地址总线是 20 根,也就是它能用 20 个 bit 来表示一个地址,算来它最大的寻址空间就是 2 的 20 次方,即 1M 大小。
但问题是,在 8086 内部用于倒腾数据的寄存器都是 16 位的, 16 位最大寻址空间只有 64K,那如何用 16 位的寄存器组合成 20 位的地址呢?8086 的处理方法是使用 2 个 16 位地址,通过一个地址加法器的运算来得出 20 位的物理地址。运算的逻辑就是一个 16 位的段地址左移 4 位再加上偏移地址:物理地址=段地址*16 + 偏移地址。此处不再举例描述细节,有兴趣的可以参考任意讲解段地址和偏移地址的资料,此处只需要记住,8086 CPU 下读写内存时,都需要一个段地址的辅助,这个段地址就放在段寄存器中。
8086 有 4 个段寄存器,CS、DS、SS、ES,分别是代码段寄存器、数据段寄存器、堆栈段寄存器以及扩展段寄存器,本文主要涉及代码段和堆栈段,那么先从 CS 代码段寄存器说起吧。
CPU 是如何执行指令的
我们都知道,CPU 的任务说起来很简单,就是从程序计数器(PC)中拿到地址,将该地址处的数据看作指令并读入指令缓冲器,之后指令缓冲器中的指令便会进入执行控制器执行。当PC中的地址所指向的数据被读取之后,PC中的值会自动增加为下一条指令的地址,接下来就会重复之前的内容。
但在 8086 中, PC 是由两个寄存器来共同表示的,那就是 CS 和 IP,CS是代码段寄存器,IP是指令指针寄存器。任意时刻,设 CS 中的内容为 M,IP 中的内容为 N,8086 CPU 将从内存单元 M*16 + N 开始,读取一条指令并执行。换句话说,任意时刻,CPU 将 CS:IP 指向的内容当作指令执行。
下图为CPU执行一条指令的过程拆解,其中 CS 寄存器的值为 2000H,IP 寄存器的值为 0000H,内存 20000H~20009H 单元存放着可执行的机器码。

CPU 会将CS、IP中的内容送入加法器得出物理地址 2000H*16+0000H(20000H),之后 20000H 送入地址总线,位于 20000H 单元处的指令 B8 23 01 会被读入指令缓冲器并增加 IP 的值(增加的值为本次读取的指令的长度,此处为 3 个字节),接下来就会进入执行阶段。因为此时 CS:IP 中的内容已经是下一条指令的地址(mov bx,0003H),CPU 便进入下一次循环,如此往复。
上图执行完第一条指令之后 AX 寄存器的内容已变为 0123H。
更详细的内容,请参考王爽《汇编语言》2.10 章节。在这里描述 CPU 指令的执行过程是为了在后面的文章中方便描述线程调度,其实线程切换的原理很简单,就是修改 CS:IP 的值让 CPU 去执行另外一个地方的指令,而这个地方就是新线程的函数指令入口。
CPU 提供的stack机制
如今的 CPU 都有堆栈的设计,提供相关的指令来以堆栈的方式访问内存空间。这意味着在编程的时候,可以将一段内存当作堆栈来使用。CPU 提供了以堆栈方式访问内存的机制,操作系统用这种机制实现了函数调用。
CPU 提供了入栈和出栈的指令,最基本的就是 PUSH 和 POP 指令,比如 PUSH AX 表示将寄存器AX中的内容送入堆栈,POP AX 就是将栈顶的元素送入 AX 寄存器,并移动栈顶。那么,CPU 是如何知道一段内存被当做栈来用的呢?答案是 SS 堆栈寄存器和 SP 栈顶寄存器。
任意时刻,SS:SP 指向栈顶元素,PUSH 和 POP 指令执行的时候,CPU 从 SS 和 SP 处获取栈顶地址,并在执行过程中自动加减SP寄存器中的值,是的 SS:SP 永远指向栈顶。
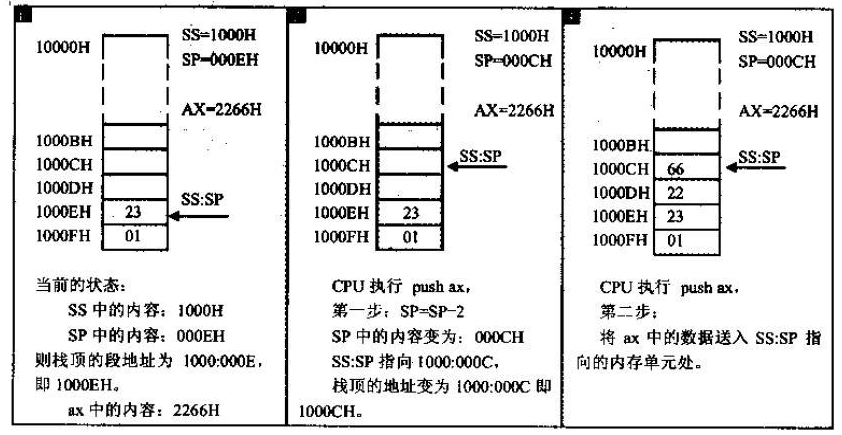
PUSH AX 的指令,由以下两步完成。
- SP=SP-2, SS:SP 指向当前栈顶的下方的单元,以当前栈顶下方的单元为新的栈顶;
- 将 AX 中的内容送入 SS:SP 指向的内存单元处,SS:SP 此时指向新的栈顶。
下图描述了 8086CPU 对 PUSH 指令的执行过程。
POP AX 的指令更好相反,由以下两步完成。
- 将 SS:SP 指向的内存单元的数据送入 AX 中;
- SP=SP+2,SS:SP 指向当前栈顶上方的单元,以当前栈顶上方的单元为新的栈顶。
下图描述了 8086CPU 对 POP 指令的执行过程。
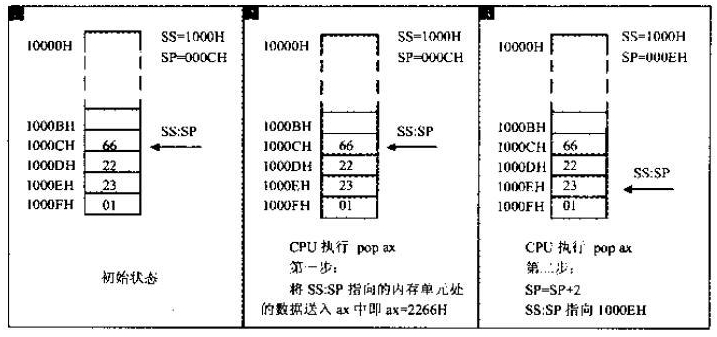
注意,栈由高地址向低地址增长,这两幅图相当于倒置的状态。
从中我们可以得出一点结论,将一段内存当做栈,仅仅是我们在编程时的一种安排,CPU 并不在乎这段内存在哪,也不在乎内存放的到底是指令还是数据。换句话说,内存并无区别,区别只在 CPU 如何看待它们。我们会在后面讲述线程或协程堆栈使用的内存,只要将一块内存的地址设置为 SS:SP 那么这段内存就会在你使用 PUSH、POP 的时候作为堆栈来用。
我们在学习虚拟内存的时候(下一章会简单介绍虚拟内存)容易被其划分的各种区域迷惑,某段区域用于 stack ,某块区域用于 heap。很容易让人产生这些区域都有各自特殊之处的错觉。加上一些盛行理论的影响,让问题更加扑朔迷离,常见的如:数据放在 stack 上要比 heap 上快,因为入栈只需要一条指令,而在 heap 上申请内存则十分耗时,简言之使用 stack 廉价,使用 heap 昂贵。
其实这种说法不严谨,除了会迷惑初学者之外,别无益处。试想一下,stack 与 heap 有什么区别?区别只在 stack 已经分配,且使用方式不同;heap 只在需要的时候去分配,耗时的是分配的过程,而不是访问的过程;CPU 访问 stack 中的内容和 heap 中内容的方式并无二致,都是使用的标准的内存寻址方式(注:stack 相对 heap 对 cpu cache 更加友好,从程序运行的空间局部性来讲,CPU Cache 命中率会高一些)。
CPU 把主存当做什么用,完全看我们的规划以及使用的指令,比如设置了代码段之后,代码段部分保存的数据就被 CPU 看做指令,当设置了 DS 数据段之后,使用 mov 等操作时 CPU 即将内存中的内容视作数据,当设置了 SS 段之后,使用 PUSH 和 POP 时 CPU 就把那块内存当做堆栈来使用。
CPU 对主存的一视同仁可以在另外一个现象上得到印证,如果使用现代的编译器编译为汇编文件,你会发现很多理论上应该使用 PUSH 的地方却使用了 MOV,这是因为编译器做了优化,PUSH 隐含了两个操作,一个是移动数据,一个是维护堆栈指针。当操作较多时,指针维护较为频繁,为性能计转而使用 mov 来达到目的,并在必要的时候手动维护栈顶指针。这间接说明了堆栈段的内存并无甚特别之处,其特别只在于使用的方式(入栈和出栈的操作同样可以用 mov 和数据段来配合达到)。
现代 CPU 中的段
8086 采用了段的方式来增加寻址空间,使得最大寻址空间达到 1M,但它并没有对内存访问做寻址检查,也不支持现在广为流行的虚拟内存(虚拟内存的内容,我们在下一篇探讨函数栈帧的时候详述)。这意味着 8086 没有内存保护功能,且此种寻址方式无法对多道程序提供支持,这种使用段直接生成物理地址的模式被称为实模式。
Intel 在 8086 的继任者身上实现了保护模式,对虚拟内存提供了硬件上的支持。保护模式依然使用段来加强寻址,且方案设计非常复杂精巧,这种方式人们将其称为 IA-32 保护模式,但是此种模式应用甚少,进入 64 bit 时代后,CPU 仅仅作为兼容需要予以保留。
AMD 是第一个吃螃蟹的,首次从架构上将 CPU 的虚拟寻址空间带入 64 bit 模式(可参考 wiki x86-64 的描述,内容还算详实),虽然在架构上已支持 64 bit,但是 AMD 在处理器的实现上实际仅支持 48 bit 的虚拟寻址空间,以及 40 bit 的物理寻址空间;对应的 Intel i7 实现为 48 bit 虚拟寻址空间 和 52 bit 的物理寻址空间。这主要是出于经济上的考虑,并在架构设计上做了功夫,使得日后可以很容易扩展到真正的 64 位。不要小看 48 bit 的寻址空间,这意味着当前实现的 CPU 最大支持 256 TB 的内存寻址,然而当下几乎没有场景会达到这一临界点。更详细的内容可以参考这两篇讨论:
- why virtual address are 48 bits not 64 bits?
- Why do x86-64 systems have only a 48 bit virtual address space?
在这里有必要提一下 64 bit 模式下与寻址相关的Canonical form addresses,AMD 标准规定:虚拟地址的高 16 位 也就是从 48 位到 63 位必须拷贝第 47 位的值。Canonical form addresses 规定有效的地址空间为 0 到 00007FFF'FFFFFFFF,以及 FFFF8000'00000000 到 FFFFFFFF'FFFFFFFF,可以看下图形象的表示:
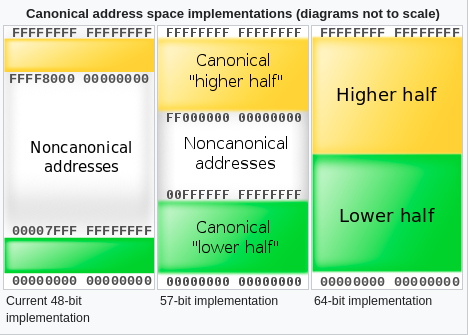
Canonical form addresses 将空间分为上下两部分,可见 48 bit 寻址空间下中间有很大的的空洞。Linux 将上部 128TB 用于内核空间,下部 128TB 用于用户空间,即可以寻址 256 TB 的内存空间。无论如何地址已经是 64 bit 的了,不再需要借助段寄存器。
如果上面这些内容难以理解,那么你只需要明晰一点:在汇编语言中,修改指令寄存器和栈顶寄存器的时候,只需设置一个寄存器即可,已不再需要段的参与!
程序调度、堆栈初始化无非就是修改 CPU 对应的寄存器,之后就可以控制进程执行流的走向,以及进程用到的 stack。这一点也是本系列文章围绕的核心所在,故不厌其烦的简述其原理于此。
参考文献
- 汇编语言
- 深入理解计算机系统
- 程序员的自我修养
- 计算机体系结构:量化研究方法
- why virtual address are 48 bits not 64 bits?
- Why do x86-64 systems have only a 48 bit virtual address space?
- x86-64
- Address canonical form and pointer arithmetic
- Why 64 bit mode ( Long mode ) doesn't use segment registers?
- How are the segment registers (fs, gs, cs, ss, ds, es) used in Linux?